
An Interest In:
Web News this Week
- April 16, 2024
- April 15, 2024
- April 14, 2024
- April 13, 2024
- April 12, 2024
- April 11, 2024
- April 10, 2024
Some of Our Sources
- Slashdot
- Joshua Blankenship
- Six Revisions
- Fuel Your Creativity
- Crazy Leaf Design
- Line 25
- Spyre Studios
- Web Resource Source
- Android Dissected
- Daily Now
Help Webnuz
Referal links:
What's New in API7 Enterprise 3.2.9: Upgraded Health Check Configuration
Introduction to New Health Check Features
In version 3.2.9 of API7 Enterprise, the configuration interaction experience for health checks has been comprehensively optimized.
Those previously scattered configuration items have been logically aggregated, such as probe settings, and criteria for determining healthy and unhealthy nodes, making them more structured.
Some abstract configuration item names have been transformed into more intuitive and semantic expressions, allowing users to directly input relevant parameters through fill-in-the-blank format, thus gaining a clearer understanding of the practical effects of configurations.
During the configuration of upstream nodes and health check processes, more prompt messages have been added to assist users in better understanding the inherent connection between upstream nodes and health checks, thereby facilitating easier completion of configuration tasks.

Basic Concepts of Health Checks
In API7 Enterprise, the priority setting of upstream nodes is closely linked to the mechanisms of load balancing and health checks. When users configure multiple upstream nodes with different priorities for the gateway, the gateway prioritizes the highest-priority nodes during load balancing. This means that as long as the highest-priority nodes remain healthy, the gateway will continue to route traffic to these nodes.
Only when all highest-priority nodes are deemed unavailable due to failed health checks will the gateway automatically degrade, redirecting traffic to the next highest-priority upstream nodes. This design ensures efficient utilization of traffic and high system availability.
It's worth noting that if multiple priority levels of upstream nodes are configured in the service, but the health check function is disabled, then all client requests will always be routed to the highest-priority nodes, regardless of their actual health status.
Configuration Methods for Health Checks
Probe Configuration
A probe is used to detect the liveliness and service status of upstream nodes. In APISIX, the probe is like an "inspector" that regularly knocks on the door to check if the upstream service is functioning properly. If it finds any issues or if the service is "unavailable," it informs APISIX: "This service is currently unavailable, so hold off on sending requests here." This process of "knocking on the door" is performed through probes.
The probe mainly includes the following configuration items:

Probe Scheme: The protocol type used by the health check probe, supporting TCP, HTTP, and HTTPS.
Concurrency: This configuration item allows you to set the number of concurrent health check requests. In other words, this is the number of times you want to "knock on the door" simultaneously to check the responsiveness of upstream services. By adjusting the concurrency, you can simulate possible concurrent requests in real-world scenarios, thereby better evaluating the performance and stability of upstream services.
Host: Specifies the host address of the upstream server to be checked. This is like determining which house to "knock on the door" of.
Port: The port number of the upstream service. It's like knowing which door to knock on during the probe.
Path: If you're using an HTTP probe, this configuration item specifies the URL path you want to access. It's like telling the probe to check the exact room once inside.
Criteria for Determining Healthy Nodes

Regarding the determination of healthy nodes, the system regularly checks nodes previously marked as unhealthy at the interval set by the user (in seconds) to ensure timely detection and proper handling of any transient node anomalies.
If the probe uses the TCP protocol, the node is considered healthy after the probe successfully connects to the upstream node the number of times set by the user.
If the probe uses the HTTP/HTTPS protocol, the system considers the node healthy only when it continuously receives probe requests with specified status codes (such as 200 and 302) from the node. This means that the node is considered to be working properly only when it continuously returns these specific status codes.
Criteria for Determining Unhealthy Nodes
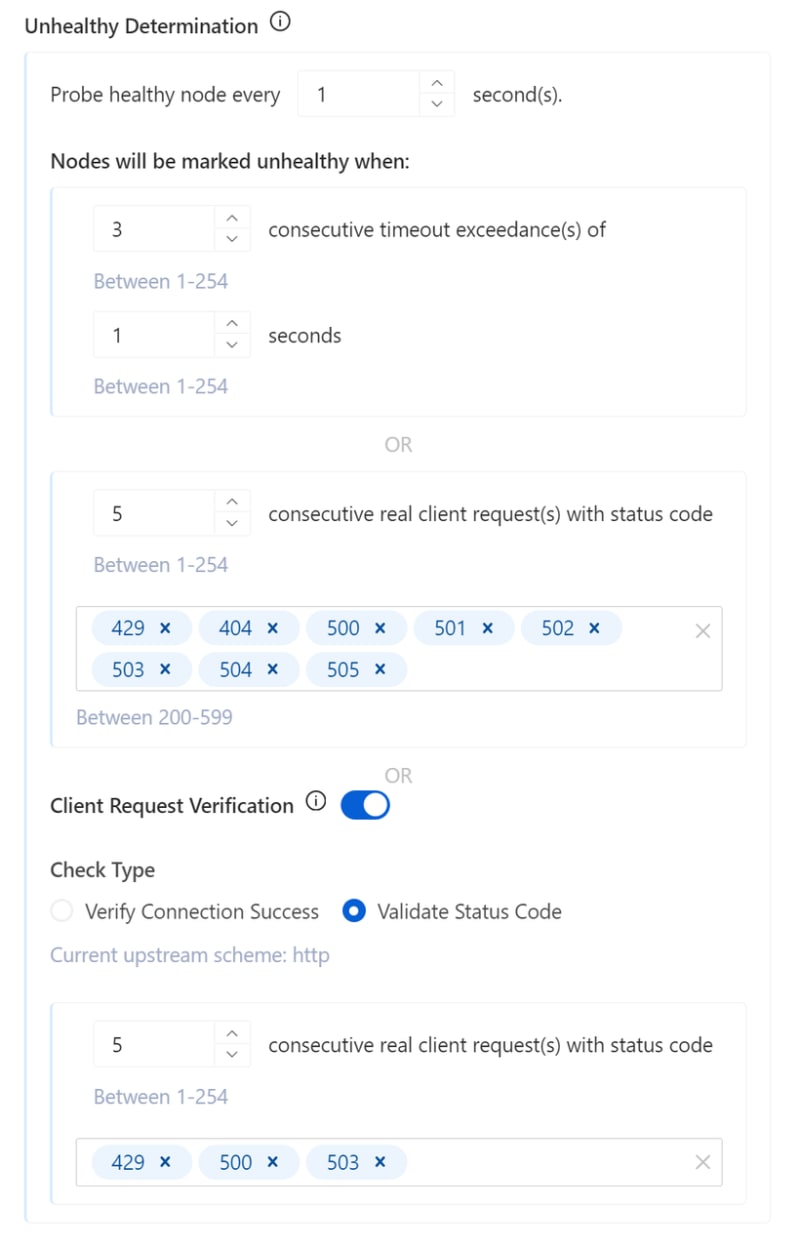
Regarding the determination of unhealthy nodes, the configuration method is similar to determining healthy nodes. The system regularly checks nodes marked as healthy at the interval set by the user. Once these nodes meet the preset unhealthy conditions, they are reclassified as unhealthy.
Slightly different from determining healthy nodes, an additional configuration item, client request verification, is added during the determination process of unhealthy nodes. When this feature is enabled, the gateway not only relies on the probe's inspection results but also deeply observes and analyzes requests from clients and the actual responses from upstream services. Based on these data and user-defined judgment criteria, the gateway can more accurately evaluate the running status of upstream services.
Best Practices for Health Checks
Selecting the Appropriate Probe Type
TCP Probe: Suitable for scenarios that only require confirmation of whether the service port is open and accessible. For example, a database service may only need a TCP probe to confirm port opening.
HTTP/HTTPS Probe: More suitable for scenarios that require verification that not only the network connection is normal but also that the service can correctly handle requests. For example, for a web server or API service, we need to ensure that it can not only receive connections but also return correct pages or data.
Reasonable Configuration Parameters for Health Checks
When configuring health checks, pay attention to several key parameters:
- Check Interval: It should not be too short to avoid unnecessary overhead or too long to avoid slow response in case of issues. For example, for a high-traffic e-commerce website, checking every 30 seconds is a relatively reasonable choice. This interval neither excessively consumes system resources nor delays the detection and handling of issues on the website.
Of course, this interval is not absolute, and adjustments need to be made based on the actual situation of the website. For instance, if the website experiences significant fluctuations in traffic or experiences surges in traffic during specific periods (such as during promotional campaigns), it may be necessary to adjust the checking interval to accommodate these changes.
Timeout: The time the probe waits for a service response. If the service does not respond within this time, the probe considers the service unhealthy. This value should be set according to the actual response time of the service.
Retry Count: The number of times the probe attempts to connect before determining the service is unhealthy. This value should be moderate to avoid misjudgments.
Adjusting Strategies Based on Business
Health check strategies should be adjusted based on the actual business situation. If a service typically experiences high loads during specific time periods, health check intervals can be increased or retry counts reduced during these periods to avoid additional pressure on the service.
Enabling Client Request Verification as Appropriate
Client request verification can effectively determine service status based on actual business requests, especially for identifying issues closely related to business logic. However, it may not be suitable for every business scenario.
Low-Traffic Services: If service traffic is low, passive health checks based on client requests may not provide enough data points to accurately assess service status. In such cases, relying on active probe checks may be more reliable.
Performance Considerations in High-Concurrency Environments: Passive health checks require monitoring and processing of every client request, which may increase additional performance overhead in high-concurrency environments. If performance is a primary concern and the service has been adequately monitored through other means, passive health checks may be considered for closure.
Existence of Other Monitoring Systems: If mature monitoring systems have already been deployed in the enterprise, capable of capturing and analyzing service status in real-time, passive health checks may not be necessary to avoid data redundancy and additional complexity.
Conclusion
Health checks are a crucial aspect of ensuring the high availability of API gateways. In version 3.2.9 of API7 Enterprise, we have comprehensively optimized the interactive configuration of health checks, simplifying operations and enhancing user experience.
By properly configuring probes, setting criteria for healthy and unhealthy nodes, and adjusting strategies based on actual business needs, users can more effectively monitor the status of upstream services, ensuring that traffic is always routed to healthy nodes. This not only enhances the stability and availability of the system but also ensures that user requests receive timely and accurate responses.
Original Link: https://dev.to/api7/whats-new-in-api7-enterprise-329-upgraded-health-check-configuration-2aad
Dev To
More About this Source Visit Dev To