
An Interest In:
Web News this Week
- March 28, 2024
- March 27, 2024
- March 26, 2024
- March 25, 2024
- March 24, 2024
- March 23, 2024
- March 22, 2024
Some of Our Sources
- Mashable
- Smashing Magazine
- TutsPlus - Design
- Fuel Your Creativity
- FanExtra - PSD
- CSS Globe
- Stylized Web
- Willems Lab
- Hashedout
- The Verge
Help Webnuz
Referal links:
Afraid of outgrowing AWS Rekognition? Try YOLO in Lambda.
When it comes to machine learning, the cloud is a straightforward choice due to its robust computing power. Cloud can also provide a variety of services that can speed up your efforts significantly. For the purpose of this article, we will use computer vision as an example of a machine learning use case and since my cloud of choice is AWS, the most relevant service is AWS Rekognition. It offers an API where you can send a picture and it will respond with a list of keywords that have been identified there. This is perfect for when you are building a PoC of your new product, as these ready-made ML services can bring your idea to life in a cheap and fast manner.
However, theres a catch. As your product gains traction and real-world customers, you might find yourself bumping against the limits of AWS Rekognition. Suddenly, what was once a smooth ride can become a bottleneck, both in terms of accuracy and cost. Fear not! Switching quite early to a more flexible solution can save you a lot of headaches - like running a pre-trained model in an AWS Lambda, harnessing the same serverless properties that AWS Rekognition provides.
In this article, well explore the limitations of AWS Rekognition, dive into the world of YOLO, and guide you through implementing this more adaptable solution. Plus, well look at a cost comparison to help you make an informed decision.
AWS Rekognition
AWS Rekognition is a great choice for many types of real-world projects or just for testing an idea on your images. The issue eventually comes with its cost, unfortunately, which we will see later in a specific example. Dont get me wrong, Rekognition is a great service and I love to use it for its simplicity and reliable performance on quite a few projects.
Another downside is the inability to grow the model with your business. When embarking on a new project, requirements are often modest. AWS Rekognition shines here, catapulting you from zero to 80% completion in record time. Over time, however, you realise there are some specific cases that you need to optimise your application for and Rekognition is not working flawlessly in those situations anymore. You can bring your own dataset and use AWS Rekognition Custom Labels which is a fantastic feature. It is a bit of work to get it right but once it works it can get you quite far. Unfortunately, if you outgrow even this feature and you need to tweak your model even further, the only option is to start over with a custom model. This limitation can feel restrictive, hindering your models evolution alongside your business needs which brings me to pre-trained models.
Overall, Rekognition can get you started quite quickly and bring you a lot of added value. Yet, as your project matures, its constraints and pricing can become bottlenecks and you will need to dance around them.
YOLO and Friends: A Versatile Approach to Object Detection
You Only Look Once, commonly known as YOLO, is a well-established player in the world of computer vision. This pre-trained model boasts remarkable speed and accuracy, making it an excellent choice for detecting hundreds of object categories within images. Whether youre building a recommendation system, enhancing security, or analyzing satellite imagery, YOLO has your back. There are also many alternatives out there so do your research and pick the best model for your images. Hugging Face is a great starting point.
YOLO comes in various sizes, akin to a wardrobe of pre-trained outfits. Start with the smallest, lightweight and nimble. As your business needs evolve, upgrade to larger variants. But heres the magic: YOLOs flexibility extends beyond off-the-rack sizes. You can fine-tune it with your own data, enhancing accuracy to suit your unique context. It needs a little bit of knowledge but by the time your business will need such accuracy, you will probably also have some time and budget for it. It is not a silver bullet but you will eventually not face a dead end with the only solution of starting over like with AWS Rekognition.
Implementation
Python is these days the de-facto standard programming language for data analysis and machine learning. If you are familiar with Python, go ahead and leverage the YOLO documentation to implement a Python Lambda function for image classification. For educational purposes, I think its beneficial to assume you are not necessarily running everything in Python. I like to use JavaScript/TypeScript and I will use it here as an example. If you prefer to write your e-commerce solution, FinTech startup, or CRM in a different language, Python can not stop you here.
ONNX Runtime
Developing machine learning (ML) models in Python has become second nature for data scientists and engineers. Yet, the beauty of ML lies not in the language used during development, but in the ability to deploy and run those models seamlessly across diverse platforms. ONNX Runtime is a set of tools that allows you to achieve portability of models across different platforms, languages as well a variety of computing hardware.
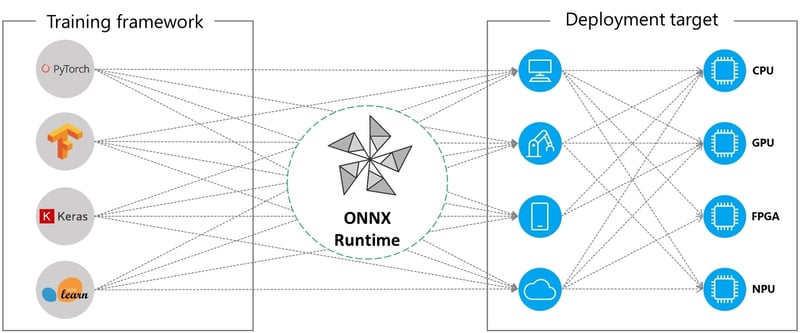
You can choose a model developed in several of the common frameworks and export it into a *.onnx format that can be easily run on a specialized cloud processor or in your web browser. Lets draw a parallel. Think of ONNX as the bytecode of the ML world. When you compile Java code, it transforms into bytecode, a portable representation that can journey across platforms. Then the ONNX Runtime, our Java Virtual Machine (JVM) for ML, will take the intermediate format and run it specifically optimized for the hardware configuration of the device.
ONNX Runtime is like JVM. Wherever it runs you can execute your models the same way. In our case, we will use the JavaScript version of ONNX Runtime for Node.js which is running in AWS Lambda as well. If you prefer a different language or a different infrastructure, feel free to leverage it as long as ONNX Runtime is available for your tech stack. Even though ONNX Runtime and JVM are quite different technologies, they share some common concepts at their core.
PyTorch to ONNX Conversion

ONNX covers many languages and platforms, yet a touch of Python to convert the model first remains essential. Because YOLO is leveraging PyTorch, lets look at this variant. If you leverage TensorFlow or any other supported model format, the principle stays the same, just the specific commands will differ.
import torchmodel = torch.load("./yolov8n.pt")torch.onnx.export(model, "./yolov8n.onnx")First, you need to load the original model. In our case it is yolov8n.pt - the smallest of the shelf YOLO variants. Then we need to convert it to yolov8n.onnx format. PyTorch already has an export method so we leverage it. Keep in mind that you can tweak the model even during the export and if you are planning to put a heavy load on the model, this can increase your performance and save you quite a lot of money. For simplification, we will just export it as it is.
Inference
Running the inference is almost as easy as the export. I will use JavaScript here to demonstrate a different language scenario which you might probably have. The Node.js ONNX Runtime library is quite lightweight and powerful.
The inference process can be broken down into three main steps:
- Preprocessing - prepare the picture for the model
- Prediction - ask the model to execute the classification
- Postprocessing - convert the output into human-readable format
We create an InferenceSession instance which loads the ONNX model. Then you can just run it with the input to classify.
import { InferenceSession } from 'onnxruntime-node';const session = await InferenceSession.create('./yolov8n.onnx');const input = { ... };const results = await session.run(input);The input for the inference is a picture converted into a specific format that YOLO requires. In simple words it needs to be an array of all pixels ordered by colour: [...red, ...green, ...blue]. Each pixel in a standard color image has a value of red, green and blue which together mix the final color. So if your picture has 2 pixels, you put the red value of the first pixel into the array and move to the next pixel. Once both reds are in the array, repeat the same process for greens and blues.
Pixel1: [R1, G1, B1]
Pixel2: [R2, G2, B2]
YOLO Input: [R1, R2, G1, G2, B1, B2]
For more details, explore the YOLO v8 reference implementation.
Results
YOLO returns back three types of information. They all come in a bit ciphered format from the model but with a little bit of postprocessing (NMS) they look like this:
- Label - the model returns an identifier, which you can easily convert to a name of the object category
- Bounding Box - coordinates, where in the picture was the label detected
- Probability - a number on a range from 0 to 1 how confident is the model about the label here
[ { "label": "person", "probability": 0.41142538189888, "boundingBox": [ 730.8682617187501, 400.01552124023436, 150.67451171875, 180.06134033203125 ] }, ...]Its important to note that bounding box coordinates are normalized. You will therefore need to account for the original image width and height to calculate the specific coordinates if you want to draw rectangles around the detected objects like in my example.

Deployment
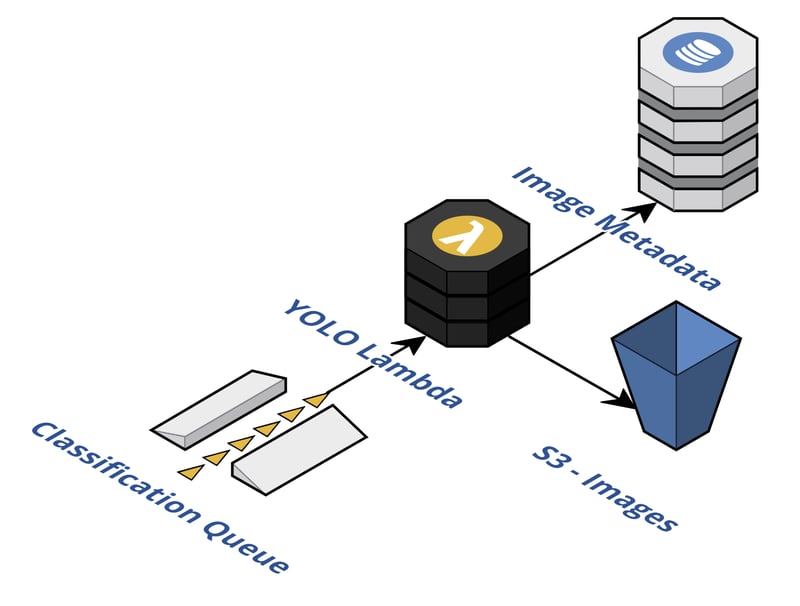
Microservices and event-driven architecture (EDA) are preferred choices in modern cloud architectures. The only step missing here is wrapping an API around the model and deploying it into a Lambda function that fits well into this architecture paradigm from several points of view.
Lambda is a serverless compute service that allows quick scaling and handling quite a big load as well as scaling down to zero. This means that Lambda itself costs nothing if not used. Its an ideal candidate for an infrequent asynchronous load to annotate images. Scenarios like automatic content moderation, building an image search index, or improving your image ALT attributes because of SEO are perfect for this architecture.
Ideally, we would like to leverage an asynchronous SQS queue or EventBridge as a source of the events. Furthermore, storing the actual image in S3 and the results in DynamoDB can be a great addition. These architectural decisions depend highly on your application though.
AWS Rekognition vs. YOLO Lambda Comparison
Ive mentioned earlier that AWS Rekognition is not the cheapest service, especially at scale so lets compare the YOLO Lambda solution with Rekognition. Note that this is not a detailed benchmark, just a high-level comparison. Your implementation may vary.
| AWS Rekognition | YOLO Lambda | |
|---|---|---|
| Inference | ~300ms | ~1s |
| Cost per image | $0.0010 | $0.0000166667 |
| Images per $1 | ~1000 | ~60K |
| Resources | 1024 MB RAM | |
| Other | us-east-1 | YOLO: 8n |
As you can see, the price difference (~60x) is quite significant in favor of YOLO Lambda although the comparison is not strictly apples to apples. I used the smallest YOLO model which is not as accurate as Rekognition. For some use cases that might be enough though. On the other hand, you can leverage the flexibility of a custom image model and upgrade the accuracy as you go or even fine-tune the accuracy with your own dataset.
With Rekognition, you get the simplicity of an API which is in many cases great to start with and in some cases even to stay with. YOLO Lambda is a bit more complicated to build and operate, however, it gives you great flexibility in terms of price, functionality, performance, and accuracy. Both variants can be further optimised for performance and cost so dont take this calculation for granted.
Conclusion
Computer Vision is a very interesting and helpful capability if you are working with pictures. It can help you moderate content, identify specific objects, or even improve the SEO of your e-commerce website (article coming soon).
Achieving the best accuracy vs. price combination can sometimes be tricky with API-based services. Therefore we explored the possibilities of how to take advantage of pre-trained models like YOLO and run them in AWS Lambda with much more control and options to tweak for your specific use case. Finally, we compared the pros and cons of each solution from the cost perspective so you can pick the right one for you.
For those interested in delving deeper into this topic, I recently spoke at a conference where I discussed these concepts in greater detail. I encourage you to watch the video of the talk for additional insights and practical examples.
Are you leveraging computer vision in your application? Leave a comment below, I would love to hear your thoughts and experience.
Original Link: https://dev.to/aws-builders/afraid-of-outgrowing-aws-rekognition-try-yolo-in-lambda-25lk
Dev To
More About this Source Visit Dev To