
An Interest In:
Web News this Week
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
Some of Our Sources
- BoingBoing
- Engadget
- Mashable
- TutsPlus - Design
- Vandelay Design
- Naldz Graphics
- FanExtra - PSD
- Web Design Ledger
- Web Resource Source
- Daily Now
Help Webnuz
Referal links:
Web Scraping With Java

Some of the popular languages used for web scraping are Python, JavaScript with Node.js, PHP, Java, C#, and many others. Every language has its strengths and weaknesses. For now, lets focus on web scraping with Java.
Web scraping frameworks
There are two most commonly used libraries for web scraping with Java JSoupand HtmlUnit.
JSoup is a powerful library that can effectively handle malformed HTML. The name of this library comes from the phrase tag soup, which refers to the malformed HTML document.
HtmlUnit is a GUI-less, or headless, browser for Java programs. It can emulate the key aspects of a browser, such as getting specific elements from a page, clicking the elements, etc. As the name of this library suggests, it is commonly used for unit testing. It is a way to simulate a browser for testing purposes.
HtmlUnit can also be used for web scraping. The good thing is that with just one line, JavaScript and CSS can be turned off. It is helpful in web scraping as JavaScript and CSS are not required most of the time. In the later sections, we will examine both libraries and create web scrapers.
Prerequisites for building a web scraper with Java
This tutorial assumes that you are familiar with the Java programming language. For managing packages, we will be using Maven.
Apart from Java basics, a primary understanding of how websites work is also expected. Good knowledge of HTML and selecting elements, either by using XPath or CSS selectors, would also be required. Note that not all libraries support XPath.
Quick overview of CSS selectors
Before proceeding, lets review the CSS selectors:
- #firstname selects any element where idequals firstname.
- .blue selects any element where the classcontains blue.
- p selects all <p>tags.
- div#firstname selects divelements where idequals firstname.
- p.link.new note that there is no space here. It selects <p class="link new">.
- p.link .new note the space. Selects any element with class new, which is inside <p class="link">.
Now lets review the libraries that can be used for web scraping with Java.
Web scraping with Java using JSoup
JSoup is perhaps the most commonly used Java library for web scraping. Broadly speaking, there are three steps involved in web scraping using Java.
Getting JSoup
The first step is to get the Java libraries. Maven can help here. Use any Java IDE and create a Maven project. If you do not want to use Maven, head over to this pageto find alternate downloads.
In the pom.xml(Project Object Model) file, add a new section for dependencies and add a dependency for JSoup. The pom.xmlfile would look something like this:
<dependencies> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.14.1</version> </dependency> </dependencies> |
With this, we are ready to create a Java scraper.
Getting and parsing the HTML
The second step is to get the HTML from the target URL and parseit into a Java object. Lets begin with the imports:
importorg.jsoup.Connection; importorg.jsoup.Jsoup; importorg.jsoup.nodes.Document; importorg.jsoup.nodes.Element; importorg.jsoup.select.Elements; |
Note that it is not a good practice to import everything with a wildcard import org.jsoup.*.Always import exactly what you need. The above imports are what we are going to use in this tutorial.
JSoup provides the connectfunction. This function takes the URL and returns a Document. Here is how you can get the pages HTML:
Document doc =Jsoup.connect("https://en.wikipedia.org/wiki/Jsoup").get(); |
You will often see this line in places, but it has a disadvantage. This shortcut does not have any error handling. A better approach would be to create a function. This function takes a URL as a parameter. First, it creates a connection and then stores it in a variable. After that, the get()method of the connection object is called to retrieve the HTML document. This document is returned as an instance of the Documentclass. The get()method can throw an IOException, which needs to be handled.
publicstaticDocument getDocument(String url){ Connection conn =Jsoup.connect(url); Document document =null; try{ document =conn.get(); }catch(IOException e){ e.printStackTrace(); // handle error } returndocument; } |
In some instances, you would need to pass a custom user agent. This can be done by sending the user agent string to the userAgent()function before calling the get()function:
Connection conn =Jsoup.connect(url); conn.userAgent("custom user agent"); document =conn.get(); |
This action should resolve all the common problems.
Querying HTML
The most crucial step of any Java web scraper building process is to query the HTML Documentobject for the desired data. This is the point where you will be spending most of your time.
JSoup supports many ways to extract the desired elements. There are many methods, such as getElementByID, getElementsByTag, etc., that make it easier to query the DOM.
Here is an example of navigating to the JSoup page on Wikipedia. Right-click the heading and select Inspect, thus opening the developer tools with the heading selected.
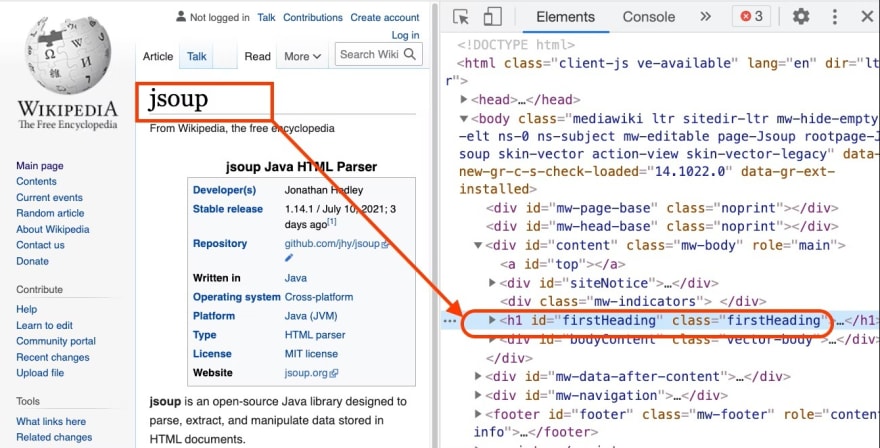

Image: HTML Element with a unique class
In this case, either getElementByIDor getElementsByClasscan be used. One important point to note here is that getElementById(note the singular Element) returns one Elementobject, whereas getElementsByClass(note plural Elements) returns an Arraylist of Elementobjects.
Conveniently, this library has a class Elementsthat extends ArrayList<Element>. This makes code cleaner and provides more functionality.
In the code example below, the first()method can be used to get the first element from the ArrayList. After getting the reference of the element, the text()method can be called to get the text.
Element firstHeading =document.getElementsByClass("firstHeading").first(); System.out.println(firstHeading.text()); |
These functions are good; however, they are specific to JSoup. For most cases, the selectfunction can be a better choice. The only case when select functions will not work is when you need to traverse up the document. In these cases, you may want to use parent(), children(), and child(). For a complete list of all the available methods, visit this page.
The following code demonstrates how to use the selectFirst()method, which returns the first match:
Element firstHeading=document.selectFirst(".firstHeading"); |
In this example, selectFirst()method is used. If multiple elements need to be selected, you can use the select()method. This will take the CSS selector as a parameter and return an instance of Elements, which is an extension of the ArrayList<Element> type.
Web scraping with Java using HtmlUnit
There are many methods to read and modify the loaded page. HtmlUnit makes it easy to interact with a web page like a browser, which involves reading text, filling forms, clicking buttons, etc. In this case, we will be using methods from this library to read information from URLs.
As discussed in the previous section, there are three steps involved in web scraping with Java.
Getting and parsing the HTML
The first step is to get the Java libraries. Maven can help here. Create a new maven project or use the one created in the previous section. If you do not want to use Maven, head over to this pageto find alternate downloads.
In the pom.xml file, add a new section for dependenciesand add a dependency for HtmlUnit. The pom.xmlfile would look something like this:
<dependency> <groupId>net.sourceforge.htmlunit</groupId> <artifactId>htmlunit</artifactId> <version>2.51.0</version> </dependency> |
Getting the HTML
The second step of web scraping with Java is to retrieve the HTML from the target URL as a Java object. Lets begin with the imports:
importcom.gargoylesoftware.htmlunit.WebClient; importcom.gargoylesoftware.htmlunit.html.DomNode; importcom.gargoylesoftware.htmlunit.html.DomNodeList; importcom.gargoylesoftware.htmlunit.html.HtmlElement; importcom.gargoylesoftware.htmlunit.html.HtmlPage; |
As discussed in the previous section, it is not a good practice to do a wildcard import such as import com.gargoylesoftware.htmlunit.html.*.Import only what you need. The above imports are what we are going to use in this Java web scraping tutorial.
In this example, we will scrape this Librivox page.
HtmlUnit uses the WebClientclass to get the page. The first step is to create an instance of this class. In this example, there is no need for CSS rendering, and there is no use of JavaScript as well. We can set the options to disable these two:
WebClient webClient =newWebClient(); webClient.getOptions().setCssEnabled(false); webClient.getOptions().setJavaScriptEnabled(false); HtmlPage page =webClient.getPage("https://librivox.org/the-first-men-in-the-moon-by-hg-wells"); |
Note that the getPage()functions can throw IOException. You would need to surround it in a try-catch.
Here is an implementation example of a function that returns an instance of HtmlPage:
publicstaticHtmlPage getDocument(String url){ HtmlPage page =null; try(final WebClient webClient =newWebClient()){ webClient.getOptions().setCssEnabled(false); webClient.getOptions().setJavaScriptEnabled(false); page =webClient.getPage(url); }catch(IOException e){ e.printStackTrace(); } returnpage; } |
Querying HTML
There are three categories of methods that can be used with HTMLPage. The first is DOM methods such as getElementById(), getElementByName(), etc., that return one element. These also have their counterparts like getElementsById()that return all the matches. These methods return a DomElementobject or a List of DomElementobjects.
HtmlPage page =webClient.getPage("https://en.wikipedia.org/wiki/Jsoup"); DomElement firstHeading =page.getElementById("firstHeading"); System.out.print(firstHeading.asNormalizedText());// prints Jsoup |
The second category of a selector uses XPath. Navigate to this page, right-click the book title and click Inspect. If you are already comfortable with XPath, you should be able to see that the XPath to select the book title would be //div[@class="content-wrap clearfix"]/h1.


Image: Selecting Elements by Xpath
There are two methods that can work with XPath getByXPath()and getFirstByXPath(). They return HtmlElementinstead of DomElement. Note that special characters like quotation marks will need to be escaped using a backslash:
HtmlElement book =page.getFirstByXPath("//div[@class="content-wrap clearfix"]/h1"); System.out.print(book.asNormalizedText()); |
Lastly, the third category of methods uses CSS selectors. These methods are querySelector()and querySelectorAll(). They return DomNodeand DomNodeList<DomNode>respectively.
To make this Java web scraper tutorial more realistic, lets print all the chapter names, reader names, and duration from the page. The first step is to determine the selector that can select all rows. Next, we will use the querySelectorAll()method to select all the rows. Finally, we will run a loop on all the rows and call querySelector()to extract the content of each cell.
String selector =".chapter-download tbody tr"; DomNodeList<DomNode>rows =page.querySelectorAll(selector); for(DomNode row :rows){ String chapter =row.querySelector("td:nth-child(2) a").asNormalizedText(); String reader =row.querySelector("td:nth-child(3) a").asNormalizedText(); String duration =row.querySelector("td:nth-child(4)").asNormalizedText(); System.out.println(chapter +" "+reader +" "+duration); } |
Conclusion
Almost every business needs web scraping to analyze data and stay competitive in the market. Knowing the basics of web scraping and how to build a web scraper using Java can result in more informed and quick decisions, which are essential for a business to succeed.
Original Link: https://dev.to/oxylabs-io/web-scraping-with-java-1ca2
Dev To
More About this Source Visit Dev To