
An Interest In:
Web News this Week
- April 27, 2024
- April 26, 2024
- April 25, 2024
- April 24, 2024
- April 23, 2024
- April 22, 2024
- April 21, 2024
Some of Our Sources
- Engadget
- Techcrunch
- The Logo Smith
- Smashing Magazine
- Smashing Apps
- Inspiredology
- My Ink Blog
- 24 Ways
- Daily Now
- Dev To
Help Webnuz
Referal links:
Bases de datos distribuidas: sharding.
En el post anterior habl de algunos conceptos bsicos para entender el modelo de documento. Bsicamente, el modelo de documento surgi de una necesidad real por parte de los desarrolladores de tener un sistema ms idiomtico de representar datos y sus relaciones, que se pudiera mapear a los objetos que tpicamente creamos cuando usamos patrones de programacin orientados a los mismos, OOP.
Bsicamente, el modelo de documento surgi de una necesidad real por parte de los desarrolladores de tener un sistema ms idiomtico de representar datos y sus relaciones, que se pudiera mapear a los objetos
Es preciso recordar que las primeras bases de datos relacionales de modelo tabular, surgieron en los 70. Es decir, cuando el uso que se le daba a los sistemas computacionales era diferente del de ahora (no comprenda la web, por ejemplo!), y los mismos se desplegaban y servan de manera centralizada. No exista ni una necesidad, ni una infraestructura, ni una governanza que requiriera que las bases de datos se distribuyeran a travs de diversas ubicaciones.
Las primeras bases de datos relacionales de modelo tabular, surgieron en la dcada de 1970. Es decir, cuando el uso que se le daba a los sistemas computacionales era bastante diferente, y los mismos se desplegaban y servan de manera centralizada
Pero los tiempos cambiaron y la necesidad vino determinada por la globalizacin producto del acceso masivo a los mismos productos, servicios y aplicaciones, por parte de los usuarios de internet a nivel mundial. Esta globalizacin exacerb problemas ya existentes, pero menos relevantes, como la latencia. La latencia determina cunto tiempo pasa desde que se inicia una peticin hasta que se recibe una respuesta, en un modelo cliente servidor.

Antes de que las nubes pblicas y sus proveedores entraran en escena, los despliegues se hacan 'en premisas', es decir en las mismas premisas donde las empresas y organizaciones operaban sus negocios o en un centro de datos cercano. (Recordemos que todava hay un enorme porcentaje de organizaciones que por motivos de seguridad o retraso en la adopcin de sistemas en la nube, siguen operando en premisas o como se conoce en ingls 'on-prem(ise)'). Ms adelante, los centros de datos que se dedicaban a proveer y mantener infraestructuras y las redes necesarias, fueron creciendo y distribuyndose. Finalmente, el requerimiento de un mejor rendimiento, menos latencia, y de los controles de privacidad en forma de soberana de datos por parte de pases y regiones (como puede ser GDPR en la Unin Europea), definieron la descentralizacin y los modernos sistemas de distribucin de datos.
Pero muchas veces, aunque estos sistemas cachean datos en diversas regiones del globo (es decir, guardan una copia para servir ms eficientemente a puntos distribuidos lo que se conoce como CDN), siguen teniendo su nodo transaccional en un nico punto.
Qu es el sharding?
Sharding es simplemente ese proceso de dividir grandes volumenes de datos en partes ms pequeas, que se guardan generalmente en particiones fsicas o virtuales diferentes. Cualquier base de datos se puede dividir as, pero es un proceso complicado, que requiere toda una refactorizacin y reconfiguracin de acuerdo a la nueva distribucin.
Partir modelos tabulares de modo que podamos desplegar parte de la base de datos en una regin de la nube, por ejemplo, y otra parte en otra regin, exige un diseo de sistema y una infraestructura realmente complejos. Particularmente por cmo est diseado el modelo relacional, para desacoplar datos a los que se accede de manera frecuente, pero deben seguir relativos a otro (u otros) grupos de datos para conformar una entidad.
Partir modelos tabulares de modo que podamos desplegar parte de la misma base de datos en una regin de la nube, por ejemplo, y otra parte en otra regin, exige un diseo de sistema y una infraestructura, realmente complejos.

El modelo de documento simplifica la distribucin de datos
Sin embargo, el modelo documento propuso que todos los datos a los que se accede juntos, se guardan juntos, en un nico documento. Y aunque existen muchas excepciones a esa regla, y formas de relacionar documentos en distintas colecciones a travs de ciertos patrones de diseo, es muy importante tener esta definicin en cuenta, a la hora de disear bases de datos de modelo de documento.
Una de las ventajas es que es mucho ms simple 'dividir' bases de datos en conjuntos de datos completamente diferentes, siguiendo una estrategia de particionamiento si respetamos ese precepto.
En el caso de MongoDB adems, el proceso de sharding es nativo y se puede automatizar, interviniendo en l otros procesos como el enrutado, el auto-balanceo, etc.
Sharding si, sharding no
El sharding de MongoDB no es en lo absoluto un proceso simple. Es un proceso complejo que necesita una estrategia bien meditada para ser exitoso. Una de las preguntas ms importantes que debemos hacernos (como con todos los procesos que implican una re-estructuracin de la arquitectura, con un coste elevado) es si realmente lo necesitamos.
Es importante tener en cuenta que en Cosmos DB, por ejemplo, el sistema est particionado por defecto, en particiones pequeas. Hablaremos de esto en el siguiente post.
Para empezar, es importante saber que el sharding en una base de datos MongoDB se recomienda solamente para volmenes muy grandes de datos. Pensemos en varios TB's de los mismos. Generalmente el volumen recomendado estar ligado a la infraestructura donde corre el software y su capacidad del hardware, que determina el rendimiento del motor a nivel escaneado, compresin y cacheado. Pero eso es tema para otro blog post. As que prosigamos.
Incluso si nuestro volumen de datos comprimido est por encima de los TB's recomendados en ese momento, la primera pregunta que hay que hacerse antes de habilitar sharding, tendr que ver con la arquitectura de nuestros datos, y las politicas de retencin de los mismos. Es decir...realmente necesitamos tener en caliente, todos los datos que guardamos?.
Datos fros y datos calientes
Una de las definiciones ms importantes que tiene que hacer una empresa en el momento en que empieza a brindar un servicio a usuarios a travs de una aplicacin, es la poltica de retencin de datos.
A nivel estrategia de negocio siempre ser ms barato, y por ende ms ventajoso para nuestra empresa, el definir claramente las expectativas y acuerdos de acceso a los datos por parte de nuestros usuarios. Es decir, imaginemos que somos una start-up que recabamos datos a los que los usuarios acceden a travs de nuestra aplicacin o plataforma, podemos definir que los usuarios tendrn acceso inmediato a los datos de menos de 12 meses de edad en la base de datos, y que deben esperar un poco ms tiempo para obtener datos ms antiguos. Por un poco ms de tiempo, me refiero a algunos segundos en vez de nano o milisegundos.
Ese tipo de trminos de uso son generalmente aceptados como normales por los usuarios, y nos permiten mantener datos en caliente por menos tiempo (es decir, en un cluster de acceso inmediato) mientras que los ms antiguos de guardan en almacenamiento fro, por ejemplo un data lake (lago de datos? Nunca lo he escuchado en espaol, pero eso sera literalmente el nombre!). Los data lakes son almacenamientos en mquinas menos potentes, y por lo tanto son ms baratos y admiten volmenes enormes de datos.
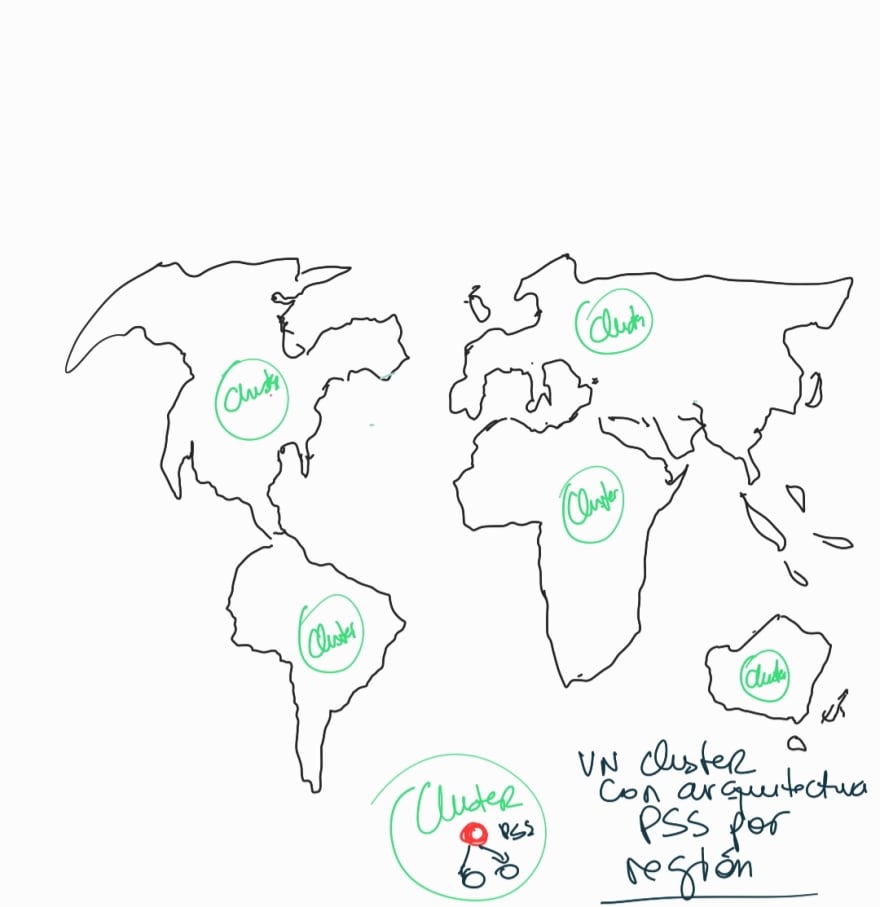
Mltiples clusters como alternativa al sharding
Otra alternativa para volmenes grandes de datos que deben estar en caliente, de ms fcil implementacin y mantenimiento particularmente cuando se debe observar la soberana de datos, es la de desplegar bases de datos a travs de diferentes clusters, en vez de recurrir al sharding.
Qu pasa en nuestra base de datos, cuando la particionamos?
Ahora que ya hemos hablado de volmenes mnimos de datos, y de polticas de datos que nos permitan mover datos a almacenamientos ms baratos, y que ya hemos establecido que el sharding es un proceso caro a nivel complejidad de la implementacin y mantenimiento, hablemos del mecanismo de sharding en si.
El sharding es un proceso que reconfigura al driver para que la aplicacin ignore que se est comunicando con mltiples instancias de la base de datos, y ejecuta un balanceo de cargas que mueve datos automticamente entre las mismas.
El
shardinges un proceso que reconfigura al driver para que la aplicacin ignore que se est comunicando con mltiples instancias de la base de datos, y ejecuta un balanceo de cargas que mueve datos automticamente entre las mismas, de acuerdo a una estrategia predefinida.
As como enfatizamos en que la replicacin es una copia del mismo conjunto de datos que permite la redundancia de los mismos en varios nodos, es importante recordar que cada shard o particin, es (si se siguen buenas prcticas) un conjunto de rplicas en si.
Cada
shardo particin, es un conjunto de rplicas en s. Tcnicamente es posible que cada shard sea un nodo nico standalone, pero recordemos que eso no es lo recomendado
En un momento hablaremos de las estrategias de sharding, que dependen de su clave de sharding. La clave de sharding o sharding key es bsicamente el campo que define cmo se separarn los datos, y cmo se indexarn. Antiguamente, una vez se elega una clave, no se poda cambiar, pero desde la versin 5.0 de MongoDB se puede cambiar con un proceso de resharding.
Componentes de la arquitectura de sharding
Una de las razones por las que el sharding es ms caro de mantener, es que requiere varios nodos adicionales al standalone o a las rplicas (en el caso de que cada shard sea un conjunto de rplicas, como se recomienda).
Vamos a suponer que tenemos 3 shards de arquitectura PSS. Uno de los 3 shards va a ser el primario. Adems, necesitaremos un nodo adicional que corra el proceso mongos. Tambin necesitaremos un servidor de configuracin, que tambin es un conjunto de rplicas. Con esta configuracin y usando buenas practicas, tenemos nada menos que 13 nodos corriendo!

El proceso Mongos
Este proceso es un proceso de enrutado (un router) que mantiene una tabla de contenido de la base de datos que dirige las peticiones del cliente hacia el shard correcto, y acta como intermediario entre la aplicacin y la base de datos particionada. La arquitectura acabar siendo como se ilustra en el diagrama anterior.
Cuando habilitamos sharding en una base de datos, para una o varias colecciones, debemos elegir la clave de shard, que como decamos, no es ms que un campo indexado de la coleccin en cuestin. Voy a dedicar una entrada de blog a los ndices (indexes en la jerga de MongoDB, no s por qu, pero el plural en este contexto es as ). La indexacin es uno de los temas ms complejos y difciles de entender, en lo que a MongoDB respecta.
Shards
Cuando se inicia el proceso de sharding, que por cierto es un proceso paulatino y asncrono que puede tardar das y hasta semanas en completarse (dependiendo del volumen de datos), pero que no interfiere con el funcionamiento de la base de datos (es decir, se puede ejecutar en sistemas en produccin, sin problemas), los datos de las colecciones afectadas se irn distribuyendo en forma de chunks del tamao predeterminado, a travs de la cantidad de shards configurada.
Un cluster particionado siempre tiene adems un shard primario que es el que guarda las colecciones que no estn sujetas a particin.
Chunks
Durante este proceso, el sistema particionar los datos en chunks o cachos(muy gracioso, pero no encuentro mejor traduccin!) y los ir distribuyendo y redistribuyendo de manera balanceada, a travs de los shards.
Estos chunks deben de tener, por convencin, un tamao mnimo de 64MB. No tiene sentido tener chunks de menos tamao. Recordar que el tamao mximo de un documento MongoDB es 16MB.
El
shardinges un proceso paulatino y asncrono que puede tardar das y hasta semanas en completarse, dependiendo del volumen de datos, y no interfiere con el funcionamiento de la base de datos; se puede ejecutar en sistemas en produccin.
Consultas (queries)
Las consultas que ejecutamos contra un sistema particionado son de dos tipos:
targeted queries, vendra a ser como consultas objetivas, y son las que contienen la clave de sharding, y que pueden ser dirigidas por mongos al shard que contiene los datos relevantes.
Por otro lados las consultas que no contienen la clave, se deben de mandar a todos los shards y se conocen como broadcast o scatter-and-gather, (algo as como desparramar-reunir), ya que son consultas que se lanzan o desparraman entre todos los shards para finalmente reunir los resultados.
Habilitando un sistema de sharding
Mientras que el sharding se habilita a nivel base de datos es importante entender que el mismo se ejecuta a nivel de coleccin. Ms abajo describo algunos mtodos.
Podemos utilizar la clase ShardingTest del servidor de MongoDB que instalamos con la versin Community, para crear un cluster de prueba. Es una clase que se usa internamente, para hacer pruebas de sharding, pero que est expuesta para uso externo. Podemos ver la implementacin, aqu.
Nota: Es importante saber que esto est disponible solo para la versin anterior de la herramienta de linea de comandos mongo y no para mongosh. Intentar para el siguiente post encontrar tiempo de cargar los scripts y snippets de compatibilidad para la clase y jstest, pero no prometo nada!)
Lo primero que hacemos es inicializar la consola de mongo
mongo --nodb --norccon los parametros --nodb y --norc para no inicializar una base de datos ni la evaluacin de JavaScript.
Luego podemos crear un par de shards de test as
testdesharding = ShardingTest({ name: "TestdeSharding", shards: 2, chunkSize: 1});Nota: Si esta clase nos da un error de boost relativo a la no existencia de la ruta data/db, se la podemos pasar al task runner as
MongoRunner.datapath = 'mi-ruta/es-tu-ruta/data/path';
(hay gente que va a entender la referencia y otra que no...jaja)
Hay muchsimas ms opciones de configuracin que podemos pasar a la hora de crear nuestro cluster de test, que estn descritas a partir de la lnea 8 del script. Entre ellas encontramos:
- name (nombre del cluster)
- shards (nmero de shards)
- rs (al que podemos pasar un objeto de configuracin para cada conjunto de replica, como cantidad de nodos y tamao del oplog)
- mongos (nmero de mongos que se corrern)
- chunkSize (el tamao de cada chunk)
- enableBalancer (si habilitamos el load balancer por defecto)
- enableAutoSplit (si habilitamos la auto particin)
etc
Cuando ejecutamos esta clase de test, creamos un cluster y se inicializan los procesos necesarios, incluyendo mongos y los conjuntos de rplica configurados, as como el servidor de configuracin.
Una vez creado el cluster, podemos probar los mtodos de sharding, que se describen en la documentacin oficial del software. Tambin podremos experimentar con las diversas estrategias de sharding. Por defecto el proceso mongos corre en el puerto 20009, pero se puede reconfigurar.
Para experimentar, abrimos otra ventana o pestaa de la terminal donde podemos crear una base de datos e importar o crear algunos datos, para poder experimentar.
Esto es solamente para hacer pruebas y aprender. Si furamos a habilitar un sistema de sharding de MongoDB real, deberamos seguir el proceso que se describe aqu.
Bsicamente deberamos inicializar todos los nodos por separados, primero que nada un conjunto de rplicas para el servidor de configuracin, que se inicializa con el parmetro --configsvr (siempre antes que el proceso mongos). Otro nodo para mongos que se inicializa con el comando mongos y el parmetro --configdb (al que se pasan los datos de los servidores de configuracin) Finalmente conectamos al que ser el shard primario, asgnandole el rol a cada miembro con la opcin --shardsvr, lo que deberemos repetir con cuantos nodos decidamos tener para los conjuntos de rplicas que conformaran cada shard.
Una vez tenemos todos los nodos activos, se pueden agregar al cluster de sharding manualmente con el comando
sh.addShard(//rplica set path + puerto);
al que pasamos cada rplica set individualmente.
Habilitar el proceso de distribucin de datos
Una vez tenemos todo configurado, debemos habilitar manualmente el sharding para la base de datos.
sh.enableSharding("nombre_base_de_datos");
y seguidamente, particionamos las colecciones que decidamos
sh.shardCollection("nombre_base_de_datos.nombre_coleccin", {"clave_de_particin": 1})
donde clave_de_particin es la clave elegida, o sea un campo indexado de la coleccin.
Estrategias de sharding
Como comentaba anteriormente, la forma ms eficiente de distribuir nuestros datos a travs de mltiples shards, va a determinarse por medio de una estrategia de particin.
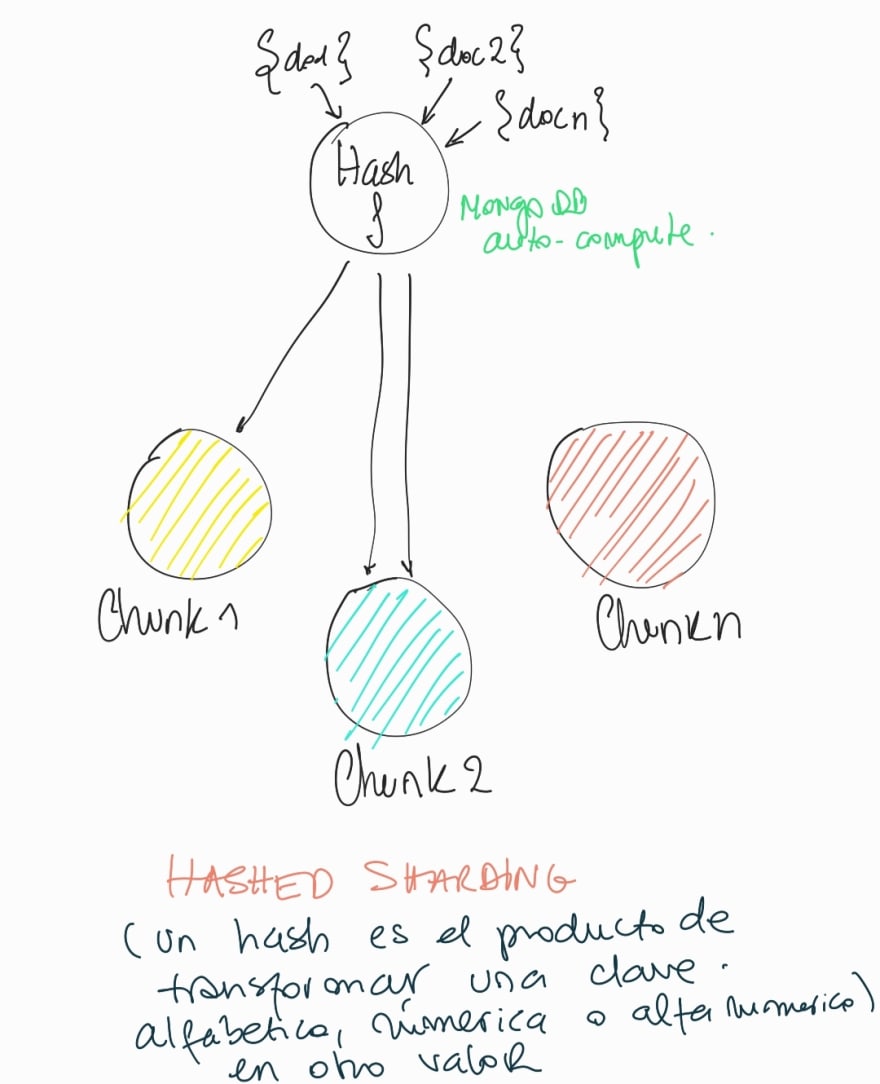
La estrategia de hash
La estrategia de hashing es la ms eficiente a la hora de distribuir datos de manera balanceada. Los datos se distribuyen de manera aleatoria, asegurndose que hay el mismo volumen de datos en cada particin. Es la estrategia ideal cuando la intencin es liberar espacio de disco y asegurarnos que los datos se distribuyen de manera equitativa.
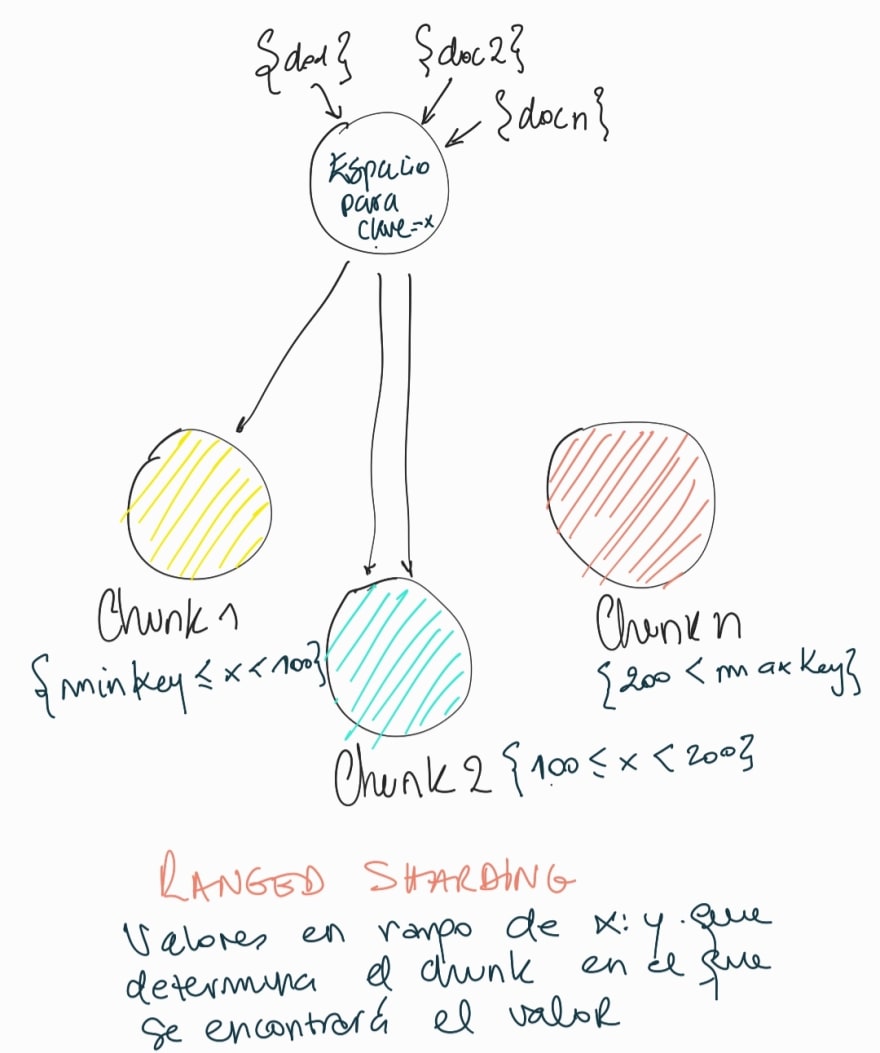
La estrategia de rango
Esta estrategia es la ms eficiente para distribuir datos de acuerdo a ciertos rangos. Por ejemplo, si estamos distribuyendo usuarios, los podemos distribuir en el rango de la A a la I, de la J a la Q y de la R a la Z, de acuerdo con la primera letra de su apellido.
Una desventaja de la distribucin por rango, es la baja cardinalidad (hablaremos de cardinalidad cuando hablemos de indices) pero bsicamente, como habrn muchos apellidos con ciertas letras, y muy pocos con otras, ser difcil garantizar el buen balance.
La estrategia de zonas
Finalmente, podemos segmentar los datos ya distribuidos, por zonas. Las zonas pueden venir determinadas por el data locale, lo que permitira distribuir geogrficamente, o por otra variable. En el caso de usar la estrategia para distribuir geogrficamente, un shard que se encuentre desplegado en cierta regin del mundo guardar los datos de los usuarios que pertenecen a esa regin. Esta estrategia nos ayuda a cumplir con polticas de proteccin de datos, por ejemplo, pero al igual que la estrategia de rangos, puede incurrir en un desequilibrio de las particiones.

En el prximo post
La prxima entrada ser ms corta e intentar explicar sobre todo,
- Sharding en Produccin
- Particionamiento en CosmosDB y como difiere con MongoDB
A prestar atencin!
Original Link: https://dev.to/anfibiacreativa/bases-de-datos-distribuidas-sharding-4a39
Dev To
More About this Source Visit Dev To