
An Interest In:
Web News this Week
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
Some of Our Sources
- Mashable
- Technology Review
- Simplebits
- TutsPlus - Code
- Creative Curio
- Fuel Your Creativity
- Inspiredology
- Web Design Ledger
- Wal You
- Freelance Switch
Help Webnuz
Referal links:
Introduction to Modern Data Architecture (formerly Lake House)
Organizations have been building data lakes to analyze massive amounts of data for deeper insights into their data. To do this, they bring data from multiple silos into their data lake, and then run analytics and AI/ML directly on it.
It is common for these organizations to also have data stored in specialized data stores, such as a NoSQL database, a search service, or a data warehouse, to support different use cases.
To efficiently analyze all of the data spread across the data lake and other data stores, businesses often move data in and out of data lake and between these data stores. This data movement can get complex and messy as the data grows in these stores.
To address this, businesses need a data architecture that not only allows building scalable, cost-effective data lakes but also supports simplified governance and data movement between various data stores. We refer to this as a lake house architecture.
A lake house is a modern data architecture that integrates a data lake, a data warehouse, and other purpose-built data stores while enabling unified governance and seamless data movement.

Architecture Options for Building an Analytics Application on AWS is a Series containing different articles that cover the key scenarios that are common in many analytics applications and how they influence the design and architecture of your analytics environment in AWS. These series present the assumptions made for each of these scenarios, the common drivers for the design, and a reference architecture for how these scenarios should be implemented.
- As shown in the following diagram, with a lake house approach, organizations can store their data in a data lake and also be able to use purpose-built data stores that work with the data lake. This approach allows access to all of their data to make better decisions with agility.

Modern data architecture
In a lake house design, there are three different patterns for data movement. They can be described as follows:
- Inside-out data movement: A subset of data in a data lake is sometimes moved to a data store, such as an Amazon OpenSearch Service cluster or an Amazon Neptune cluster, to support specialized analytics, such as search analytics, building knowledge graphs, or both. This pattern is what we consider an inside-out data movement. For example, enterprises send information from structured sources (relational databases), unstructured sources (metadata, media, or spreadsheets) and other assets first to a data lake that is moved to Amazon Neptune to build a knowledge graph.
- Outside-in data movement: Organizations use data stores that best fit their applications and later move that data into a data lake for analytics. For instance, to maintain game state, player data, session history, and leaderboards, a gaming company right chooses Amazon DynamoDB as the data store. This data can later be exported to a data lake for additional analytics to improve the gaming experience for its players. We refer to this kind of data movement as outside-in.
- Around the perimeter: In addition to the preceding two patterns, there are scenarios where the data is moved from one specialized data store to another. For example, enterprises might copy customer profile data from their relational database to a NoSQL database to support their reporting dashboards. This data movement is often considered as around the perimeter.
Characteristics
Scalable data lake: A data lake is at the center of a well-architected lake house design. A data lake should be able to scale easily to petabytes and exabytes as data grows. Use a scalable, durable data store that provides the fastest performance at the lowest cost, supports multiple ways to bring data in and has a good partner ecosystem.
Data diversity: Applications generate data in many formats. A data lake should support diverse data types structured, semi-structured, or unstructured.
Schema management: A lake house design should support schema on read for a data lake with no strict source data requirement. The choice of storage structure, schema, ingestion frequency, and data quality should be left to the data producer. A data lake should also be able to incorporate changes to the structure of the incoming data, which is referred to as schema evolution. In addition, schema enforcement helps businesses ensure data quality by preventing writes that do not match the schema.
Metadata management: Data should be self-discoverable with the ability to track lineage as data flows through tiers within the data lake. A comprehensive data catalog that captures the metadata and provides a query-able interface for all data assets is recommended.
**Unified governance: A lake house design should have a robust mechanism for centralized authorization and auditing. Configuring access policies in the data lake and across all the data stores can be extremely complex and error prone. Having a centralized location to define the policies and enforce them is critical to a secure lake house architecture.
Transactional semantics: In a data lake, data is often ingested nearly continuously from multiple sources and is queried concurrently by multiple analytic engines. Having atomic, consistent, isolated, and durable (ACID) transactions is pivotal to keeping data consistent.
Reference architecture
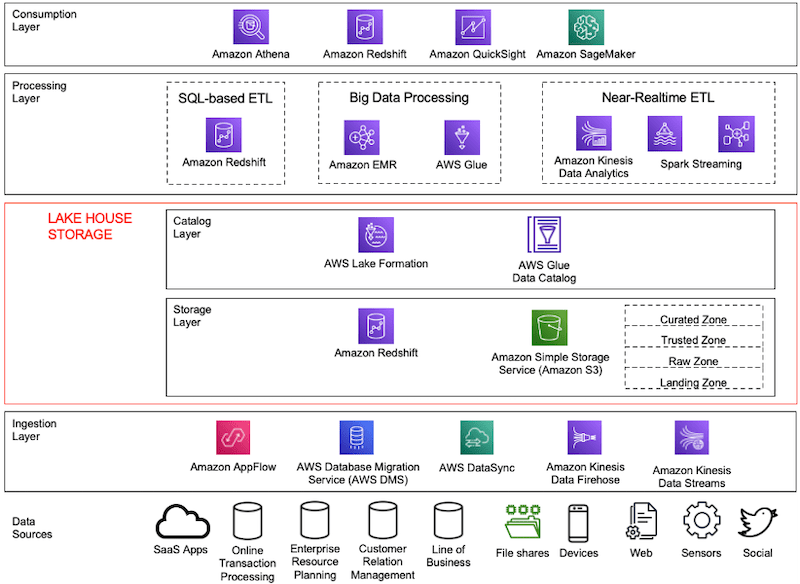
Modern data architecture reference architecture
Configuration notes
To organize data for efficient access and easy management:
- The storage layer can store data in different states of consumption readiness, including raw, trusted-conformed, enriched, and modeled. Its important to segment your data lake into landing, raw, trusted, and curated zones to store data depending on its consumption readiness. Typically, data is ingested and stored as is in the data lake (without having to first define schema) to accelerate ingestion and reduce time needed for preparation before data can be explored.
- Partition data with keys that align to common query criteria.
- Convert data to an open columnar file format, and apply compression. This will lower storage usage, and increase query performance.
Choose the proper storage tier based on data temperature. Establish a data lifecycle policy to automatically delete old data to meet your retention requirements.
Decide on a location for data lake ingestion (that is, an S3 bucket). Select a frequency and isolation mechanism that meets your business needs.
Depending on your ingestion frequency or data mutation rate, schedule file compaction to maintain optimal performance.
Use AWS Glue crawlers to discover new datasets, track lineage, and avoid a data swamp.
Manage access control and security using AWS Lake Formation, IAM role setting, AWS KMS, and AWS CloudTrail.
No need to move data between a data lake and the data warehouse for the data warehouse to access it. Amazon Redshift Spectrum can directly access the dataset in the data lake.
For more, refer to the Derive Insights from AWS Lake House whitepaper.
Hope this guide gives you an Introduction to Modern data architecture (formerly Lake House), explains the Characteristics, Reference Architecture and Configuration Notes for Modern data architecture.
Let me know your thoughts in the comment section
And if you haven't yet, make sure to follow me on below handles:
connect with me on LinkedIn
connect with me on Twitter
follow me on github
Do Checkout my blogs
Like, share and follow me for more content.
.ltag__user__id__497987 .follow-action-button { background-color: #000000 !important; color: #fa6c00 !important; border-color: #000000 !important; } 
Original Link: https://dev.to/aws-builders/introduction-to-modern-data-architecture-formerly-lake-house-29g6
Dev To
More About this Source Visit Dev To