
An Interest In:
Web News this Week
- April 22, 2024
- April 21, 2024
- April 20, 2024
- April 19, 2024
- April 18, 2024
- April 17, 2024
- April 16, 2024
Some of Our Sources
- Slashdot
- Technology Review
- Team Treehouse
- Joshua Blankenship
- Six Revisions
- FanExtra - PSD
- Freelance Switch
- Design Modo
- Web Resource Source
- Willems Lab
Help Webnuz
Referal links:
Introduction to Golang HTTP router made with net/http
This article is a translation of bmf-tech.com - net/httpHTTP
Introduction
This article explains how to create your own HTTP router using the standard Golang package net/http.
The standard package does not provide a lot of routing features.
For example, you cannot define routing for each HTTP method, you cannot use URLs as path parameters, and you cannot define routing using regular expressions.
Therefore, in actual application development, it is not uncommon to use a more sophisticated HTTP router.
The following are some of the benefits of creating your own HTTP router.
- Learn more about net/http
- You can experience the fun of algorithms.
- You will be able to implement an HTTP router that you want to use and that is easy to use.
- Be able to integrate the HTTP router into your own application after understanding all the implementation details
This article describes how to build your own HTTP router with the following structure.
- Introduction
- Table of Contents
- Chapter 1 What is a HTTP Router
- Chapter 2 Data Structure of HTTP Router
- Chapter 3 Code Reading of HTTP Server
- Chapter 4 Implementing an HTTP Router
- Summary
The contents of each chapter that deviate from the main topic arddde described as columns.
This article is intended to be useful for the following types of readers.
- You have understood the syntax of Golang and want to try to build something.
- Want to deepen their understanding of Golang's standard packages
- I want to try to implement a simple algorithm with Golang.
- I want to know how to extend the standard routing functions.
- I want to understand the implementation of HTTP routers that I usually use.
The following prerequisite knowledge is required to fully understand the contents of this article.
- Understand the basic syntax of Golang.
- Experience in using some kind of HTTP router.
The author has released an HTTP router package called bmf-san/goblin.
Please have a look at the code and try to use it. Contributors are also welcome.
Table of contents
- Introduction
- Table of Contents
- Chapter 1 What is a HTTP Router
- Chapter 2 Data Structure of HTTP Router
- Chapter 3 Code Reading of HTTP Server
- Chapter 4 Implementing an HTTP Router
- Summary
Chapter 1 What is a HTTP Router
HTTP routers are sometimes called URL routers, or simply routers, but in this article, we will use the unified name HTTP router.
An HTTP router is an application that ties the requested URL to the processing of the response, as shown in the following figure.

HTTP routers can perform routing based on the data that URLs and response processing are mapped to (hereinafter referred to as route map).
| Request URL | Handler |
|---|---|
| GET / | IndexHandler |
| GET /foo | FooHandler |
| POST /foo | FooHandler |
| GET /foo/:id | FooHandler |
| POST /foo/:id | FooHandler |
| GET /foo/:id/:name | FooHandler |
| POST /foo/:id/:name | FooHandler |
| GET /foo/bar | FooBarHandler |
| GET /foo/bar/:id | FooBarHandler |
| GET /foo/bar/:id/:name | FooBarHandler |
| GET /foo/bar/baz | FooBarBazHandler |
| GET /bar | BarHandler |
| GET /baz | BazHandler |
Inside the HTTP router, the defined route map becomes a routing-optimized data structure.
The data structure will be explained in the next chapter.
In this article, "routing" is defined as finding the response process according to the URL of the request, based on the route map.
Also, the application that performs routing in HTTP is defined as an "HTTP router.
Column: URL specifications
URL represents the address of a page on the Internet and is an abbreviation for Uniform ResourceLocator.
The format of a URL string is defined as follows
<scheme><scheme-specific-part>Protocol names such as http, https, ftp, etc. are often used in this part, but other schema names than protocol names are also defined.
Uniform Resource Identifier (URI) scheme
In the <scheme-specific-part> part, schema-based strings are defined.
For example, for http and https schemes, the rule is that the domain name and path name (or directory name) are defined.
For detailed URL specifications, please refer to RFC 1738.
RFC 1738-uniform resource locator (URL)
RFC 1738 is positioned as an Internet standard (STD1).
Chapter 2 Data Structure of HTTP Router
Consider the data structure.
The following is the root map illustrated in Chapter 1.
| Request URL | Handler |
|---|---|
| GET / | IndexHandler |
| GET /foo | FooHandler |
| POST /foo | FooHandler |
| GET /foo/:id | FooHandler |
| POST /foo/:id | FooHandler |
| GET /foo/:id/:name | FooHandler |
| POST /foo/:id/:name | FooHandler |
| GET /foo/bar | FooBarHandler |
| GET /foo/bar/:id | FooBarHandler |
| GET /foo/bar/:id/:name | FooBarHandler |
| GET /foo/bar/baz | FooBarBazHandler |
| GET /bar | BarHandler |
| GET /baz | BazHandler |
If we look at the URL, we can see that it is a hierarchical structure.
Since hierarchical structure goes well with tree structure, we will consider representing the root map as a tree structure.
What is a tree structure?
It is a data structure that has the structure of a tree in graph theory.
Tree structure is a data structure suitable for representing hierarchical structures.
The elements that make up a tree are called nodes, the node with no parent at the top is called the root, and the node with no children at the bottom is called the leaf. The connection between nodes is called an edge (branch).
Adding a node to a tree is called insertion, and finding a node in a tree is called search.

The following is an example implementation of a binary search tree, which is one of the most basic tree structures.
package mainimport ( "fmt")// Node is a node of a tree.type Node struct { Key int Left *Node Right *Node}// BST is a binary search tree.type BST struct { Root *Node}// insert insert a node to tree.func (b *BST) insert(key int) { if b.Root == nil { b.Root = &Node{ Key: key, Left: nil, Right: nil, } } else { recursiveInsert(b.Root, &Node{ Key: key, Left: nil, Right: nil, }) }}// recursiveInsert insert a new node to targetNode recursively.func recursiveInsert(targetNode *Node, newNode *Node) { // if a newNode is smaller than targetNode, insert a newNode to left child node. // if a newNode is a bigger than targetNode, insert a newNode to right childe node. if newNode.Key < targetNode.Key { if targetNode.Left == nil { targetNode.Left = newNode } else { recursiveInsert(targetNode.Left, newNode) } } else { if targetNode.Right == nil { targetNode.Right = newNode } else { recursiveInsert(targetNode.Right, newNode) } }}// remove remove a key from tree.func (b *BST) remove(key int) { recursiveRemove(b.Root, key)}// recursiveRemove remove a key from tree recursively.func recursiveRemove(targetNode *Node, key int) *Node { if targetNode == nil { return nil } if key < targetNode.Key { targetNode.Left = recursiveRemove(targetNode.Left, key) return targetNode } if key > targetNode.Key { targetNode.Right = recursiveRemove(targetNode.Right, key) return targetNode } if targetNode.Left == nil && targetNode.Right == nil { targetNode = nil return nil } if targetNode.Left == nil { targetNode = targetNode.Right return targetNode } if targetNode.Right == nil { targetNode = targetNode.Left return targetNode } leftNodeOfMostRightNode := targetNode.Right for { if leftNodeOfMostRightNode != nil && leftNodeOfMostRightNode.Left != nil { leftNodeOfMostRightNode = leftNodeOfMostRightNode.Left } else { break } } targetNode.Key = leftNodeOfMostRightNode.Key targetNode.Right = recursiveRemove(targetNode.Right, targetNode.Key) return targetNode}// search search a key from tree.func (b *BST) search(key int) bool { result := recursiveSearch(b.Root, key) return result}// recursiveSearch search a key from tree recursively.func recursiveSearch(targetNode *Node, key int) bool { if targetNode == nil { return false } if key < targetNode.Key { return recursiveSearch(targetNode.Left, key) } if key > targetNode.Key { return recursiveSearch(targetNode.Right, key) } // targetNode == key return true}// depth-first search// inOrderTraverse traverse tree by in-order.func (b *BST) inOrderTraverse() { recursiveInOrderTraverse(b.Root)}// recursiveInOrderTraverse traverse tree by in-order recursively.func recursiveInOrderTraverse(n *Node) { if n != nil { recursiveInOrderTraverse(n.Left) fmt.Printf("%d
", n.Key) recursiveInOrderTraverse(n.Right) }}// depth-first search// preOrderTraverse traverse by pre-order.func (b *BST) preOrderTraverse() { recursivePreOrderTraverse(b.Root)}// recursivePreOrderTraverse traverse by pre-order recursively.func recursivePreOrderTraverse(n *Node) { if n != nil { fmt.Printf("%d
", n.Key) recursivePreOrderTraverse(n.Left) recursivePreOrderTraverse(n.Right) }}// depth-first search// postOrderTraverse traverse by post-order.func (b *BST) postOrderTraverse() { recursivePostOrderTraverse(b.Root)}// recursivePostOrderTraverse traverse by post-order recursively.func recursivePostOrderTraverse(n *Node) { if n != nil { recursivePostOrderTraverse(n.Left) recursivePostOrderTraverse(n.Right) fmt.Printf("%v
", n.Key) }}// breadth-first search// levelOrderTraverse traverse by level-order.func (b *BST) levelOrderTraverse() { if b != nil { queue := []*Node{b.Root} for len(queue) > 0 { currentNode := queue[0] fmt.Printf("%d ", currentNode.Key) queue = queue[1:] if currentNode.Left != nil { queue = append(queue, currentNode.Left) } if currentNode.Right != nil { queue = append(queue, currentNode.Right) } } }}func main() { tree := &BST{} tree.insert(10) tree.insert(2) tree.insert(3) tree.insert(3) tree.insert(3) tree.insert(15) tree.insert(14) tree.insert(18) tree.insert(16) tree.insert(16) tree.remove(3) tree.remove(10) tree.remove(16) fmt.Println(tree.search(10)) fmt.Println(tree.search(19)) // Traverse tree.inOrderTraverse() tree.preOrderTraverse() tree.postOrderTraverse() tree.levelOrderTraverse() fmt.Printf("%#v
", tree)}We will not go into details here, but binary search trees are just the right trees to learn the basic algorithms of tree structures.
In addition to binary search trees, there are many other types of tree structures. Among them, trie trees (also known as prefix trees. Among them, a tree structure called a trie tree (also known as a prefix tree, we will call it a trie tree in this article) has a feature that it is easy to search for strings.
By using a trie tree, you can express a data structure that is easy to handle in routing.
What is a try tree?
A trie tree is a kind of tree structure that is also used in IP address lookup and morphological analysis.
Each node has a single or multiple strings or numbers, and a word is represented by searching from the root node to the leaves and connecting the values.
There is a service that allows you to visualize the algorithm and understand it dynamically, so it is easy to understand the data structure of a try tree.
Algorithm Visualizations - Trie (Prefix Tree)
Trie trees are relatively easy to implement.
The following code is an example of a trie tree with only search and insertion implemented.
package mainimport "fmt"// Node is a node of tree.type Node struct { key string children map[rune]*Node}// NewTrie is create a root node.func NewTrie() *Node { return &Node{ key: "", children: make(map[rune]*Node), }}// Insert is insert a word to tree.func (n *Node) Insert(word string) { runes := []rune(word) curNode := n for _, r := range runes { if nextNode, ok := curNode.children[r]; ok { curNode = nextNode } else { curNode.children[r] = &Node{ key: string(r), children: make(map[rune]*Node), } } }}// Search is search a word from a tree.func (n *Node) Search(word string) bool { if len(n.key) == 0 && len(n.children) == 0 { return false } runes := []rune(word) curNode := n for _, r := range runes { if nextNode, ok := curNode.children[r]; ok { curNode = nextNode } else { return false } } return true}func main() { t := NewTrie() t.Insert("word") t.Insert("wheel") t.Insert("world") t.Insert("hospital") t.Insert("mode") fmt.Printf("%v", t.Search("mo")) // true}By using this trie tree as a base, we will consider the data structure optimized for routing.
Consider the data structure of the route map based on the trie tree.
We will consider the data structure of the route map based on the concept of the trie tree.
The following is the data structure used in bmf-san/goblin, which is developed by the author.
The following is the data structure used in bmf-san/goblin, which is developed by the author. goblin supports middleware and path parameters, so the data structure is compatible with them.
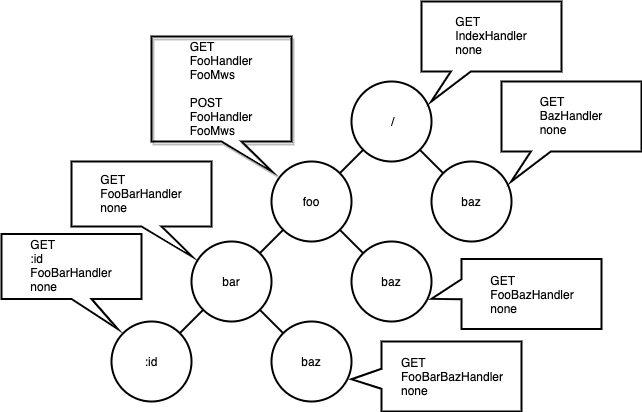
This data structure represents the following route map.
| Request URL | Handler | Middleware |
|---|---|---|
| GET / | IndexHandler | none |
| GET /foo | FooHandler | FooMws |
| POST /foo | FooHandler | FooMws |
| GET /foo/bar | FooBarHandler | none |
| GET /foo/bar/:id | FooBarHandler | none |
| GET /foo/baz | FooBazHandler | none |
| GET /foo/bar/baz | FooBarBazHandler | none |
| GET /baz | BazHandler | none |
The perspective can be summarized in the following two points.
- What rules should be used to represent the URL as a tree structure?
- What data is required to be stored in a node?
The former is the part that determines the performance of routing, and if you want to pursue processing time and memory efficiency, you need to consider adopting a more advanced tree structure.
The latter part is related to the functionality of the HTTP router, so it varies depending on the functions you want to provide.
The trie tree based tree structure introduced in this article is just a tree structure that the author came up with.
The data structure varies depending on the implementation requirements of the HTTP router.
In the next section, I will explain what you need to know in order to incorporate this data structure into your HTTP router.
Column: Radix tree (Patricia tree)
There is a tree structure called radix tree, which is a further development of the try tree for storing strings.
The author has observed that radix trees are often used in performance-conscious HTTP routers.
It also seems to be used inside the Golang strings package.
https://cs.opensource.google/go/go/+/refs/tags/go1.17.2:src/strings/strings.go;l=924
Chapter 3 Code Reading of HTTP Server
Before explaining the implementation of the HTTP router, we will use the following HTTP server code that uses net/http as an example to explain what you need to know about implementing the HTTP router.
Please refer to the following links if necessary.
https://cs.opensource.google/go/go/+/refs/tags/go1.17.2:
package mainimport ( "fmt" "net/http")func main() { mux := http.NewServeMux() mux.HandleFunc("/", handler) http.ListenAndServe(":8080", mux)}func handler(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "Hello World")}This code, although simple, is suggestive for creating your own HTTP router.
The code consists of calling the multiplexer, registering the handler, and starting the server.
Let's look at each of them in turn.
Calling the multiplexer
The first code creates a structure called http.ServeMux.
mux := http.NewServeMux()ServeMux is an HTTP request multiplexer (hereinafter referred to as a multiplexer).
This multiplexer is responsible for checking the URL of the request against the registered patterns and calling the most matching handler (the function that returns the response).
In other words, http.ServeMux is a structure for routing.
ServeMux implements a method called ServeHTTP.
// ServeHTTP dispatches the request to the handler whose// pattern most closely matches the request URL.func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) { if r.RequestURI == "*" { if r.ProtoAtLeast(1, 1) { w.Header().Set("Connection", "close") } w.WriteHeader(StatusBadRequest) return } h, _ := mux.Handler(r) h.ServeHTTP(w, r)}cs.opensource.google - go1.17.2:src/net/http/server.go;l=2415
If you read the following part of ServeHTTP further, you will see the routing process of ServeHTTP.
h, _ := mux.Handler(r)If you jump through the code in order, you will arrive at a function that looks for and returns a matching handler.
// Find a handler on a handler map given a path string.// Most-specific (longest) pattern wins.func (mux *ServeMux) match(path string) (h Handler, pattern string) { // Check for exact match first. v, ok := mux.m[path] if ok { return v.h, v.pattern } // Check for longest valid match. mux.es contains all patterns // that end in / sorted from longest to shortest. for _, e := range mux.es { if strings.HasPrefix(path, e.pattern) { return e.h, e.pattern } } return nil, ""}If a matching handler is found, call ServeHTTP of that handler to invoke the process for the response.
That is the process at the end of the ServeHTTP method implemented in http.ServeMux.
h.ServeHTTP(w, r)In order to build your own HTTP router, you need to implement a multiplexer that satisfies the http.Handler type so that it can replace the standard multiplexer.
Registering a handler
The following code then registers a handler to the multiplexer.
mux.HandleFunc("/", handler)The handlers registered in the multiplexer must satisfy the http.Handler type.
package mainimport ( "fmt" "net/http")func main() { mux := http.NewServeMux() handler := foo{} mux.Handle("/", handler) http.ListenAndServe(":8080", mux)}type foo struct{}// Satisfy the http.Handler type by implementing ServeHTTP.func (f foo) ServeHTTP(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "Hello World")}Alternatively, a handler can be created by implementing the http.HandlerFunc type.
The http.HandlerFunc type is defined with func(ResponseWriter, *Request) as its type, and implements the ServeHTTP method.
// ServeHTTP calls f(w, r).func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) { f(w, r)}https://cs.opensource.google/go/go/+/refs/tags/go1.17.2:src/net/http/server.go;l=2045
Therefore, if you use the http.HandlerFunc type, you can create a handler as follows
package mainimport ( "fmt" "net/http")func main() { mux := http.NewServeMux() mux.Handle("/", http.HandlerFunc(handler)) http.ListenAndServe(":8080", mux)}func handler(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "Hello World")}When implementing HTTP routers, it is important to be aware of the implementation to support the http.Handler type, so that you can have flexibility in how you create handlers, making the package easier to handle.
Start the server
In the last code, we start the HTTP server by passing the port number and multiplexor to the function to start the server.
http.ListenAndServe(":8080", mux)Internally, ListenAndServe of type http.Server is called.
In this function, if the second argument is nil, the default http.DefaultServeMux is used.
This means that you don't need to bother generating multiplexers unless you want to extend them.
In implementing the HTTP router, I raised the code that would generate the multiplexer as an example because it was necessary as a prelude to the story.
Now that we have the necessary code reading for implementing the HTTP router, we will start explaining the implementation in the next chapter.
Column: Trailing Slash
The / at the end of a URL differs between the case at the end of a domain name and the case at the end of a subdirectory.
In the case of the last part of the domain name, if there is no /, general browsers will request the URL with /.
https://bmf-tech.com-> Request tohttps://bmf-tech.com/.https://bmf-tech.com/requestshttps://bmf-tech.com.
There is not much difference in the presence or absence of / at the end of a domain name, but there is a clear difference in the case of the end of a subdirectory.
https://bmf-tech.com/posts-> request to a filehttps://bmf-tech.com/posts/-> request for a directory
If you want to know more about the specification, please refer to the RFC.
In implementing HTTP routers, this is the part that you need to be concerned about in terms of how to interpret the path part of the URL.
In bmf-san/goblin developed by the author, the specification is that the presence or absence of trailing / is treated as the same routing definition.
Chapter 4 Implementing an HTTP Router
Now that we are ready to implement the HTTP router, we will explain the implementation.
This time, we will implement a router that is a little more sophisticated than the standard package.
Specifically, the router will have the following two features
- It will support method-based routing.
- It implements a tri-tree based algorithm.
With the standard package features, it is not possible to register routing by HTTP method.
If you want to do routing by HTTP method, you need to implement a conditional branch for each HTTP method in the handler.
// ex.func indexHandler(w http.ResponseWriter, r *http.Request) { switch r.Method { case http.MethodGet: // do something... case http.MethodPost: // do something... ... default:We will implement a function that allows defining routing on a per-method basis without defining such conditional branches in the handler.
As an algorithm for the HTTP router that can define routing on a method basis, we will adopt a tree structure based on the try tree described in the HTTP router data structure.
Preparation
The source code for the HTTP router we will implement is shown below.
bmf-san/introduction-to-golang-http-router-made-with-net-http
It is recommended that test code be written during the implementation process, but no explanation of the test code will be provided.
The same is true for CI.
We are using Golang version 1.17.
Implementation
The implementation procedure starts with implementing the algorithm for tri-tree based routing.
After that, we will implement the support for method-based routing.
Implementing a Tritree-based Routing Algorithm
Now let's get started with the implementation.
All the code to be implemented here can be found below.
bmf-san/introduction-to-golang-http-router-made-with-net-http/blob/main/trie.go
This time, we will adopt the following tree structure, which is a simplified version of the goblin data structure.

The route map represented by this tree structure is as follows.
| Request URL | Handler |
|---|---|
| GET / | IndexHandler |
| GET /foo | FooHandler |
| POST /foo | FooHandler |
| GET /foo/bar | FooBarHandler |
| GET /foo/bar/baz | FooBarBazHandler |
| GET /bar | BarHandler |
| GET /baz | BazHandler |
To represent the above tree structure, we will start writing by defining the necessary data.
Create a file named trie.go and define the structure.
package myrouter// tree is a trie tree.type tree struct { node *node}type node struct { label string actions map[string]*action // key is method children map[string]*node // key is a label o f next nodes}// action is an action.type action struct { handler http.Handler}// result is a search result.type result struct { actions *action}A tree is a tree itself, and a node is an element of the tree, with label, actions, and children.
label represents a URL path, actions represents a map of HTTP methods and handlers. children is a map of label and node, representing child nodes.
result represents the result of traversal from the tree.
Then, we define functions to generate these structures.
// newResult creates a new result.func newResult() *result { return &result{}}// NewTree creates a new trie tree.func NewTree() *tree { return &tree{ node: &node{ label: pathRoot, actions: make(map[string]*action), children: make(map[string]*node), }, }}Now, let's implement the part of adding a node to the tree.
Define the Insert method with tree as a pointer receiver.
func (t *tree) Insert(methods []string, path string, handler http.Handler)) { // }The key point of the arguments of this function is that the arguments are defined in such a way that multiple HTTP methods can be passed.
Not only is it possible to define a single handler for each HTTP method, but it is also possible to define the same handler for multiple methods.
// ex.func indexHandler(w http.ResponseWriter, r *http.Request) { switch r.Method { case http.MethodGet: // do something... case http.MethodPost: // do something... ... default:Depending on the implementation policy, there may be cases where you want to do conditional branching of HTTP methods in the handler, so we have made it versatile.
As for the contents of Insert, we first define the node to be the starting point as a variable.
func (t *tree) Insert(methods []string, path string, handler http.Handler)) { curNode := t.node}Next, handle the conditional branch when the target to be searched is / (root).
const ( pathRoot string = "/")func (t *tree) Insert(methods []string, path string, handler http.Handler)) { curNode := t.node if path == pathRoot { curNode.label = path for _, method := range methods { curNode.actions[method] = &action{ handler: handler, } } return nil }}In the case of /, there is no need to do any subsequent looping, so we will process here to add a node to the tree and exit.
If it is not /, continue processing.
The process is to break down the URL path by / and store the string of the path in a slice of type []string.
const ( ... pathDelimiter string = "/")func (t *tree) Insert(methods []string, path string, handler http.Handler)) { ... ep := explodePath(path) }// explodePath removes an empty value in slice.func explodePath(path string) []string { s := strings.Split(path, pathDelimiter) var r []string for _, str := range s { if str != "" { r = append(r, str) } } return r}[]The slice of type string is traversed by range to find the position to add the node.
The process here is based on the try tree implementation described in the HTTP router data structure.
When a child node is not found, a node is added.
If there is a case where the routing definitions overlap, it is handled in such a way that it becomes a post-win specification.
// Insert inserts a route definition to tree.func (t *tree) Insert(methods []string, path string, handler http.Handler) error { ... for i, p := range ep { nextNode, ok := curNode.children[p] if ok { curNode = nextNode } // Create a new node. if !ok { curNode.children[p] = &node{ label: p, actions: make(map[string]*action), children: make(map[string]*node), } curNode = curNode.children[p] } // last loop. // If there is already registered data, overwrite it. if i == len(ep)-1 { curNode.label = p for _, method := range methods { curNode.actions[method] = &action{ handler: handler, } } break } } return nil}The final implementation of Insert will look like this
// Insert inserts a route definition to tree.func (t *tree) Insert(methods []string, path string, handler http.Handler) error { curNode := t.node if path == pathRoot { curNode.label = path for _, method := range methods { curNode.actions[method] = &action{ handler: handler, } } return nil } ep := explodePath(path) for i, p := range ep { nextNode, ok := curNode.children[p] if ok { curNode = nextNode } // Create a new node. if !ok { curNode.children[p] = &node{ label: p, actions: make(map[string]*action), children: make(map[string]*node), } curNode = curNode.children[p] } // last loop. // If there is already registered data, overwrite it. if i == len(ep)-1 { curNode.label = p for _, method := range methods { curNode.actions[method] = &action{ handler: handler, } } break } } return nil}// explodePath removes an empty value in slice.func explodePath(path string) []string { s := strings.Split(path, pathDelimiter) var r []string for _, str := range s { if str != "" { r = append(r, str) } } return r}Now that we have implemented the process of inserting into the tree, we will implement the process of searching from the tree.
Since searching is relatively simple compared to insertion, we will explain it in one step.
func (t *tree) Search(method string, path string) (*result, error) { result := newResult() curNode := t.node if path != pathRoot { for _, p := range explodePath(path) { nextNode, ok := curNode.children[p] if !ok { if p == curNode.label { break } else { return nil, ErrNotFound } } curNode = nextNode continue } } result.actions = curNode.actions[method] if result.actions == nil { // no matching handler was found. return nil, ErrMethodNotAllowed } return result, nil}In the case of search, as in the case of insertion, whether or not to proceed to loop processing is determined by whether the URL path is / or not.
If you want to proceed to the loop processing, just look at the child nodes and search for the existence of the target node.
If the target node exists, it will look for a handler that matches the HTTP method of the request and return result.
Implementing support for method-based routing
The overall code to be implemented here is as follows.
bmf-san/introduction-to-golang-http-router-made-with-net-http/blob/main/router.go
In this section, we will also implement it to provide the functionality of an HTTP router.
The first step is to define the structure and the function to generate it.
// Router represents the router which handles routing.type Router struct { tree *tree}// route represents the route which has data for a routing.type route struct { methods []string path string handler http.Handler}func NewRouter() *Router { return &Router{ tree: NewTree(), }}Router is the http.ServeMux in net/http.
route contains data for routing definitions.
Next, we will implement the following three methods in Router.
...func (r *Router) Methods(methods ...string) *Router { tmpRoute.methods = append(tmpRoute.methods, methods...) return r}// Handler sets a handler.func (r *Router) Handler(path string, handler http.Handler) { tmpRoute.handler = handler tmpRoute.path = path r.Handle()}// Handle handles a route.func (r *Router) Handle() { r.tree.Insert(tmpRoute.methods, tmpRoute.path, tmpRoute.handler) tmpRoute = &route{}}Methods is a setter for HTTP methods, and Handler is a setter for URL paths and handlers that calls Handle. In Handle, we call the process of inserting into the tree that we just implemented.
The Methods and Handler are implemented as a method chain with readability in mind for the users of the HTTP router.
Method-based routing can be achieved with this in combination with trees.
The final step is to have the Router implement ServeHTTP and you are done.
...// ServeHTTP dispatches the request to the handler whose// pattern most closely matches the request URL.func (r *Router) ServeHTTP(w http.ResponseWriter, req *http.Request) { method := req.Method path := req.URL.Path result, err := r.tree.Search(method, path) if err != nil { status := handleErr(err) w.WriteHeader(status) return } h := result.actions.handler h.ServeHTTP(w, req)}func handleErr(err error) int { var status int switch err { case ErrMethodNotAllowed: status = http.StatusMethodNotAllowed case ErrNotFound: status = http.StatusNotFound } return status}Try to use the implemented HTTP router.
The HTTP router implemented in this project can be used as follows.
Start the server and make a request to each endpoint to see how it works.
package mainimport ( "fmt" "net/http" myroute "github.com/bmf-san/introduction-to-golang-http-router-made-with-net-http")func indexHandler() http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "GET /") })}func fooHandler() http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { switch r.Method { case http.MethodGet: fmt.Fprintf(w, "GET /foo") case http.MethodPost: fmt.Fprintf(w, "POST /foo") default: fmt.Fprintf(w, "Not Found") } })}func fooBarHandler() http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "GET /foo/bar") })}func fooBarBazHandler() http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "GET /foo/bar/baz") })}func barHandler() http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "GET /bar") })}func bazHandler() http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "GET /baz") })}func main() { r := myroute.NewRouter() r.Methods(http.MethodGet).Handler(`/`, indexHandler()) r.Methods(http.MethodGet, http.MethodPost).Handler(`/foo`, fooHandler()) r.Methods(http.MethodGet).Handler(`/foo/bar`, fooBarHandler()) r.Methods(http.MethodGet).Handler(`/foo/bar/baz`, fooBarBazHandler()) r.Methods(http.MethodGet).Handler(`/bar`, barHandler()) r.Methods(http.MethodGet).Handler(`/baz`, bazHandler()) http.ListenAndServe(":8080", r)}This was a bit of a rushed explanation of the implementation.
Column: HTTP router performance comparison
If you are interested in comparing the performance of HTTP routers, have a look at the following repository.
julienschmidt/go-http-routing-benchmark
The author has submitted a PR of goblin performance comparison to this repository.
Summary
In this article, I explained the approach to building your own HTTP router.
In Chapter 1, I explained what an HTTP router is an application that does.
In Chapter 2, I explained the data structure of HTTP routers with some examples.
In Chapter 3, I went deeper into the HTTP server code using net/http.
In Chapter 4, I explained how to implement an HTTP router with code.
I hope there is something useful or interesting in this article for the readers.
Also. I hope this article will be a good opportunity for you to have a look at the code of my work, bmf-san/goblin.
Please let me know if you have any questions, modification requests, or feedback.
Original Link: https://dev.to/bmf_san/introduction-to-golang-http-router-made-with-nethttp-3nmb
Dev To
More About this Source Visit Dev To