
An Interest In:
Web News this Week
- April 26, 2024
- April 25, 2024
- April 24, 2024
- April 23, 2024
- April 22, 2024
- April 21, 2024
- April 20, 2024
Some of Our Sources
- Engadget
- Mashable
- Just Creative
- Spoon Graphics
- Abduzeedo
- Creative Curio
- FanExtra - PSD
- Crazy Leaf Design
- Specky Boy
- Design Modo
Help Webnuz
Referal links:
Build an Article Recommendation Engine With AI/ML
Content platforms thrive on suggesting related content to their users. The more relevant items the platform can provide, the longer the user will stay on the site, which often translates to increased ad revenue for the company.
If youve ever visited a news website, online publication, or blogging platform, youve likely been exposed to a recommendation engine. Each of these takes input based on your reading history and then suggests more content you might like.
As a simple solution, a platform might implement a tag-based recommendation engine you read a Business article, so here are five more articles tagged Business. However, an even better approach to building a recommendation engine is to use similarity search and a machine learning algorithm.
In this article, well build a Python Flask app that uses Pinecone a similarity search service to create our very own article recommendation engine.
Demo App Overview
Below, you can see a brief animation of how our demo app works. Ten articles are initially displayed on the page. The user can choose any combination of those 10 articles to represent their reading history. When the user clicks the Submit button, the reading history is used as input to query the article database, and then 10 more related articles are displayed to the user.

As you can see, the related articles returned are exceptionally accurate! There are 1,024 possible combinations of reading history that can be used as input in this example, and every combination produces meaningful results.
So, how did we do it?
In building the app, we first found a dataset of news articles from Kaggle. This dataset contains 143,000 news articles from 15 major publications, but were just using the first 20,000. (The full dataset that this one is derived from contains over two million articles!)
We then cleaned up the dataset by renaming a couple columns and dropping those that are unnecessary. Next, we ran the articles through an embedding model to create vector embeddings thats metadata for machine learning algorithms to determine similarities between various inputs. We used the Average Word Embeddings Model. We then inserted these vector embeddings into a vector index managed by Pinecone.
With the vector embeddings added to the index, were ready to start finding related content. When users submit their reading history, a request is made to an API endpoint that uses Pinecones SDK to query the index of vector embeddings. The endpoint returns 10 similar news articles and displays them in the apps UI. Thats it! Simple enough, right?
If youd like to try it out for yourself, you can find the code for this app on GitHub. The README contains instructions for how to run the app locally on your own machine.
Demo App Code Walkthrough
Weve gone through the inner workings of the app, but how did we actually build it? As noted earlier, this is a Python Flask app that utilizes the Pinecone SDK. The HTML uses a template file, and the rest of the frontend is built using static CSS and JS assets. To keep things simple, all of the backend code is found in the app.py file, which weve reproduced in full below:
Lets go over the important parts of the app.py file so that we understand it.
On lines 114, we import our apps dependencies. Our app relies on the following:
dotenvfor reading environment variables from the.envfileflaskfor the web application setupjsonfor working with JSONosalso for getting environment variablespandasfor working with the datasetpineconefor working with the Pinecone SDKrefor working with regular expressions (RegEx)requestsfor making API requests to download our datasetstatisticsfor some handy stats methodssentence_transformersfor our embedding modelswifterfor working with the pandas dataframe
On line 16, we provide some boilerplate code to tell Flask the name of our app.
On lines 1820, we define some constants that will be used in the app. These include the name of our Pinecone index, the file name of the dataset, and the number of rows to read from the CSV file.
On lines 2225, our initialize_pinecone method gets our API key from the .env file and uses it to initialize Pinecone.
On lines 2729, our delete_existing_pinecone_index method searches our Pinecone instance for indexes with the same name as the one were using (article-recommendation-service). If an existing index is found, we delete it.
On lines 3135, our create_pinecone_index method creates a new index using the name we chose (article-recommendation-service), the cosine proximity metric, and only one shard.
On lines 3740, our create_model method uses the sentence_transformers library to work with the Average Word Embeddings Model. Well encode our vector embeddings using this model later.
On lines 6268, our process_file method reads the CSV file and then calls the prepare_data and upload_items methods on it. Those two methods are described next.
On lines 4256, our prepare_data method adjusts the dataset by renaming the first id column and dropping the date column. It then grabs the first four lines of each article and combines them with the article title to create a new field that serves as the data to encode. We could create vector embeddings based on the entire body of the article, but four lines will suffice in order to speed up the encoding process.
On lines 5860, our upload_items method creates a vector embedding for each article by encoding it using our model. The vector embeddings are then inserted into the Pinecone index.
On lines 7074, our map_titles and map_publications methods create some dictionaries of the titles and publication names to make it easier to find articles by their IDs later.
Each of the methods weve described so far is called on lines 98104 when the backend app is started. This work prepares us for the final step of actually querying the Pinecone index based on user input.
On lines 106116, we define two routes for our app: one for the home page and one for the API endpoint. The home page serves up the index.html template file along with the JS and CSS assets, and the API endpoint provides the search functionality for querying the Pinecone index.
Finally, on lines 7696, our query_pinecone method takes the users reading history input, converts it into a vector embedding, and then queries the Pinecone index to find similar articles. This method is called when the /api/search endpoint is hit, which occurs any time the user submits a new search query.
For the visual learners out there, heres a diagram outlining how the app works:
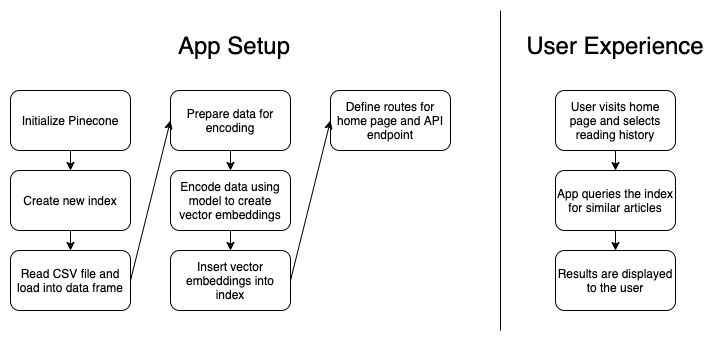
Example Scenarios
So, putting this all together, what does the user experience look like? Lets look at three scenarios: a user interested in sports, a user interested in technology, and a user interested in politics.
The sports user selects the first two articles about Serena Williams and Andy Murray, two famous tennis players, to use as their reading history. After they submit their choices, the app responds with articles about Wimbledon, the US Open, Roger Federer, and Rafael Nadal. Spot on!
The technology user selects articles about Samsung and Apple. After they submit their choices, the app responds with articles about Samsung, Apple, Google, Intel, and iPhones. Great recommendations again!
The politics user selects a single article about voter fraud. After they submit their choice, the app responds with articles about voter ID, the US 2020 election, voter turnout, and claims of illegal voting (and why they dont hold up).
Three for three! Our recommendation engine is proving to be incredibly useful.
Conclusion
Weve now created a simple Python app to solve a real-world problem. If content sites can recommend relevant content to their users, users will enjoy the content more and will spend more time on the site, resulting in more revenue for the company. Everyone wins!
Similarity search helps provide better suggestions for your users. And Pinecone, as a similarity search service, makes it easy for you to provide recommendations to your users so that you can focus on what you do best building an engaging platform filled with content worth reading.
Original Link: https://dev.to/thawkin3/build-an-article-recommendation-engine-with-ai-ml-omc
Dev To
More About this Source Visit Dev To