
An Interest In:
Web News this Week
- April 26, 2024
- April 25, 2024
- April 24, 2024
- April 23, 2024
- April 22, 2024
- April 21, 2024
- April 20, 2024
Some of Our Sources
- Technology Review
- Spoon Graphics
- Vandelay Design
- FanExtra - PSD
- Crazy Leaf Design
- Reencoded
- Line 25
- Spyre Studios
- Freelance Switch
- Web Resource Source
Help Webnuz
Referal links:
How to Build a RegEx Engine in Python (Part 2: The Lexer)
In the previous article, we spoke about grammar and what we need to complete this project.
Its now time to finally dig into the coding part.
Set Up The Environment
To set up the environment we first need to create a folder for the project and the virtualenv well use for it.
mkdir pyregex cd pyregexpython3 -m venv venv source venv/bin/activateFor this project, we will use a couple of python libraries:
pip3 install numpy pip3 install autopep8Autopep8 isnt needed for the project itself, but I use it to help me with keeping formatting uniform throughout the codebase.
On the other hand, well use NumPy to build the AST.
The Folder Structure
Inside pyregex, we create an src folder where we will place all our code.
The __init__.py files you see are empty files needed by python to navigate through the project.

Building The Lexer
What Is a Lexer
A Lexer (or Scanner) is a component that takes a string as input and outputs a list (array, or whatever) of tokens, i.e. category of words, logical tokens, of a grammar.
A brief example:
Input string:

English language lexer output:
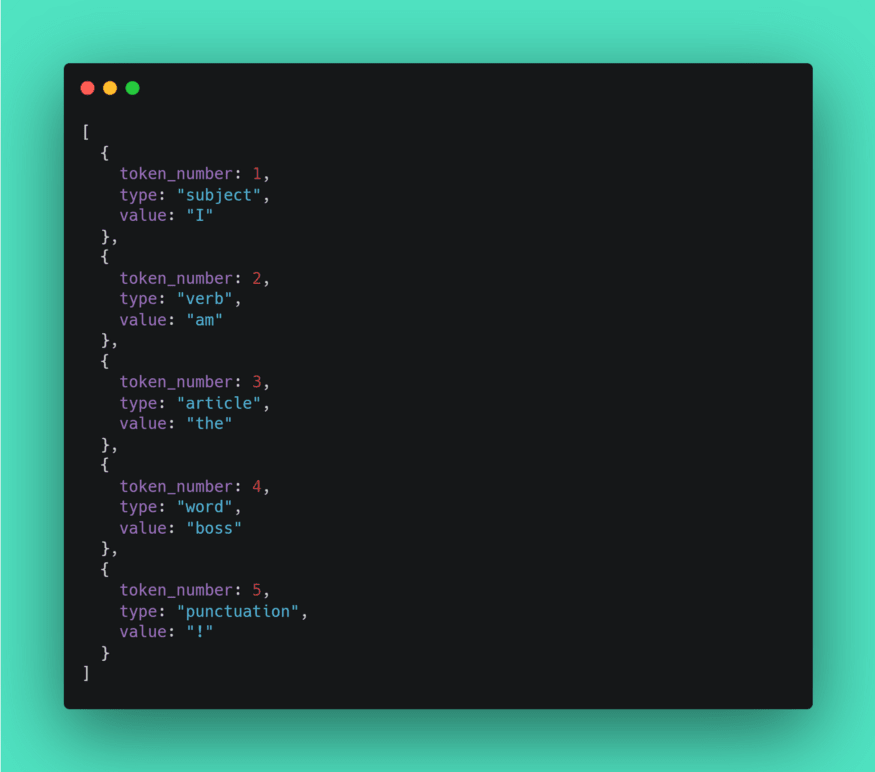
The Tokens
Our lexer will have to recognize different types of tokens (character, parenthesis, brackets, escape, ).
To do so we first need to define a hierarchy of tokens types.
In the list above you can see the hierarchy of tokens were going to create and a few implemented token classes. (Remember that the complete code is available here).
For many of the tokens, I created first a base class to represent the type and then more specialized ones for the actual char we choose to be the one representing the type.
This wasnt strictly necessary, but adds not much work and may help you keep the code coherent and makes it easy to overload token types (maybe one day I will want # to be an escape too for some reason).
Finally the Lexer
The lexer itself is a quite simple component.
In a file named lexer.py, we create the class Lexer which will implement the scan method that will take a string as input and outputs a NumPy array of the tokens recognized.
To recognize the tokens the Lexer iterate through each character of the input string and assigns it the corresponding token.
As you can see it is pretty straightforward. The only two tricky points are the handling of the escape, ^ and curly brace.
The escape
To handle the escape I created a support variable escape_found which is set to false at the end of each while loop.
When an escape its actually found, the variable is set to true and the continue clause immediately after restarting the loop without setting it to false again. Thanks to this, in the next iteration, the variable value would be true, thus triggering the specific condition (if escape_found).
The code specific to the condition is then executed and, since there is no continuity, the end of the loop code is reached and escape_found is set again to false.
The ^
This is by far the most interesting in my opinion because the reality is that, unless you find it as the first character, you cant be sure if what you found is a negation, like in [^abc] (i.e. match a char that is anything but a, b, or a match start token in a subsequent regex, like in ^abc$|^012$ .
Since this is impossible to tell, in our implementation each ^ after index 0 is recognized by the lexer as a Circumflex (NotToken), and then it will be the parser to have the final word on the question.
The Left curly brace
When a left curly brace { is met, we enter to a kind of sub-grammar that recognizes the quantifier {min, max} (with min or max eventually omitted).
Thus, the number of allowed tokens tightens, and it is always good to recognize early badly formatted regexes.
Because, if you can eliminate some grammar errors in the Lexer, which is fairly simple, you wont have to check for the same error again in the Parser, which is already more complex by itself, reducing (by a tiny bit) the complexity of it.
Conclusion
As you probably noted, the Lexer is a very simple component to design and implement.
Harder times will come as well design and implement the Parser, and even harder with the engine (and the backtracking system above all).
I hope you enjoyed reading this article. For this part I think we did enough, dont hesitate to ask me questions if something isnt clear to you, Ill be glad to answer any questions!
Cover Image by on Unsplash
Original Link: https://dev.to/lorenzofelletti/how-to-build-a-regex-engine-in-python-part-2-the-lexer-2b4n
Dev To
More About this Source Visit Dev To