
An Interest In:
Web News this Week
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
Some of Our Sources
- Engadget
- Mashable
- Just Creative
- Pearsonified
- Smashing Magazine
- TutsPlus - Design
- Fuel Your Creativity
- Web Designer Depot
- 24 Ways
- CSS Tricks
Help Webnuz
Referal links:
Auto-generate video summaries with a machine learning model and a serverless pipeline
Source code:
PicardParis / cherry-on-py
Auto-generate visual summaries of videos, with a machine learning model and a serverless pipeline
Hello!
Dear developers,
- Do you like the adage "a picture is worth a thousand words"? I do!
- Let's check if it also works for "a picture is worth a thousand frames".
- In this tutorial, you'll see the following:
- how to understand the content of a video in a blink,
- in less than 300 lines of Python (3.7) code.
Here is a visual summary example, generated from a 2'42" video made of 35 sequences (shots):

Note: The summary is a grid where each cell is a frame representing a video shot.
Objectives
This tutorial has 2 objectives, 1 practical and 1 technical:
- Automatically generate visual summaries of videos
- Build a processing pipeline with these properties:
- managed (always ready and easy to set up)
- scalable (able to ingest several videos in parallel)
- not costing anything when not used
Tools
A few tools are enough:
- Storage space for videos and results
- A serverless solution to run the code
- A machine learning model to analyze videos
- A library to extract frames from videos
- A library to generate the visual summaries
Architecture
Here is a possible architecture using 3 Google Cloud services (Cloud Storage, Cloud Functions, and Video Intelligence API):

The processing pipeline follows these steps:
- You upload a video to the 1st bucket (a bucket is a storage space in the cloud)
- The upload event automatically triggers the 1st function
- The function sends a request to the Video Intelligence API to detect the shots
- The Video Intelligence API analyzes the video and uploads the results (annotations) to the 2nd bucket
- The upload event triggers the 2nd function
- The function downloads both annotation and video files
- The function renders and uploads the summary to the 3rd bucket
- The video summary is ready!
Python libraries
Open source client libraries let you interface with Google Cloud services in idiomatic Python. You'll use the following:
Cloud Storage- To manage downloads and uploads
- https://pypi.org/project/google-cloud-storage
Video Intelligence API- To analyze videos
- https://pypi.org/project/google-cloud-videointelligence
Here is a choice of 2 additional Python libraries for the graphical needs:
OpenCV- To extract video frames
- There's even a headless version (without GUI features), which is ideal for a service
- https://pypi.org/project/opencv-python-headless
Pillow- To generate the visual summaries
Pillowis a very popular imaging library, both extensive and easy to use- https://pypi.org/project/Pillow
Project setup
Assuming you have a Google Cloud account, you can set up the architecture from Cloud Shell with the gcloud and gsutil commands. This lets you script everything from scratch in a reproducible way.
Environment variables
# ProjectPROJECT_NAME="Visual Summary"PROJECT_ID="visual-summary-REPLACE_WITH_UNIQUE_SUFFIX"# Cloud Storage region (https://cloud.google.com/storage/docs/locations)GCS_REGION="europe-west1"# Cloud Functions region (https://cloud.google.com/functions/docs/locations)GCF_REGION="europe-west1"# SourceGIT_REPO="cherry-on-py"PROJECT_SRC=~/$PROJECT_ID/$GIT_REPO/gcf_video_summary# Cloud Storage buckets (environment variables)export VIDEO_BUCKET="b1-videos_${PROJECT_ID}"export ANNOTATION_BUCKET="b2-annotations_${PROJECT_ID}"export SUMMARY_BUCKET="b3-summaries_${PROJECT_ID}"Note: You can use your GitHub username as a unique suffix.
New project
gcloud projects create $PROJECT_ID \ --name="$PROJECT_NAME" \ --set-as-defaultCreate in progress for [https://cloudresourcemanager.googleapis.com/v1/projects/PROJECT_ID].Waiting for [operations/cp...] to finish...done.Enabling service [cloudapis.googleapis.com] on project [PROJECT_ID]...Operation "operations/acf..." finished successfully.Updated property [core/project] to [PROJECT_ID].Billing account
# Link project with billing account (single account)BILLING_ACCOUNT=$(gcloud beta billing accounts list \ --format 'value(name)')# Link project with billing account (specific one among multiple accounts)BILLING_ACCOUNT=$(gcloud beta billing accounts list \ --format 'value(name)' \ --filter "displayName='My Billing Account'")gcloud beta billing projects link $PROJECT_ID --billing-account $BILLING_ACCOUNTbillingAccountName: billingAccounts/XXXXXX-YYYYYY-ZZZZZZbillingEnabled: truename: projects/PROJECT_ID/billingInfoprojectId: PROJECT_IDBuckets
# Create buckets with uniform bucket-level accessgsutil mb -b on -c regional -l $GCS_REGION gs://$VIDEO_BUCKETgsutil mb -b on -c regional -l $GCS_REGION gs://$ANNOTATION_BUCKETgsutil mb -b on -c regional -l $GCS_REGION gs://$SUMMARY_BUCKETCreating gs://VIDEO_BUCKET/...Creating gs://ANNOTATION_BUCKET/...Creating gs://SUMMARY_BUCKET/...You can check how it looks like in the Cloud Console:

Service account
Create a service account. This is for development purposes only (not needed for production). This provides you with credentials to run your code locally.
mkdir ~/$PROJECT_IDcd ~/$PROJECT_IDSERVICE_ACCOUNT_NAME="dev-service-account"SERVICE_ACCOUNT="${SERVICE_ACCOUNT_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"gcloud iam service-accounts create $SERVICE_ACCOUNT_NAMEgcloud iam service-accounts keys create ~/$PROJECT_ID/key.json --iam-account $SERVICE_ACCOUNTCreated service account [SERVICE_ACCOUNT_NAME].created key [...] of type [json] as [~/PROJECT_ID/key.json] for [SERVICE_ACCOUNT]Set the GOOGLE_APPLICATION_CREDENTIALS environment variable and check that it points to the service account key. When you run the application code in the current shell session, client libraries will use these credentials for authentication. If you open a new shell session, set the variable again.
export GOOGLE_APPLICATION_CREDENTIALS=~/$PROJECT_ID/key.jsoncat $GOOGLE_APPLICATION_CREDENTIALS{ "type": "service_account", "project_id": "PROJECT_ID", "private_key_id": "...", "private_key": "-----BEGIN PRIVATE KEY-----\n...", "client_email": "SERVICE_ACCOUNT", ...}Authorize the service account to access the buckets:
IAM_BINDING="serviceAccount:${SERVICE_ACCOUNT}:roles/storage.objectAdmin"gsutil iam ch $IAM_BINDING gs://$VIDEO_BUCKETgsutil iam ch $IAM_BINDING gs://$ANNOTATION_BUCKETgsutil iam ch $IAM_BINDING gs://$SUMMARY_BUCKETAPIs
A few APIs are enabled by default:
gcloud services listNAME TITLEbigquery.googleapis.com BigQuery APIbigquerystorage.googleapis.com BigQuery Storage APIcloudapis.googleapis.com Google Cloud APIsclouddebugger.googleapis.com Cloud Debugger APIcloudtrace.googleapis.com Cloud Trace APIdatastore.googleapis.com Cloud Datastore APIlogging.googleapis.com Cloud Logging APImonitoring.googleapis.com Cloud Monitoring APIservicemanagement.googleapis.com Service Management APIserviceusage.googleapis.com Service Usage APIsql-component.googleapis.com Cloud SQLstorage-api.googleapis.com Google Cloud Storage JSON APIstorage-component.googleapis.com Cloud StorageEnable the Video Intelligence and Cloud Functions APIs:
gcloud services enable \ videointelligence.googleapis.com \ cloudfunctions.googleapis.comOperation "operations/acf..." finished successfully.Source code
Retrieve the source code:
cd ~/$PROJECT_IDgit clone https://github.com/PicardParis/$GIT_REPO.gitCloning into 'GIT_REPO'......Video analysis
Video shot detection
The Video Intelligence API is a pre-trained machine learning model that can analyze videos. One of the multiple features is video shot detection. For the 1st Cloud Function, here is a possible core function calling annotate_video() with the SHOT_CHANGE_DETECTION feature:
from google.cloud import storage, videointelligencedef launch_shot_detection(video_uri: str, annot_bucket: str): """ Detect video shots (asynchronous operation) Results will be stored in <annot_uri> with this naming convention: - video_uri: gs://video_bucket/path/to/video.ext - annot_uri: gs://annot_bucket/video_bucket/path/to/video.ext.json """ print(f'Launching shot detection for <{video_uri}>...') video_blob = storage.Blob.from_string(video_uri) video_bucket = video_blob.bucket.name path_to_video = video_blob.name annot_uri = f'gs://{annot_bucket}/{video_bucket}/{path_to_video}.json' video_client = videointelligence.VideoIntelligenceServiceClient() features = [videointelligence.enums.Feature.SHOT_CHANGE_DETECTION] video_client.annotate_video(input_uri=video_uri, features=features, output_uri=annot_uri)Local development and tests
Before deploying the function, you need to develop and test it. Create a Python 3 virtual environment and activate it:
cd ~/$PROJECT_IDpython3 -m venv venvsource venv/bin/activateInstall the dependencies:
pip install -r $PROJECT_SRC/gcf1_detect_shots/requirements.txtCheck the dependencies:
pip listPackage Version------------------------------ ----------...google-cloud-storage 1.28.1google-cloud-videointelligence 1.14.0...You can use the main scope to test the function in script mode:
import osANNOTATION_BUCKET = os.getenv('ANNOTATION_BUCKET', '')assert ANNOTATION_BUCKET, 'Undefined ANNOTATION_BUCKET environment variable'if __name__ == '__main__': """ Only for local tests """ import argparse parser = argparse.ArgumentParser() parser.add_argument('video_uri', type=str, help='gs://video_bucket/path/to/video.ext') args = parser.parse_args() launch_shot_detection(args.video_uri, ANNOTATION_BUCKET)Note: You have already exported the
ANNOTATION_BUCKETenvironment variable earlier in the shell session; you will also define it later at deployment stage. This makes the code generic and lets you reuse it independently of the output bucket.
Test the function:
VIDEO_PATH="cloudmleap/video/next/gbikes_dinosaur.mp4"VIDEO_URI="gs://$VIDEO_PATH"python $PROJECT_SRC/gcf1_detect_shots/main.py $VIDEO_URILaunching shot detection for <gs://cloudmleap/video/next/gbikes_dinosaur.mp4>...Note: The test video
<gbikes_dinosaur.mp4>is located in an external bucket. This works because the video is publicly accessible.
Wait a moment and check that the annotations have been generated:
gsutil ls -r gs://$ANNOTATION_BUCKET964 YYYY-MM-DDThh:mm:ssZ gs://ANNOTATION_BUCKET/VIDEO_PATH.jsonTOTAL: 1 objects, 964 bytes (964 B)Check the last 200 bytes of the annotation file:
gsutil cat -r -200 gs://$ANNOTATION_BUCKET/$VIDEO_PATH.json} }, { "start_time_offset": { "seconds": 28, "nanos": 166666000 }, "end_time_offset": { "seconds": 42, "nanos": 766666000 } } ] } ]}Note: Those are the start and end positions of the last video shot. Everything seems fine.
Clean up when you're finished:
gsutil rm gs://$ANNOTATION_BUCKET/$VIDEO_PATH.jsondeactivaterm -rf venvFunction entry point
def gcf_detect_shots(data, context): """ Cloud Function triggered by a new Cloud Storage object """ video_bucket = data['bucket'] path_to_video = data['name'] video_uri = f'gs://{video_bucket}/{path_to_video}' launch_shot_detection(video_uri, ANNOTATION_BUCKET)Note: This function will be called whenever a video is uploaded to the bucket defined as a trigger.
Function deployment
Deploy the 1st function:
GCF_NAME="gcf1_detect_shots"GCF_SOURCE="$PROJECT_SRC/gcf1_detect_shots"GCF_ENTRY_POINT="gcf_detect_shots"GCF_TRIGGER_BUCKET="$VIDEO_BUCKET"GCF_ENV_VARS="ANNOTATION_BUCKET=$ANNOTATION_BUCKET"GCF_MEMORY="128MB"gcloud functions deploy $GCF_NAME \ --runtime python37 \ --source $GCF_SOURCE \ --entry-point $GCF_ENTRY_POINT \ --update-env-vars $GCF_ENV_VARS \ --trigger-bucket $GCF_TRIGGER_BUCKET \ --region $GCF_REGION \ --memory $GCF_MEMORY \ --quietNote: The default memory allocated for a Cloud Function is 256 MB (possible values are 128MB, 256MB, 512MB, 1024MB, and 2048MB). As the function has no memory or CPU needs (it sends a simple API request), the minimum memory setting is enough.
Deploying function (may take a while - up to 2 minutes)...done.availableMemoryMb: 128entryPoint: gcf_detect_shotsenvironmentVariables: ANNOTATION_BUCKET: b2-annotations...eventTrigger: eventType: google.storage.object.finalize...status: ACTIVEtimeout: 60supdateTime: 'YYYY-MM-DDThh:mm:ss.mmmZ'versionId: '1'Note: The
ANNOTATION_BUCKETenvironment variable is defined with the--update-env-varsflag. Using an environment variable lets you deploy the exact same code with different trigger and output buckets.
Here is how it looks like in the Cloud Console:

Production tests
Make sure to test the function in production. Copy a video into the video bucket:
VIDEO_NAME="gbikes_dinosaur.mp4"SRC_URI="gs://cloudmleap/video/next/$VIDEO_NAME"DST_URI="gs://$VIDEO_BUCKET/$VIDEO_NAME"gsutil cp $SRC_URI $DST_URICopying gs://cloudmleap/video/next/gbikes_dinosaur.mp4 [Content-Type=video/mp4]...- [1 files][ 62.0 MiB/ 62.0 MiB]Operation completed over 1 objects/62.0 MiB.Query the logs to check that the function has been triggered:
gcloud functions logs read --region $GCF_REGIONLEVEL NAME EXECUTION_ID TIME_UTC LOGD gcf1_detect_shots ... ... Function execution startedI gcf1_detect_shots ... ... Launching shot detection for <gs://VIDEO_BUCKET/VIDEO_NAME>...D gcf1_detect_shots ... ... Function execution took 874 ms, finished with status: 'ok'Wait a moment and check the annotation bucket:
gsutil ls -r gs://$ANNOTATION_BUCKETYou should see the annotation file:
gs://ANNOTATION_BUCKET/VIDEO_BUCKET/:gs://ANNOTATION_BUCKET/VIDEO_BUCKET/VIDEO_NAME.jsonThe 1st function is operational!
Visual Summary
Code structure
It's interesting to split the code into 2 main classes:
StorageHelperfor local file and cloud storage object managementVideoProcessorfor graphical processings
Here is a possible core function:
class VideoProcessor: @staticmethod def generate_summary(annot_uri: str, output_bucket: str): """ Generate a video summary from video shot annotations """ try: with StorageHelper(annot_uri, output_bucket) as storage: with VideoProcessor(storage) as video_proc: print('Generating summary...') image = video_proc.render_summary() video_proc.upload_summary_as_jpeg(image) except: logging.exception( 'Could not generate summary from shot annotations <%s>', annot_uri)Note: If exceptions are raised, it's handy to log them with
logging.exception()to get a stack trace in production logs.
Class StorageHelper
The class manages the following:
- The retrieval and parsing of video shot annotations
- The download of source videos
- The upload of generated visual summaries
- File names
class StorageHelper: """ Local+Cloud storage helper - Uses a temp dir for local processing (e.g. video frame extraction) - Paths are relative to this temp dir (named after the output bucket) Naming convention: - video_uri: gs://video_bucket/path/to/video.ext - annot_uri: gs://annot_bucket/video_bucket/path/to/video.ext.json - video_path: video_bucket/path/to/video.ext - summary_path: video_bucket/path/to/video.ext.SUFFIX - summary_uri: gs://output_bucket/video_bucket/path/to/video.ext.SUFFIX """ client = storage.Client() upload_bucket: storage.Bucket shots: 'VideoShots' video_path: Path video_local_path: Path ANNOT_EXT = '.json' VideoShots = List[VideoShot] def __init__(self, annot_uri: str, output_bucket: str): if not annot_uri.endswith(self.ANNOT_EXT): raise RuntimeError(f'annot_uri must end with <{self.ANNOT_EXT}>') self.upload_bucket = self.client.bucket(output_bucket) self.shots = self.load_annotations(annot_uri) self.video_path = self.video_path_from_uri(annot_uri) temp_root = Path(tempfile.gettempdir(), output_bucket) temp_root.mkdir(parents=True, exist_ok=True) self.video_local_path = temp_root.joinpath(self.video_path)The source video is handled in the with statement context manager:
def __enter__(self): self.download_video() return self def __exit__(self, exc_type, exc_value, traceback): self.video_local_path.unlink()Note: Once downloaded, the video uses memory space in the
/tmpRAM disk (the only writable space for the serverless function). It's best to delete temporary files when they're not needed anymore, to avoid potential out-of-memory errors on future invocations of the function.
Annotations are retrieved with the methods storage.Blob.download_as_string() and json.loads():
def load_annotations(self, annot_uri: str) -> VideoShots: json_blob = storage.Blob.from_string(annot_uri, self.client) api_response = json.loads(json_blob.download_as_string()) annotations: Dict = api_response['annotation_results'][0]['shot_annotations'] return [VideoShot.from_dict(annotation) for annotation in annotations]The parsing is handled with this VideoShot helper class:
class VideoShot(NamedTuple): """ Video shot start/end positions in nanoseconds """ pos1_ns: int pos2_ns: int NANOS_PER_SECOND = 10**9 @classmethod def from_dict(cls, annotation: Dict) -> 'VideoShot': def time_offset_in_ns(time_offset) -> int: seconds: int = time_offset.get('seconds', 0) nanos: int = time_offset.get('nanos', 0) return seconds * cls.NANOS_PER_SECOND + nanos pos1_ns = time_offset_in_ns(annotation['start_time_offset']) pos2_ns = time_offset_in_ns(annotation['end_time_offset']) return cls(pos1_ns, pos2_ns)Video shot info can be exposed with a getter and a generator:
def shot_count(self) -> int: return len(self.shots) def gen_video_shots(self) -> Iterator[VideoShot]: for video_shot in self.shots: yield video_shotThe naming convention was chosen to keep consistent object paths between the different buckets. This also lets you deduce the video path from the annotation URI:
def video_path_from_uri(self, annot_uri: str) -> Path: annot_blob = storage.Blob.from_string(annot_uri) return Path(annot_blob.name[:-len(self.ANNOT_EXT)])The video is directly downloaded with storage.Blob.download_to_filename():
def download_video(self): video_uri = f'gs://{self.video_path.as_posix()}' blob = storage.Blob.from_string(video_uri, self.client) print(f'Downloading -> {self.video_local_path}') self.video_local_path.parent.mkdir(parents=True, exist_ok=True) blob.download_to_filename(self.video_local_path)On the opposite, results can be uploaded with storage.Blob.upload_from_string():
def upload_summary(self, image_bytes: bytes, image_type: str): path = self.summary_path(image_type) blob = self.upload_bucket.blob(path.as_posix()) content_type = f'image/{image_type}' print(f'Uploading -> {blob.name}') blob.upload_from_string(image_bytes, content_type)Note:
from_stringmeansfrom_byteshere (Python 2 legacy).Pillowsupports working with memory images, which avoids having to manage local files.
And finally, here is a possible naming convention for the summary files:
def summary_path(self, image_type: str) -> Path: video_name = self.video_path.name shot_count = self.shot_count() suffix = f'summary{shot_count:03d}.{image_type}' summary_name = f'{video_name}.{suffix}' return Path(self.video_path.parent, summary_name) Class VideoProcessor
The class manages the following:
- Video frame extraction
- Visual summary generation
import cv2 as cvfrom PIL import Imagefrom storage_helper import StorageHelperclass VideoProcessor: class ImageSize(NamedTuple): w: int h: int storage: StorageHelper video: cv.VideoCapture cell_size: ImageSize grid_size: ImageSize def __init__(self, storage: StorageHelper): self.storage = storageOpening and closing the video is handled in the with statement context manager:
def __enter__(self): video_path = self.storage.video_local_path self.video = cv.VideoCapture(str(video_path)) if not self.video.isOpened(): raise RuntimeError(f'Could not open video <{video_path}>') self.compute_grid_dimensions() return self def __exit__(self, exc_type, exc_value, traceback): self.video.release()The video summary is a grid of cells which can be rendered in a single loop with two generators:
def render_summary(self, shot_ratio: float = 0.5) -> Image: grid_img = Image.new('RGB', self.grid_size, self.RGB_BACKGROUND) img_and_pos_iter = zip(self.gen_cell_img(shot_ratio), self.gen_cell_pos()) for cell_img, cell_pos in img_and_pos_iter: cell_img.thumbnail(self.cell_size) # Make it smaller if needed grid_img.paste(cell_img, cell_pos) return grid_imgNote:
shot_ratiois set to0.5by default to extract video shot middle frames.
The first generator yields cell images:
def gen_cell_img(self, shot_ratio: float) -> Iterator['Image']: assert 0.0 <= shot_ratio <= 1.0 MS_IN_NS = 10**6 for video_shot in self.storage.gen_video_shots(): pos1_ns, pos2_ns = video_shot pos_ms = (pos1_ns + shot_ratio*(pos2_ns-pos1_ns)) / MS_IN_NS yield self.image_at_pos(pos_ms)The second generator yields cell positions:
def gen_cell_pos(self) -> Iterator[Tuple[int, int]]: cell_x, cell_y = 0, 0 while True: yield cell_x, cell_y cell_x += self.cell_size.w if self.grid_size.w <= cell_x: # Move to next row? cell_x, cell_y = 0, cell_y+self.cell_size.hOpenCV easily allows extracting video frames at a given position:
def image_at_pos(self, pos_ms: float) -> Image: self.video.set(cv.CAP_PROP_POS_MSEC, pos_ms) ok, cv_frame = self.video.read() if not ok: raise RuntimeError(f'Failed to get video frame @pos_ms[{pos_ms}]') return Image.fromarray(cv.cvtColor(cv_frame, cv.COLOR_BGR2RGB))Choosing the summary grid composition is arbitrary. Here is an example to compose a summary preserving the video proportions:
def compute_grid_dimensions(self): shot_count = self.storage.shot_count() if shot_count < 1: raise RuntimeError(f'Expected 1+ video shots (got {shot_count})') # Try to preserve the video aspect ratio # Consider cells as pixels and try to fit them in a square cols = rows = int(shot_count ** 0.5 + 0.5) if cols * rows < shot_count: cols += 1 cell_w = int(self.video.get(cv.CAP_PROP_FRAME_WIDTH)) cell_h = int(self.video.get(cv.CAP_PROP_FRAME_HEIGHT)) if self.SUMMARY_MAX_SIZE.w < cell_w*cols: scale = self.SUMMARY_MAX_SIZE.w / (cell_w*cols) cell_w = int(scale * cell_w) cell_h = int(scale * cell_h) self.cell_size = self.ImageSize(cell_w, cell_h) self.grid_size = self.ImageSize(cell_w*cols, cell_h*rows)Finally, Pillow gives full control on image serializations:
def upload_summary_as_jpeg(self, image: Image): mem_file = BytesIO() image_type = 'jpeg' jpeg_save_parameters = dict(optimize=True, progressive=True) image.save(mem_file, format=image_type, **jpeg_save_parameters) image_bytes = mem_file.getvalue() self.storage.upload_summary(image_bytes, image_type)Note: Working with in-memory images avoids managing local files and uses less memory.
Local development and tests
You can use the main scope to test the function in script mode:
import osfrom video_processor import VideoProcessorSUMMARY_BUCKET = os.getenv('SUMMARY_BUCKET', '')assert SUMMARY_BUCKET, 'Undefined SUMMARY_BUCKET environment variable'if __name__ == '__main__': """ Only for local tests """ import argparse parser = argparse.ArgumentParser() parser.add_argument('annot_uri', type=str, help='gs://annotation_bucket/path/to/video.ext.json') args = parser.parse_args() VideoProcessor.generate_summary(args.annot_uri, SUMMARY_BUCKET)Test the function:
cd ~/$PROJECT_IDpython3 -m venv venvsource venv/bin/activatepip install -r $PROJECT_SRC/gcf2_generate_summary/requirements.txtVIDEO_NAME="gbikes_dinosaur.mp4"ANNOTATION_URI="gs://$ANNOTATION_BUCKET/$VIDEO_BUCKET/$VIDEO_NAME.json"python $PROJECT_SRC/gcf2_generate_summary/main.py $ANNOTATION_URIDownloading -> /tmp/SUMMARY_BUCKET/VIDEO_BUCKET/VIDEO_NAMEGenerating summary...Uploading -> VIDEO_BUCKET/VIDEO_NAME.summary004.jpegNote: The uploaded video summary shows 4 shots.
Clean up:
deactivaterm -rf venvFunction entry point
def gcf_generate_summary(data, context): """ Cloud Function triggered by a new Cloud Storage object """ annotation_bucket = data['bucket'] path_to_annotation = data['name'] annot_uri = f'gs://{annotation_bucket}/{path_to_annotation}' VideoProcessor.generate_summary(annot_uri, SUMMARY_BUCKET)Note: This function will be called whenever an annotation file is uploaded to the bucket defined as a trigger.
Function deployment
GCF_NAME="gcf2_generate_summary"GCF_SOURCE="$PROJECT_SRC/gcf2_generate_summary"GCF_ENTRY_POINT="gcf_generate_summary"GCF_TRIGGER_BUCKET="$ANNOTATION_BUCKET"GCF_ENV_VARS="SUMMARY_BUCKET=$SUMMARY_BUCKET"GCF_TIMEOUT="540s"GCF_MEMORY="512MB"gcloud functions deploy $GCF_NAME \ --runtime python37 \ --source $GCF_SOURCE \ --entry-point $GCF_ENTRY_POINT \ --update-env-vars $GCF_ENV_VARS \ --trigger-bucket $GCF_TRIGGER_BUCKET \ --region $GCF_REGION \ --timeout $GCF_TIMEOUT \ --memory $GCF_MEMORY \ --quietNotes:
- The default timeout for a Cloud Function is 60 seconds. As you're deploying a background function with potentially long processings, set it to the maximum value (540 seconds = 9 minutes).
- You also need to bump up the memory a little for the video and image processings. Depending on the size of your videos and the maximum resolution of your output summaries, or if you need to generate the summary faster (memory size and vCPU speed are correlated), you might use a higher value (1024MB or 2048MB).
Deploying function (may take a while - up to 2 minutes)...done.availableMemoryMb: 512entryPoint: gcf_generate_summaryenvironmentVariables: SUMMARY_BUCKET: b3-summaries......status: ACTIVEtimeout: 540supdateTime: 'YYYY-MM-DDThh:mm:ss.mmmZ'versionId: '1'Here is how it looks like in the Cloud Console:

Production tests
Make sure to test the function in production. You can upload an annotation file in the 2nd bucket:
VIDEO_NAME="gbikes_dinosaur.mp4"ANNOTATION_FILE="$VIDEO_NAME.json"ANNOTATION_URI="gs://$ANNOTATION_BUCKET/$VIDEO_BUCKET/$ANNOTATION_FILE"gsutil cp $ANNOTATION_URI .gsutil cp $ANNOTATION_FILE $ANNOTATION_URIrm $ANNOTATION_FILENote: This reuses the previous local test annotation file and overwrites it. Overwriting a file in a bucket also triggers attached functions.
Wait a few seconds and query the logs to check that the function has been triggered:
gcloud functions logs read --region $GCF_REGIONLEVEL NAME EXECUTION_ID TIME_UTC LOG...D gcf2_generate_summary ... ... Function execution startedI gcf2_generate_summary ... ... Downloading -> /tmp/SUMMARY_BUCKET/VIDEO_BUCKET/VIDEO_NAMEI gcf2_generate_summary ... ... Generating summary...I gcf2_generate_summary ... ... Uploading -> VIDEO_BUCKET/VIDEO_NAME.summary004.jpegD gcf2_generate_summary ... ... Function execution took 11591 ms, finished with status: 'ok'The 2nd function is operational and the pipeline is in place! You can now do end-to-end tests by copying new videos in the 1st bucket.
Results
Download the generated summary on your computer:
cd ~/$PROJECT_IDgsutil cp -r gs://$SUMMARY_BUCKET/**.jpeg .cloudshell download *.jpegHere is the visual summary for gbikes_dinosaur.mp4 (4 detected shots):

You can also directly preview the file from the Cloud Console:

Cherry on the Py
Now, the icing on the cake (or the "cherry on the pie" as we say in French)...
- Based on the same architecture and code, you can add a few features:
- Trigger the processing for videos from other buckets
- Generate summaries in multiple formats (such as JPEG, PNG, WEBP)
- Generate animated summaries (also in multiple formats, such as GIF, PNG, WEBP)
- Enrich the architecture to duplicate 2 items:
- The video shot detection function, to get it to run as an HTTP endpoint
- The summary generation function to handle animated images
- Adapt the code to support the new features:
- An
animatedparameter to generate still or animated summaries - Save and upload the results in multiple formats
- An
Architecture (v2)

- A. Video shot detection can also be triggered manually with an HTTP GET request
- B. Still and animated summaries are generated in 2 functions in parallel
- C. Summaries are uploaded in multiple image formats
HTTP entry point
def gcf_detect_shots_http(request): """ Cloud Function triggered by an HTTP GET request """ if request.method != 'GET': return ('Please use a GET request', 403) if not request.args or 'video_uri' not in request.args: return ('Please specify a "video_uri" parameter', 400) video_uri = request.args['video_uri'] launch_shot_detection(video_uri, ANNOTATION_BUCKET) return f'Launched shot detection for video_uri <{video_uri}>'Note: This is the same code as
gcf_detect_shotswith the video URI parameter provided from a GET request.
Function deployment
GCF_NAME="gcf1_detect_shots_http"GCF_SOURCE="$PROJECT_SRC/gcf1_detect_shots"GCF_ENTRY_POINT="gcf_detect_shots_http"GCF_TRIGGER_BUCKET="$VIDEO_BUCKET"GCF_ENV_VARS="ANNOTATION_BUCKET=$ANNOTATION_BUCKET"GCF_MEMORY="128MB"gcloud functions deploy $GCF_NAME \ --runtime python37 \ --source $GCF_SOURCE \ --entry-point $GCF_ENTRY_POINT \ --update-env-vars $GCF_ENV_VARS \ --trigger-http \ --region $GCF_REGION \ --memory $GCF_MEMORY \ --quietHere is how it looks like in the Cloud Console:

Animation support
Add an animated option in the core function:
class VideoProcessor: @staticmethod def generate_summary(annot_uri: str, output_bucket: str, animated=False): """ Generate a video summary from video shot annotations """ try: with StorageHelper(annot_uri, output_bucket) as storage: with VideoProcessor(storage) as video_proc: print('Generating summary...')- image = video_proc.render_summary()- video_proc.upload_summary_as_jpeg(image)+ if animated:+ video_proc.generate_summary_animations()+ else:+ video_proc.generate_summary_stills() except: logging.exception( 'Could not generate summary from shot annotations <%s>', annot_uri)Define the formats you're interested in generating:
class ImageFormat: # See https://pillow.readthedocs.io/en/stable/handbook/image-file-formats.html image_format: str save_parameters: Dict # Make a copy if updated class ImageJpeg(ImageFormat): image_format = 'jpeg' save_parameters = dict(optimize=True, progressive=True) class ImageGif(ImageFormat): image_format = 'gif' save_parameters = dict(optimize=True) class ImagePng(ImageFormat): image_format = 'png' save_parameters = dict(optimize=True) class ImageWebP(ImageFormat): image_format = 'webp' save_parameters = dict(lossless=False, quality=80, method=1) SUMMARY_STILL_FORMATS = (ImageJpeg, ImagePng, ImageWebP) SUMMARY_ANIMATED_FORMATS = (ImageGif, ImagePng, ImageWebP)Add support to generate still and animated summaries in different formats:
def generate_summary_stills(self): image = self.render_summary() for image_format in self.SUMMARY_STILL_FORMATS: self.upload_summary([image], image_format) def generate_summary_animations(self): frame_count = self.ANIMATION_FRAMES images = [] for frame_index in range(frame_count): shot_ratio = (frame_index+1) / (frame_count+1) print(f'shot_ratio: {shot_ratio:.0%}') image = self.render_summary(shot_ratio) images.append(image) for image_format in self.SUMMARY_ANIMATED_FORMATS: self.upload_summary(images, image_format)The serialization can still take place in a single function:
def upload_summary(self, images: List['Image'], image_format: Type[ImageFormat]): if not images: raise RuntimeError('Empty image list') mem_file = BytesIO() image_type = image_format.image_format save_parameters = dict(image_format.save_parameters) # Copy animated = 1 < len(images) if animated: save_parameters.update(dict( save_all=True, append_images=images[1:], duration=self.ANIMATION_FRAME_DURATION_MS, loop=0, # Infinite loop )) images[0].save(mem_file, format=image_type, **save_parameters) image_bytes = mem_file.getvalue() self.storage.upload_summary(image_bytes, image_type, animated)Note:
Pillowis both versatile and consistent, allowing for significant and clean code factorization.
Add an animated optional parameter to the StorageHelper class:
class StorageHelper:- def upload_summary(self, image_bytes: bytes, image_type: str):- path = self.summary_path(image_type)+ def upload_summary(self, image_bytes: bytes, image_type: str, animated=False):+ path = self.summary_path(image_type, animated) blob = self.upload_bucket.blob(path.as_posix()) content_type = f'image/{image_type}' print(f'Uploading -> {blob.name}') blob.upload_from_string(image_bytes, content_type)+ def summary_path(self, image_type: str, animated=False) -> Path: video_name = self.video_path.name shot_count = self.shot_count()- suffix = f'summary{shot_count:03d}.{image_type}'+ still_or_anim = 'anim' if animated else 'still'+ suffix = f'summary{shot_count:03d}_{still_or_anim}.{image_type}' summary_name = f'{video_name}.{suffix}' return Path(self.video_path.parent, summary_name)And finally, add an ANIMATED optional environment variable in the entry point:
...+ANIMATED = os.getenv('ANIMATED', '0') == '1'def gcf_generate_summary(data, context): ...- VideoProcessor.generate_summary(annot_uri, SUMMARY_BUCKET)+ VideoProcessor.generate_summary(annot_uri, SUMMARY_BUCKET, ANIMATED)if __name__ == '__main__': ...- VideoProcessor.generate_summary(args.annot_uri, SUMMARY_BUCKET)+ VideoProcessor.generate_summary(args.annot_uri, SUMMARY_BUCKET, ANIMATED)Function deployment
Duplicate the 2nd function with the additional ANIMATED environment variable:
GCF_NAME="gcf2_generate_summary_animated"GCF_SOURCE="$PROJECT_SRC/gcf2_generate_summary"GCF_ENTRY_POINT="gcf_generate_summary"GCF_TRIGGER_BUCKET="$ANNOTATION_BUCKET"GCF_ENV_VARS1="SUMMARY_BUCKET=$SUMMARY_BUCKET"GCF_ENV_VARS2="ANIMATED=1"GCF_TIMEOUT="540s"GCF_MEMORY="2048MB"gcloud functions deploy $GCF_NAME \ --runtime python37 \ --source $GCF_SOURCE \ --entry-point $GCF_ENTRY_POINT \ --update-env-vars $GCF_ENV_VARS1 \ --update-env-vars $GCF_ENV_VARS2 \ --trigger-bucket $GCF_TRIGGER_BUCKET \ --region $GCF_REGION \ --timeout $GCF_TIMEOUT \ --memory $GCF_MEMORY \ --quietHere is how it looks like in the Cloud Console:

Final tests
The HTTP endpoint lets you trigger the pipeline with a GET request:
GCF_NAME="gcf1_detect_shots_http"VIDEO_URI="gs://cloudmleap/video/next/visionapi.mp4"GCF_URL="https://$GCF_REGION-$PROJECT_ID.cloudfunctions.net/$GCF_NAME?video_uri=$VIDEO_URI"curl $GCF_URL -H "Authorization: bearer $(gcloud auth print-identity-token)"Launched shot detection for video_uri <VIDEO_URI>Note: The test video
<visionapi.mp4>is located in an external bucket but is publicly accessible.
In addition, copy one or several videos into the video bucket. You can drag and drop videos:
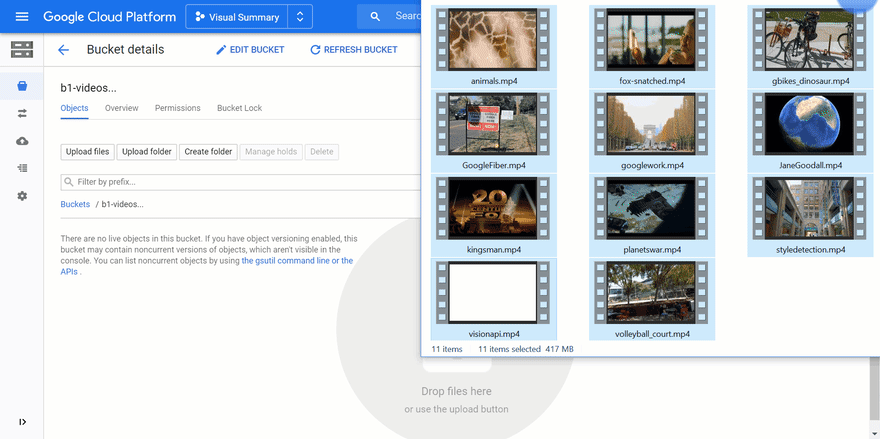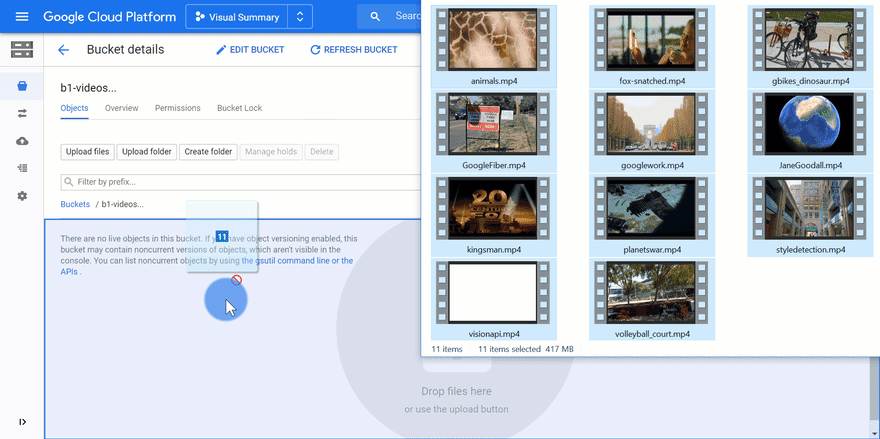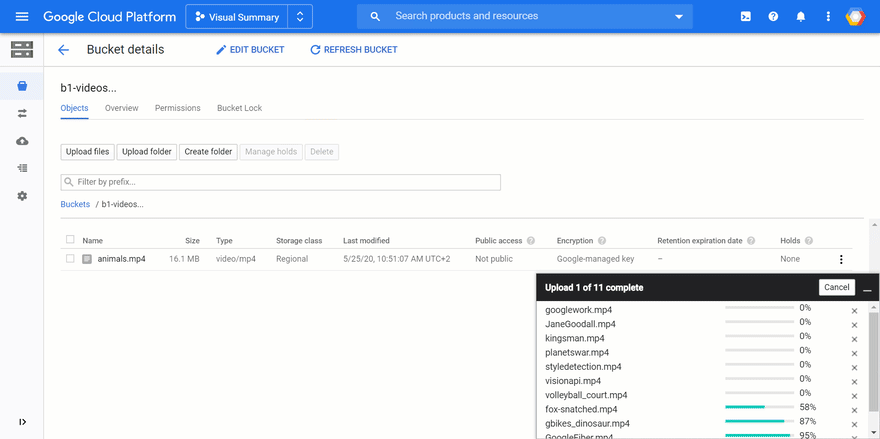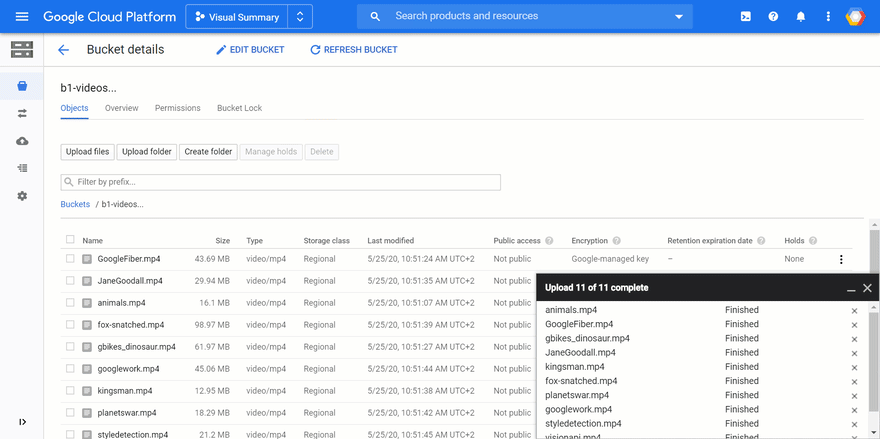
The videos are then processed in parallel. Here are a few logs:
LEVEL NAME EXECUTION_ID ... LOG...D gcf2_generate_summary_animated f6n6tslsfwdu ... Function execution took 49293 ms, finished with status: 'ok'I gcf2_generate_summary yd1vqabafn17 ... Uploading -> b1-videos.../JaneGoodall.mp4.summary035_still.pngI gcf2_generate_summary_animated qv9b03814jjk ... shot_ratio: 43%I gcf2_generate_summary yd1vqabafn17 ... Uploading -> b1-videos.../JaneGoodall.mp4.summary035_still.webpD gcf2_generate_summary yd1vqabafn17 ... Function execution took 54616 ms, finished with status: 'ok'I gcf2_generate_summary_animated g4d2wrzxz2st ... shot_ratio: 71%...D gcf2_generate_summary amwmov1wk0gn ... Function execution took 65256 ms, finished with status: 'ok'I gcf2_generate_summary_animated 7pp882fz0x84 ... shot_ratio: 57%I gcf2_generate_summary_animated i3u830hsjz4r ... Uploading -> b1-videos.../JaneGoodall.mp4.summary035_anim.pngI gcf2_generate_summary_animated i3u830hsjz4r ... Uploading -> b1-videos.../JaneGoodall.mp4.summary035_anim.webpD gcf2_generate_summary_animated i3u830hsjz4r ... Function execution took 70862 ms, finished with status: 'ok'...In the 3rd bucket, you'll find all still and animated summaries:

You've already seen the still summary for <JaneGoodall.mp4> as an introduction to this tutorial. In the animated version, and in only 6 frames, you get an even better idea of what the whole video is about:

If you don't want to keep your project, you can delete it:
gcloud projects delete $PROJECT_IDOne more thing
first_line_after_licence=16find $PROJECT_SRC -name '*.py' -exec tail -n +$first_line_after_licence {} \; | grep -v "^$" | wc -l289You did everything in under 300 lines of Python. Less lines, less bugs! Mission accomplished!
See you
I hope you appreciated this tutorial and would love to read your feedback. You can also follow me on Twitter.
Original Link: https://dev.to/googlecloud/auto-generate-video-summaries-with-a-machine-learning-model-and-a-serverless-pipeline-324i
Dev To
More About this Source Visit Dev To