
An Interest In:
Web News this Week
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
- March 26, 2024
- March 25, 2024
Some of Our Sources
- Mashable
- Simplebits
- TutsPlus - Design
- You The Designer
- Fuel Your Creativity
- Inspiredology
- Naldz Graphics
- My Ink Blog
- CSS Globe
- Willems Lab
Help Webnuz
Referal links:
Acoustic activity recognition in JavaScript
For my personal projects, I often get inspired by research papers I read about human-computer interaction.
Lately, the one I've been looking into is called "Ubicoustics - Plug-and-play acoustic activity recognition" by a team of researchers at the CMU (Carnegie Mellon University) in the US.
Acoustic activity recognition is using the rich properties of sound to gain insights about an environment or activity.
This can be used to enhance smart systems and build more personalised connected homes.
Researchers at the CMU used Python to prototype their experiments and made their project open-source on Github if you want to have a look but I wanted to see if I could reproduce something similar using web technologies, and it worked!
The end result is a prototype of browser-based acoustic activity recognition system, classifying speaking, coughing, typing, brushing teeth and my phone ringing:

This is still early on in my explorations but I thought I'd share what I've learnt so far.
Why using sound?
A lot of devices around us have a built-in microphone; your laptop, phone, tablet, smart watch, home assistant, etc... however, they don't really leverage the rich properties of sound.
In general, applications listen for a certain word to trigger actions like "Ok, Google" or "Alexa", but words are not the only thing that produce distinguishable sounds; everything around us generates sounds.
If you take a second to think about it, you know what the sound of rain is, you know the difference between what a fridge sounds like when it's being opened versus a microwave, you recognise the sound of a doorbell even if it's not yours, etc...
I like to think that if your brain is capable of taking sound input and classifying it, then something similar should be possible using machine learning; so let's see how this would work.
Tech stack
For this prototype, I used the Web Audio API to use the microphone as input, Canvas to build a spectrogram with the sound data and Tensorflow.js to train a model to recognise activities.
To make it easier, I used the Teachable machine experiment by Google to record my sound samples, train the machine learning model and export it.
Now, let's go through some of the steps I took to build this.
Visualising sound data
When you inspect the data you get from the microphone input using the Web Audio API, you get something like this:

Looking at it this way, as arrays of numbers, makes it a bit difficult for us to find any particular pattern that would differentiate clapping your hands from snapping your fingers for example.
To help us, we'd usually visualise this data. Two standard ways to do this include turning it into a waveform or frequency bar graph like below:

A waveform represents the sound waves displacement over time.
Sound being the vibration of air molecules, this graph shows the oscillation of a sound wave. But, visualised this way, we still can't really conclude anything.
A frequency bar graph shows you the sound data as a measure of how many times a waveform repeats in a given amount of time.
In this way of visualising, we could maybe start to gain some insights, recognise some kind of "beat", but we're still not quite there.
A better way to represent this data to find patterns is what is called a spectrogram.
A spectrogram is a visual representation of the spectrum of frequencies of a signal as it varies with time. You can think of it as a heat map of sound.
Using Canvas to visualise my microphone input as a spectrogram, I could identify pretty easily the difference between speaking and clapping my hands.
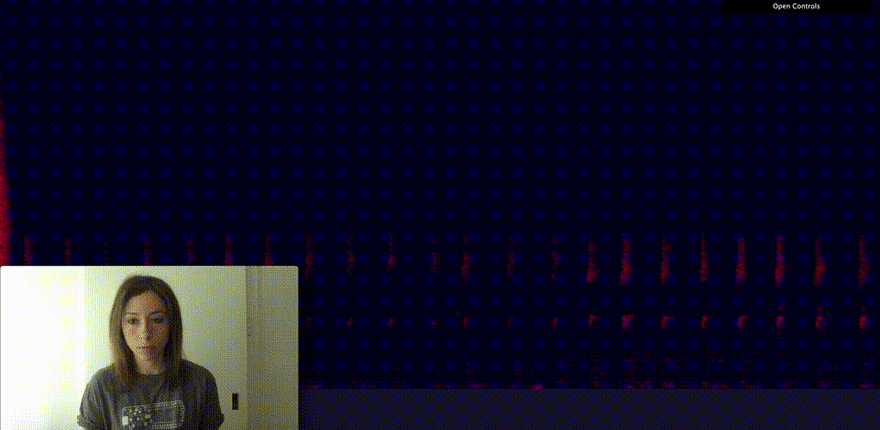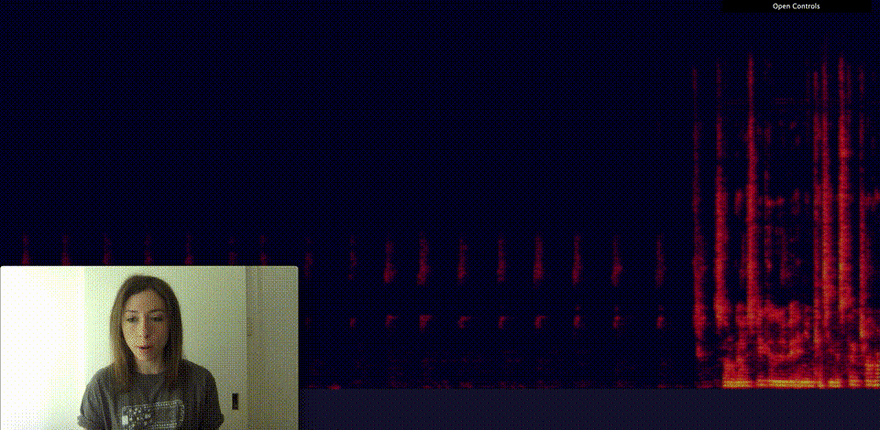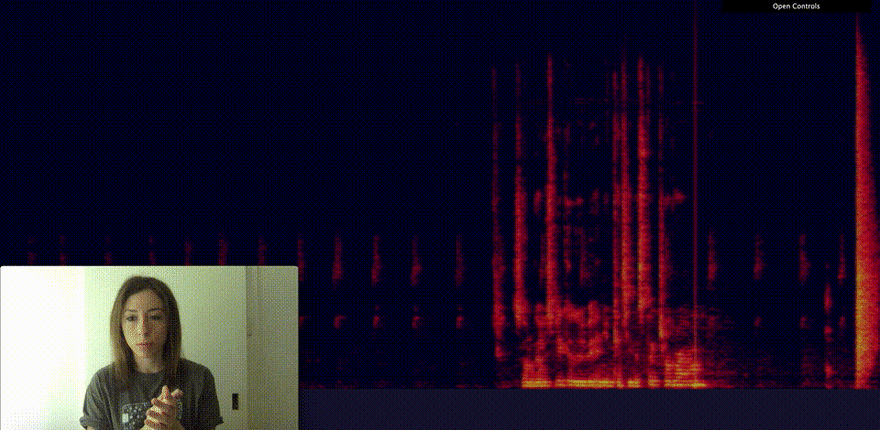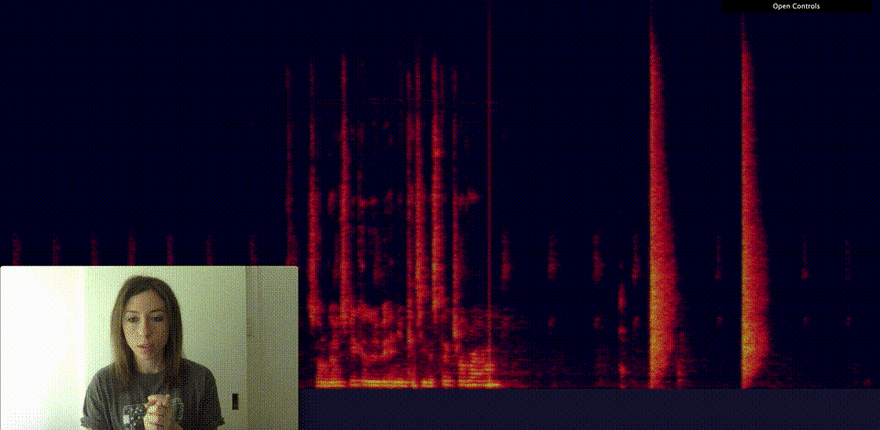
So far, none of this is using machine learning. I'm only using the Web Audio API to get data from the microphone and Canvas to turn it into a spectrogram.
Now that we can observe that certain activities produce data that "looks" different, we can move on to using machine learning and Tensorflow.js to build a classification model.
Classifying sound data using machine learning
As mentioned above, to make it easier, I used the Teachable machine experiment to record my sound samples, run the training and generate the model.
My main goal so far was to validate that my idea was feasible, so I preferred using something that was already built, however, you could definitely create your own sound classification system from scratch (I'd like that to be one of my potential next steps).
For now, my training process looked like this:

First, you need to record some background noise for 20 seconds. This is a necessary step so the algorithm would recognise some kind of neutral state when you're not doing any activity.
Then, you can add different "classes" which are your different activities. You need to record a minimum of 8 samples / activity but the more the better.
In the example above, I only record samples for snapping my fingers, then run the training and check the predictions live at the end.
Depending on what you would like to build, you might add a lot more classes, but it's important to check if the prediction is accurate so you can record more samples and re-train if needed.
If you're happy with the output, you can download the model and use it in your project.
Using the machine learning model
Once the training process is done, you can use the model generated to run some live predictions with new sound samples it has never "seen" before.
To do this, you need to start by importing the framework and another model:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]/dist/tf.min.js"></script><script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/[email protected]/dist/speech-commands.min.js"></script>In the code sample above, we import Tensorflow.js and the speech-commands model.
We need to do this because the way we are predicting new sound samples is done using transfer learning.
Transfer learning means that we're using a pre-trained model that is optimised with a certain kind of input, adding our own samples to it and re-training everything together.
The speech-commands model is the only pre-trained model available with Tensorflow.js that has been trained with sound samples.
It is optimised to classify spoken words, but I wanted to see if it could still be accurate being given sound samples of activities.
Once you've imported the tools, you need to load your custom model:
let model;async function setupModel(URL, predictionCB) { //store the prediction and audio callback functions predictionCallback = predictionCB; const modelURL = 'model.json'; const metadataURL = 'metadata.json'; model = window.speechCommands.create('BROWSER_FFT', undefined, modelURL, metadataURL); await model.ensureModelLoaded(); const modelParameters = { invokeCallbackOnNoiseAndUnknown: true, // run even when only background noise is detected includeSpectrogram: true, // give us access to numerical audio data overlapFactor: 0.5 // how often per second to sample audio, 0.5 means twice per second }; model.listen( //This callback function is invoked each time the model has a prediction. prediction => { predictionCallback(prediction.scores); }, modelParameters );}When you download your model from Teachable machine, you get a model.json and metadata.json files. You need both for it to work. The metadata.json file contains information about the name of your classes, etc...
Then, you need to invoke the speechCommands model and pass it your model variables.
Once the model is loaded, you can define a few extra parameters, call the listen method that will trigger a callback every time it has predicted something from the live audio data coming from the microphone.
Once your function is set up, you can call it this way:
let labels = ["Clapping","Speaking","_background_noise_"];setupModel(URL, data => { // data will look like this [0.87689, 0.21456, 0.56789] switch(Math.max(...data)){ case data[0]: currentPrediction = labels[0]; break; case data[1]: currentPrediction = labels[1]; break; default: currentPrediction = ""; break; } } return currentPrediction;});I defined an array with classes that I trained and, when a prediction happens, the result will come back as an array of floats between 0 and 1, representing the probability of each class to be the one predicted; if the maximum number is the first in the array of probabilities, our activity recognised will be the 1st in our labels array defined above.
Demo
In the end, my prototype looks something like this:
If you want to play around with it yourself, here's the link to the demo.
It will be more accurate if you try it in a quiet environment because I recorded my samples at home. If you try it in the train or in a cafe, the background noise will be too different from the one provided for the training so the accuracy will drop.
At the moment, because of time restrictions, it's mostly optimised for Chrome on desktop. There's a few things to fix up for it to work as expected on other browsers and mobile.
Applications
For now, this prototype is only exploratory but I believe there is potential to this kind of technology.
Instead of buying multiple expensive smart devices such as fridges, coffee machines and microwaves, that are only aware of themselves (a smart fridge doesn't know if the coffee machine is on, etc...), we could replace them with a single device that would have more contextual understanding, not only of other devices, but of which room it is in and of its users' activities.
This could help with the following applications.
Contextually-aware video services
Cooking
If you're following a recipe on Youtube while you're cooking, the video could pause automatically when you are supposed to chop some vegetables, or microwave something for a minute, or use a whisk, etc... by listening to your activities. This way, you wouldn't have to go back and forth between your laptop, tablet or phone while cooking.
Watching your favourite TV series
If you're watching Netflix and your phone or doorbell rings, the video could be paused without you having to find the remote because a doorbell or phone ringing usually means you're gonna be away from the TV for a few minutes.
Interactive story-telling
If you're working at a creative agency or media company where engagement with your online content is important, this type of technology could mean a more interactive and entertaining way to consume content. A story could be a lot more immersive by asking you to participate in it in different ways, by clapping your hands, imitating some sounds, etc...
Health tracking
As you could see in my quick demo, you can classify the sound of coughing and brushing your teeth, so you could also train your system to recognise sneezing, snoring, etc... and build some kind of health tracking system.
There are definitely a lot more applications but this was just to give you an idea of where it could be used.
Limitations
One of the main limits would be privacy concerns. You wouldn't want your Google Home or Amazon Alexa to, not only listen to your conversations, but also know everything you're doing by listening to all your activities... right???!
There would be a way to build your own private offline system but that is definitely not something most people would have access to.
The other main limitation at the moment is the inability to understand multiple activities at once. If you are brushing your teeth while someone is talking to you, this system would only predict a single activity at a time.
However, this is where another exciting project comes into play, which is called "General-purpose synthetic sensors" , that I'll talk about briefly next.
Next steps
I still have a lot more to learn about this and I'm hoping to have the time to explore that space in 2020, but one of my next step would be to build general-purpose synthetic sensors.
Instead of only using sound data to recognise activities, researchers at the CMU also worked on a project to create a small device integrating several sensors (microphone, temperature sensor, accelerometer, motion sensor, light sensor, etc...), to combine multiple spectrograms, in the aim to monitor larger contexts and build a more robust activity recognition system.

That's it for now!
I understand that people might be skeptical about this experiment, especially in JavaScript, but knowing that no hardware upgrade is needed for this to work, means that the main thing we're waiting for might be finding the right application.
Personally, I'm always super excited to know that, as developers, we can take part in such research by building prototypes using JavaScript and explore what might be the future of interactions.
Hope it helps!
Original Link: https://dev.to/devdevcharlie/acoustic-activity-recognition-in-javascript-2go4
Dev To
More About this Source Visit Dev To