
An Interest In:
Web News this Week
- April 16, 2024
- April 15, 2024
- April 14, 2024
- April 13, 2024
- April 12, 2024
- April 11, 2024
- April 10, 2024
Some of Our Sources
- Simplebits
- TutsPlus - Code
- Crazy Leaf Design
- Web Design Ledger
- Wal You
- Specky Boy
- Web Resource Source
- Codrops
- The Verge
- TechPowerUp
Help Webnuz
Referal links:
AI Inference now available in Supabase Edge Functions
We're making it super easy to run AI models within Supabase Edge Functions. A new built-in API is available within the Edge Runtime to run inference workloads in just a few lines of code:
// Instantiate a new inference sessionconst session = new Supabase.ai.Session('gte-small')// then use the session to run inference on a promptconst output = await session.run('Luke, I am your father')console.log(output)// [ -0.047715719789266586, -0.006132732145488262, ...]With this new API you can:
- Generate embeddings using models like
gte-smallto store and retrieve with pgvector. This is available today. - Use Large Language Models like
llama2andmistralfor GenAI workloads. This will be progressively rolled out as we get our hands on more GPUs.
In our previous Launch Week we announced support for AI inference via Transformers.js. This was a good start but had some shortcomings: it takes time to boot because it needs to instantiate a WASM runtime and build the inference pipeline. We increased CPU limits to mitigate this, but we knew we wanted a better Developer Experience.
In this post we'll cover some of the improvements to remove cold starts using Ort and how we're adding LLM support using Ollama.
Generating Text Embeddings in Edge Functions
Embeddings capture the "relatedness" of text, images, video, or other types of information. Embeddings are stored in the database as an array of floating point numbers, known as vectors. Since we released pgvector on the platform, Postgres has become a popular vector database.
Today's release solves a few technical challenges for developers who want to generate embeddings from the content in their database, giving them the ability to offload this compute-intensive task to background workers.
Integrated pgvector experience
You can now utilize database webhooks to automatically generate embeddings whenever a new row is inserted into a database table.
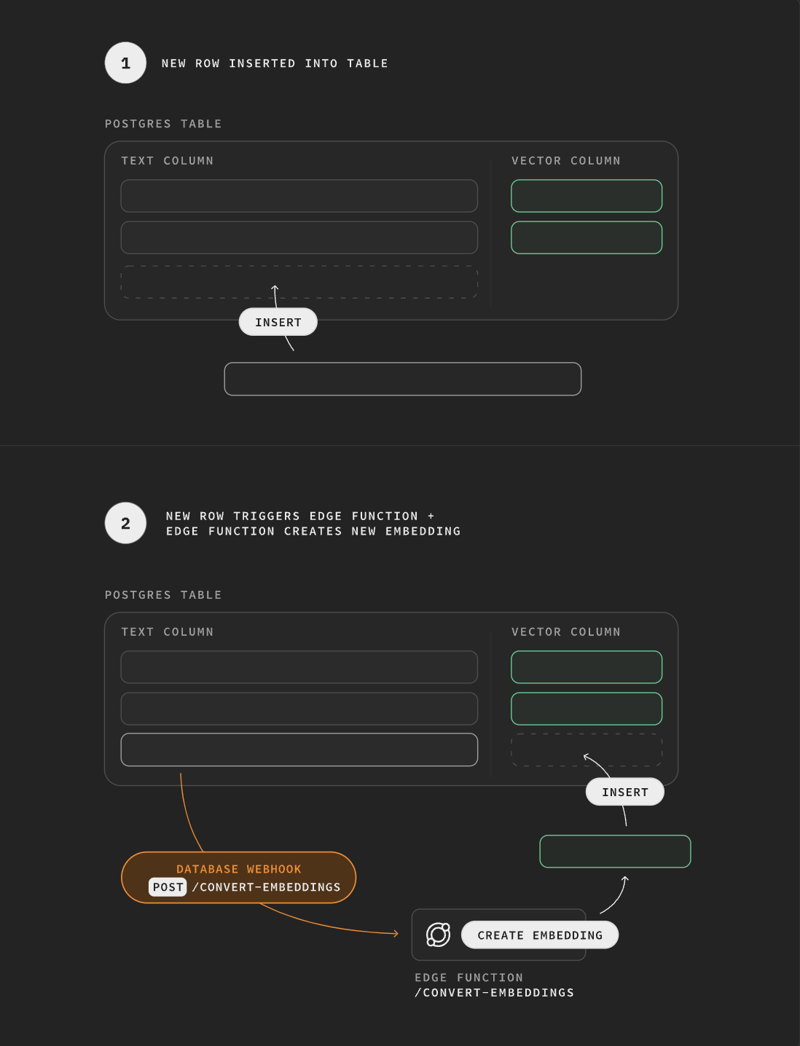
Because embedding creation is a compute-intensive task, it makes sense to offload the work from your database. Edge Functions are the perfect background worker. We've created a simple example to show how you can generate embeddings in Edge Functions: Semantic Search with pgvector and Supabase Edge Functions.
Technical architecture
Embedding generation uses the ONNX runtime under the hood. This is a cross-platform inferencing library that supports multiple execution providers from CPU to specialized GPUs.
Libraries like transformers.js also use ONNX runtime which, in the context of Edge Functions, runs as a WASM module, which can be slow during the instantiation process.
To solve this, we built a native extension in Edge Runtime that enables using ONNX runtime via the Rust interface. This was made possible thanks to an excellent Rust wrapper called Ort:

Embedding generation is fairly lightweight compared to LLM workloads, so it can run on a CPU without hardware acceleration.
Availability: open source embeddings
Embeddings models are available on Edge Functions today. We currently support gte-small and we'll add more embeddings models based on user feedback.
Embedding generation via Supabase.ai API is available today for all Edge Functions users in both local, hosted, and self-hosted platforms.
Lower costs
Generating embeddings in an Edge Function doesn't cost anything extra: we still charge on CPU usage. A typical embedding generation request should run in less than a 1s, even from a cold start. Typically it won't use more than 100-200ms of CPU time.
Proprietary LLMs like OpenAI and Claude provide APIs to generate text embeddings, charging per token. For example, OpenAI's text-embedding-3-small cost $0.02/1M tokens at the time of writing this post.
Open source text embedding models provide similar performance to OpenAI's paid models. For example, the gte-small model, which operates on 384 dimensions, has an average of 61.36 compared to OpenAI's text-embedding-3-small, which is at 62.26 on the MTEB leaderboard, and they perform search faster with fewer dimensions.
With Supabase Edge Functions, you can generate text embeddings 10x cheaper than OpenAI embeddings APIs.
Large Language Models in Supabase Edge Functions
Embedding generation only a part of the solution. Typically you need an LLM (like OpenAI's GPT-3.5) to generate human-like interactions. We're working with Ollama to make this possible with Supabase: local development, self-hosted, and on the platform.
Open source inference models
We are excited to announce experimental support for Llama & Mistral with Supabase.ai API.
The API is simple to use, with support for streaming responses:
const session = new Supabase.ai.Session('mistral')Deno.serve(async (req: Request) => { // Get the prompt from the query string const params = new URL(req.url).searchParams const prompt = params.get('prompt') ?? '' // Get the output as a stream const output = await session.run(prompt, { stream: true }) // Create a stream const stream = new ReadableStream({ async start(controller) { const encoder = new TextEncoder() for await (const chunk of output) { controller.enqueue(encoder.encode(chunk.response ?? '')) } }, }) // Return the stream to the user return new Response(stream, { headers: new Headers({ 'Content-Type': 'text/event-stream', Connection: 'keep-alive', }), })})Check out the full guide here.
Technical architecture
LLM models are challenging to run directly via ONNX runtime on CPU. For these, we are using a GPU-accelerated Ollama server under the hood:

We think this is a great match: the Ollama team have worked hard to ensure that the local development experience is great, and we love development environments that can be run without internet access (for those who enjoy programming on planes).
As a Supabase developer, you don't have to worry about deploying models and managing GPU instances - simply use a serverless API to get your job done.
Availability: open source embeddings
Access to open-source LLMs is currently invite-only while we manage demand for the GPU instances. Please get in touch if you need early access.
Extending model support
We plan to extend support for more models. Let us know which models you want next. We're looking to support fine-tuned models too!
Getting started
Check out the Supabase docs today to get started with the AI models:
- Edge Functions: supabase.com/docs/guides/functions
- Vectors: supabase.com/docs/guides/ai
- Semantic search demo
- Store and query embeddings in Postgres and use them for Retrieval Augmented Generation (RAG) and Semantic Search
More on GA week
Original Link: https://dev.to/supabase/ai-inference-now-available-in-supabase-edge-functions-3ae1
Dev To
More About this Source Visit Dev To