
An Interest In:
Web News this Week
- April 3, 2024
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
Some of Our Sources
- Simplebits
- Pearsonified
- Smashing Apps
- Six Revisions
- Web Designer Depot
- Naldz Graphics
- Specky Boy
- Android Headlines
- Daily Now
- Hashedout
Help Webnuz
Referal links:
Web Scraping With Python(2023) - A Complete Guide
Web Scraping With Python A Complete Guide
Python is the most popular language for web scraping. The amount of flexibility it offers while extracting data from websites is one of the main reasons it is a preferred choice for data extraction. Also, it has a couple of high-performance libraries like BeautifulSoup, and Selenium, which can be used to make powerful and efficient scrapers.
Most people reading this article may have heard of the terms Data Extraction or Web Scraping. If you have not come across this yet, dont worry, as this article is planned for all types of developers who have just started with web scraping or want to gain more information about it.
Web Scraping is the process of extracting a specific set of information from websites in the form of text, videos, images, and links. In todays world, web scraping is an important skill to learn, as it can be used for a variety of purposes, such as lead generation, price monitoring, SERP monitoring, etc.

In this tutorial, we will learn web scraping with Python and also explore some of the high-performance libraries that can be used to create an efficient and powerful scraper.
HTTP headers hold great importance in scraping a website. Passing headers with the HTTP request not only affects the response but also the speed of the request. So, before starting with the core tutorial, let us learn about the HTTP Headers and their types in-depth.
Why Python for Web Scraping?
There are many reasons why developers choose Python for web scraping over any other language:
Simple Syntax Python is one of the simplest programming languages to understand. Even beginners can understand and write scraping scripts due to the clear and easy-to-read syntax.
Extreme Performance Python provides many powerful libraries for web scraping, such as Requests, Beautiful Soup, Scrapy, Selenium, etc. These libraries can be used for making high-performance and robust scrapers.
Adaptability Python provides a couple of great libraries that can be utilized for various conditions. You can use Requests for making simple HTTP requests and, on the other end, Selenium for scraping dynamically rendered content.
HTTP Headers
In this section, we will learn about the Headers and their importance in web scraping. I will also try to explain the type of headers to you in detail. Lets get started with it!
Headers are used to provide essential meta-information such as content type, user agent, content length, and much more about the request and response. They are usually represented in text string format and are separated by a colon.
Headers have a significant impact on web scraping. Passing correctly optimized headers not only guarantees accurate data but also reduces the response timings. Generally, website owners implement anti-bot technology to protect their websites from being scraped by scraping bots. However, you can bypass this anti-bot mechanism and prevent your IPs from getting blocked by passing the appropriate headers with the HTTP request.
Headers can be classified into four types:

Request Headers
Response Headers
Representation Headers
Payload Headers
Let us learn each of them in detail.
Request Headers
The headers sent by the client when requesting data from the server are known as Request Headers. It also helps to recognize the request sender or client using the information in the headers.
Here are some examples of the request headers.
authority: en.wikipedia.org
method: GET
accept-language: en-US, en;q=0.9
accept-encoding: gzip, deflate, br
upgrade-insecure-requests: 1
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4869.91 Safari/537.36
The user agent indicates the type of software or application used to send the request to the server.
The Accept-Language header tells the server about the desired language for the response. The Accept-Encoding header is a request header sent by the client that indicates the content encoding it can understand.
Note: Not all headers in the request can be specified as request headers. For example The Content-Type header is not a request header but a representation header.*
Response Header
The headers sent by the server to the client in response to the request headers from the user are known as Response Headers. It is not related to the content of the message. It is sent by the server to convey instructions and information to the client.
Here are some examples of the response headers.
content-length: 35408
content-type: text/html
date: Thu, 13 Apr 2023 14:09:10 GMT
server: ATS/9.1.4
cache-control: private, s-maxage=0, max-age=0, must-revalidate
The Date header indicates the date on which the response is sent to the client. The Server header informs the client from which server the response is returned, and the Content-Length header indicates the length of the content returned by the server.
Note: The Content-Type header is the representation header.
Representation Header
The headers that communicate the information about the representation of resources in the HTTP response body sent to the client by the server are known as Representation Header. The data can be transferred in several formats, such as JSON, XML, HTML, etc.
Here are some examples of the representation headers.
content-encoding: gzip
content-length: 35408
content-type: text/html
The Content-Encoding header informs the client about the encoding of the HTTP response body.
Payload Headers
The headers that contain information about the original resource representation are known as Payload Headers.
Here are some examples of payload headers.
content-length: 35408
content-range: bytes 2001000/67589
trailer: Expires
The Content-Range header tells the position of the partial message in the full-body message.
Here, we are completed with the Headers section. There can be more headers to be discussed. But, it will make the blog long and deviate from the main topic.
If you want to know more about headers, you can read this MDN Mozilla Documentation.
Web Scraping Libraries in Python
The top web scraping libraries in Python are:
Requests
Beautiful Soup
Scrapy
Selenium
Requests
Requests is the most downloaded HTTP request library on Pypi.org, pulling around 30 million downloads every week. From beginners to experts in programming, everyone uses it.
This library will help us to make an HTTP request on the website server and pull the precious HTML data out of it. It supports all types of requests (GET, POST, DELETE, etc.) and follows a straightforward approach while handling cookies, sessions, and redirects.
Lets discuss how we can scrape Google Search Results using this library.
pip install requestsAfter installing this library in your project folder, import it into your code like this:
import requestsAnd then, we will use this library to create a scraping bot that will mimic an organic user.
url = "https://www.google.com/search?q=python+tutorial&gl=us"headers = {"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.2816.203 Safari/537.36"}resp = requests.get(url, headers=headers).textprint(resp)First, we declared our target URL. Then, we initialized the header with the User Agent. After that, we made a GET request on the URL and printed the response in the terminal.
Our response should look like this:

Yeah, it is unreadable. Dont worry! We will parse this extracted HTML using the Beautiful Soup library, which we will cover briefly.
BeautifulSoup

BeautifulSoup, also known as BS4, is a web parsing library used for parsing HTML and XML documents. It can easily navigate within the HTML structure and allows us to extract data from HTML elements and their attributes.
Lets discuss how we can parse the extracted HTML document in the previous section using this library.
First, install this library in your project folder.
pip install beautifulsoup4 And then import it into your file.
from bs4 import BeautifulSoupWe will extract the title, link, and description from the target page, but let us first declare our BeautifulSoup instance to perform this operation.
soup=BeautifulSoup(resp.content, 'html.parser')If you inspect the HTML of the target page, you will find that every result is under the g class.
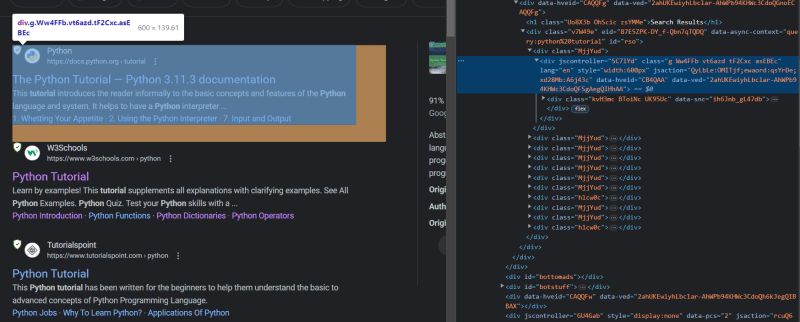
So, we will iterate over each container with the g class and extract the required data from it.
search_results = []for el in soup.select("div.g"): search_results.append( {And if you further inspect inside the div.g the container, you will find that the title is under the tag h3, and the link is under the tag .yuRUbf > a and snippet is under the tag VwiC3b.
for el in soup.select("div.g"): search_results.append( { "title": el.select_one("h3").get_text(), "link": el.select_one(".yuRUbf > a")["href"], "snippet": el.select_one(".VwiC3b").get_text(), } )print(json.dumps(search_results, indent=2))I have printed the results in JSON format. For this, you need to import the JSON library.
import jsonNow, run this program in your terminal, and you will get the result like this:
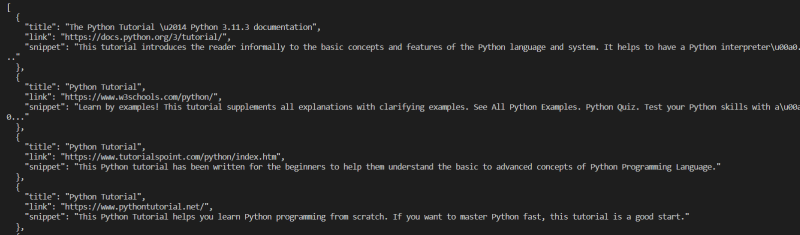
Advantages of using Beautiful Soup:
Easy to use and beginner friendly.
Can navigate and parse the DOM faster.
Works on all HTML and XML documents.
Easier to debug.
It allows data extraction from HTML and XML in various flexible ways.
Scrapy

Scrapy is a fast and powerful open-source web crawling framework used to extract data from websites. Developed by Zyte.com, it is easy to use and is designed for creating scalable and flexible web scraping projects.
Lets design a scraper to scrape all the titles of the listed posts from this ycombinator page.
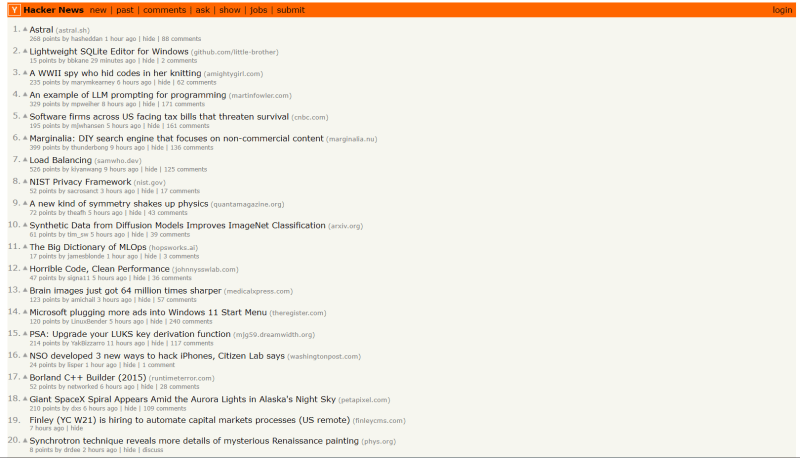
Let us first install Scrapy.
pip install scrapyThen we will create our project folder using scrapy.
scrapy startproject scraperThis will create a folder named scraper in your project folder.

After running the above command in your terminal, you can see two more messages generated by Scrapy.
Use these commands to go inside the scraper folder.
cd scraperscrapy genspider ycombinator news.ycombinator.comThis will create a file named ycombinator.py in the spider folder. It will automatically create a class and a function for us in the generated file.
import scrapyclass YcombinatorSpider(scrapy.Spider): name = "ycombinator" allowed_domains = ["news.ycombinator.com"] start_urls = ["http://news.ycombinator.com/"] def parse(self, response): passNow, lets find the tag of the required element we want to scrape.
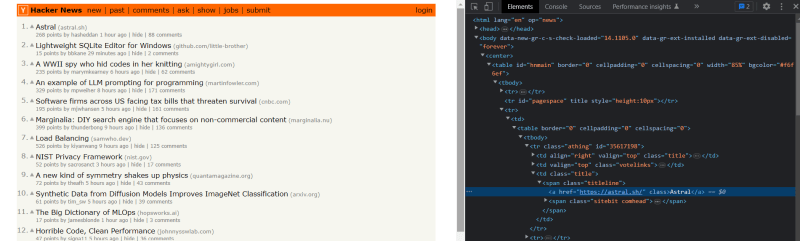
As you can all our post titles are under the tag .titleline > a.
This makes our code looks like this:
import scrapyfrom bs4 import BeautifulSoupclass YcombinatorSpider(scrapy.Spider): name = "ycombinator" allowed_domains = ["news.ycombinator.com"] start_urls = ["https://news.ycombinator.com/"] def start_requests(self): headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4690.0 Safari/537.36' # Replace with the desired User-Agent value } for url in self.start_urls: yield scrapy.Request(url, headers=headers, callback=self.parse) def parse(self, response): soup = BeautifulSoup(response.text, 'html.parser') for el in soup.select(".athing"): obj = {} try: obj["titles"] = el.select_one(".titleline > a").text except: obj["titles"] = None yield objif __name__ == "__main__": from scrapy.crawler import CrawlerProcess process = CrawlerProcess() process.crawl(AmazonSpider) process.start()Run this code in your terminal, and the results should look like this:

Advantages of using Scrapy:
It is designed to be highly scalable.
Extremely fast than most HTTP libraries.
Comes with built-in support like error handling, managing cookies, and much more.
Selenium
In the above sections, we have studied some great frameworks, but none of them is suitable for scraping SPA(single-page applications) or dynamically rendered content. This is where Selenium comes into play!
Selenium is a Python library used for browser automation and testing web applications. It is a powerful tool that can perform various tasks like clicking buttons, navigating through pages, infinite scrolling, and much more. Not only it supports multiple languages, but also multiple browsers.
Let us scrape the list of books from this website using Selenium.
First, install Selenium in your project folder.
pip install seleniumNow, install the Chrome driver from this link. Install the Chrome driver the same as your Chrome browser version.
Next, we will import all the libraries we will be using further in this section.
from selenium.webdriver.chrome.service import Servicefrom selenium import webdriverfrom bs4 import BeautifulSoupAfter that, we will set the path where our Chrome Driver is located.
SERVICE_PATH = "E:\chromedriver.exe"l=list()obj={}headers= { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36", }url = "https://books.toscrape.com"In the first line, we set the path where our Chrome Driver is located. Then, we declared a list and object to store the scraped data. After that, we set headers to User Agent and the URL to our target link.
So, let us now navigate to our target URL.
service = Service(SERVICE_PATH)driver = webdriver.Chrome(service=service)driver.get(url)In the above code, we used the web driver to use the Chrome Driver present at the given path to navigate to the target URL.
So, after navigating to the target URL, we will ask the web driver for the HTML content of the page and then close it.
resp = driver.page_sourcedriver.close()Closing the web driver is important as it requires a high CPU usage to run which results in high scraping costs.
And then, we will create an instance of BeautifulSoup to parse the HTML.
soup = BeautifulSoup(resp, 'html.parser')Let us now search for the classes of elements we want to scrape.
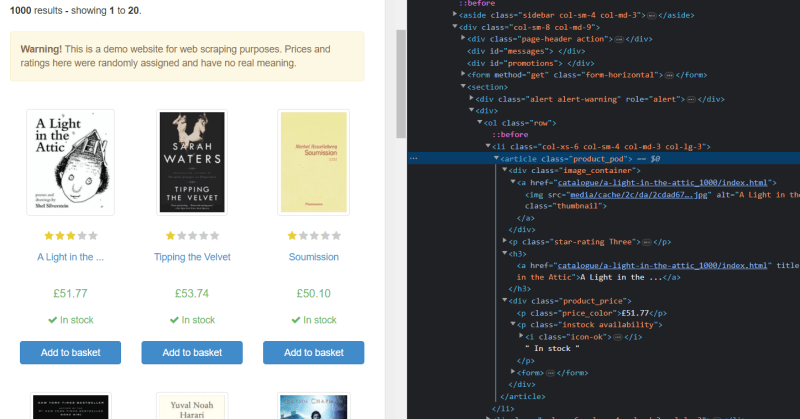
If you inspect the HTML, you will find that every product is inside the tag product_pod. And if you further go deep inside, you will find the tag for the title as h3, link to the book as a and the price of the book as price_color and so on.
After searching for all the tags, our parser should look like this:
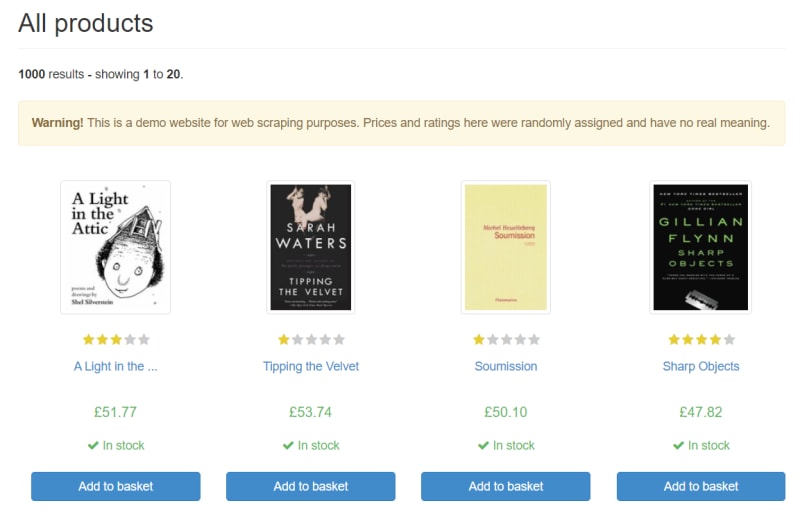
for el in soup.select("article.product_pod"): obj["title"] = el.select_one("h3").text obj["link"] = el.select_one("a")["href"] obj["price"] = el.select_one(".price_color").text obj["stock_availability"] = el.select_one(".instock").text.strip() l.append(obj) obj = {}print(l)This will give you information about twenty books present on the web page.
[ { 'title': 'A Light in the ...', 'link': 'catalogue/a-light-in-the-attic_1000/index.html', 'price': '51.77', 'stock_availability': 'In stock' }, { 'title': 'Tipping the Velvet', 'link': 'catalogue/tipping-the-velvet_999/index.html', 'price': '53.74', 'stock_availability': 'In stock' }, { 'title': 'Soumission', 'link': 'catalogue/soumission_998/index.html', 'price': '50.10', 'stock_availability': 'In stock' },.....This is how you can use Selenium for completing web scraping tasks.
Advantages of using Selenium
Selenium allows us to perform various tasks like clicking on the web page, scrolling the web page, navigating through pages, and much more.
It can also be used for taking screenshots of web pages.
It supports multiple programming languages.
It can be used to find bugs at the earlier stage of testing.
Disadvantages of using Selenium
It is slower in execution.
It has a high CPU usage.
It can increase scraping costs.
Read More: Scrape Zillow Using Python
Recap
In the above sections, we learned some of the great web scraping libraries by Python. Requests and Beautiful Soup can be an excellent combination to extract data at scale. But this requires you to handle proxy rotation and IP blockage from your end.
But, if you want to scrape websites like Google or LinkedIn at scale, you can consider using our [Google Search API](https://serpdog.io), which can handle proxy rotation and blockage on its end using its massive pool of 10M+ residential proxies.
Moreover, Serpdog APIs return results in both HTML and JSON format so that our customers dont have to manage their valuable time dealing with the complex HTML structure.
I have also prepared some quality tutorials for beginners who want to know more about web scraping:
Regular Expressions
The regex, or regular expressions, describe a sequence of characters to match certain patterns in the body of the text. It can be used to manipulate text strings, and they are common to all programming languages, such as Python, JavaScript, C++, and more.
This is one of the most helpful tools for filtering out a large piece of data from encoded HTML, requiring just a correct regex pattern.
Learning regex can be difficult at first, but you once understood the concept, it can be a useful tool.
Let us discuss how to verify a 10-digit phone number using the regex pattern.
First, we will import the regex library from Python.
import reAnd pattern:
pattern = r'^\d{3}[-\s]?\d{3}[-\s]?\d{4}$'This regex pattern also checks for any optional dashes or spaces within the phone number.
Then, we will take input from the user and check whether the entered number is a correct 10-digit phone number.
phone_number = input("Enter a 10-digit phone number: ")if re.match(pattern, phone_number): print("Valid phone number.")else: print("Invalid phone number.")Run this program in your terminal and try to enter any number.

Let me try a different number also.
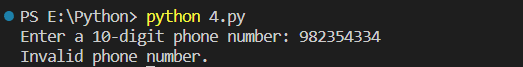
This method is quite useful when you want to scrape mobile numbers from a web page and also have to check if the picked-up mobile number is valid or invalid.
Urllib3
Urllib3 is a built-in Python library used for making HTTP requests. It was designed to use instead of Urllib2 and is also easier to use. It also allows you to make all types of HTTP requests(GET, POST, DELETE, etc.) and comes with features such as connection pooling, proxy support, and SSL/TLS verifications.
It uses various modules, let us discuss some of them:
- request Used to open and read URLs.
- error Contains the exception classes for exceptions raised by the request module.
- parse Used to parse the URLs
- robotparser Used to parse robot.txt files.
- poolmanager Used to manage HTTP connection at a given URL.
Let us try to make a GET request using Urllib3. It is quite simple.
import urllib3http = urllib3.PoolManager()response = http.request(GET, http://httpbin.org/headers')print(response.data)In the above code, after importing the library, we created an instance of the pool manager responsible for managing the HTTP connections, and then we made an HTTP request with the help of that instance on our target URL.
![]()
As discussed above, we can also use it to send POST requests.
import urllib3http = urllib3.PoolManager()response = http.request('POST', 'http://httpbin.org/post', fields = {"Blog": "Web Scraping With Python"})print(response.data)We sent a JSON object fields to the server, which will return confirming a successful request.

This library is not popular for doing web scraping tasks, or there might be negligible use of it. But, it has some advantages associated with it, lets discuss them.
Advantages of using Urllib3:
Supports connection pooling.
Has proxy support.
SSL/TLS verifications.
Disadvantages of using Urllib3:
Has limited features.
Cookie support is poor.
Socket
Socket is a Python library used for communication between two or more computers over a network.
Here is how you can make an HTTP GET request using Socket by opening a TCP Socket.
import socketHOST = 'www.google.com'PORT = 80 sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)server_address = (HOST, PORT)sock.connect(server_address)sock.send(bGET / HTTP/1.1\r
Host:www.google.com\r
\r
")response = sock.recv(4096)sock.close()print(response.decode())Step-by-step explanation:
After importing the library, we set the HOST URL and the port.
In the next line, we passed two parameters to the socket constructor: socket family and type.
Then, we initialized the server address with the address of the web server.
After that, we used the connect method with the server address as a parameter to establish a connection with the web server.
Then we made a GET request with the bytes object as a parameter.
Now, we get the response from the server using the
sock.recvwith 4096 as the buffer size.Finally, we closed the socket and printed the response received from the server.

This is how you can create a basic web scraper using Socket.
Mechanical Soup

Mechanical Soup is a Python library that is a combination of BeautifulSoup and Requests libraries. It has various features, such as interacting with web forms, handling redirects, and managing cookies.
Lets discuss how we can scrape this website using Mechanical Soup.
First, install this library by running this command in your project terminal.
pip install MechanicalSoupNow, import this library into your project file.
import mechanicalsoupbrowser = mechanicalsoup.StatefulBrowser()We created an instance of StatefulBrowser which is assigned to the variable browser, that can now be used to interact with pages.
url= "https://en.wikipedia.org/wiki/Amazon_(company)"browser.open(url)print(browser.get_current_page())browser.open() will open the web page in the session and then browser.get_current_page() will return the HTML content of the web page.
If you want to learn more about this library, you can refer to this docs page.
Conclusion
In this tutorial, we learned web scraping with Python using various libraries like Requests, Beautiful Soup, etc. I hope this tutorial gave you a complete overview of web scraping.
Please do not hesitate to message me if I missed something. If you think we can complete your custom scraping projects, feel free to contact us. Follow me on Twitter. Thanks for reading!
Additional Resources
Original Link: https://dev.to/serpdogapi/web-scraping-with-python2023-a-complete-guide-g4b
Dev To
More About this Source Visit Dev To