
An Interest In:
Web News this Week
- April 26, 2024
- April 25, 2024
- April 24, 2024
- April 23, 2024
- April 22, 2024
- April 21, 2024
- April 20, 2024
Some of Our Sources
- Simplebits
- Smashing Magazine
- You The Designer
- Inspiredology
- Web Design Ledger
- Reencoded
- Daily Now
- Dev To
- Hashedout
- TechPowerUp
Help Webnuz
Referal links:
Derive Insights from AWS Lake House | AWS White Paper Summary
Introduction
Organizations collect and analyze increasing amounts of data to make better decisions as quickly as changes occur. Traditional on-premises solutions for data storage, data management, and analytics can no longer keep pace.
Data siloes that arent built to work well together make it difficult to consolidate data to perform comprehensive and efficient analytics. This limits an organizations agility, ability to derive more insights and value from its data, and capability to adopt more sophisticated analytics tools and processes as its needs evolve.
Organizations often build data warehouse and data lake solutions in isolation from each other, each having its own separate data ingestion, storage, management, and governance layers. These disjointed efforts to build separate data warehouse and data lake ecosystems often end up creating data and processing silos, data integration complexity, excessive data movement, and data consistency issues.
These can lead to delays and increased cost of data-driven decisions, and prevent the deeper insights that come when you analyze all your relevant data together.
What is a Lake House architecture?
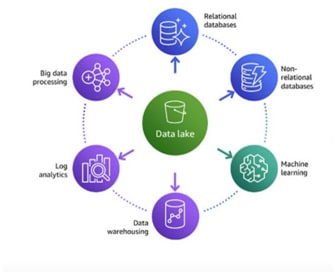
Many organizations are moving their data from various silos into a data lake, where they have a single place to apply machine learning and analytics. The vast majority of data lakes are built on Amazon Simple Storage Service (Amazon S3). At the same time,
customers are leveraging purpose-built analytics stores that are optimized for specific use cases.Customers want the freedom to move data between their centralized data lakes and the surrounding purpose-built analytics stores in a seamless, secure, and compliant way, to get insights with speed and agility. We call this modern approach to analytics Lake House architecture.

- Lake House architecture is an evolution from data warehouse and data lake-based solutions. The following table lists this evolution from data and performance characteristics.

Why use AWS for Lake House analytics?
Customers build databases, data warehouses, and data lake solutions in isolation from each other, each having its own separate data ingestion, storage, management, and governance layers.
These disjointed efforts to build separate data stores often end up creating data silos, data integration complexities, excessive data movement, and data consistency issues. These issues prevent customers from getting deeper insights. To overcome these issues and easily move data around, AWS introduced a Lake House
approach.AWS provides a broad platform of managed services to help you build, secure, and seamlessly scale end-to-end data analytics applications quickly by using a Lake House approach.
There is no hardware to procure, no infrastructure to maintain and scaleonly what you need to collect, store, process, and analyze your data. AWS offers analytical solutions specifically designed to handle this growing amount of data and provide insight into your business.
AWS purpose-built analytics services
AWS gives you the broadest and deepest portfolio of purpose-built analytics services, including Amazon Athena, Amazon EMR, Amazon Elasticsearch Service, Amazon Kinesis, and Amazon Redshift for your unique analytics use cases.
These services are all designed to be the best, which means you never have to compromise on performance, scale, or cost when using them.

Scalable data lakes
Tens of thousands of customers run their data lakes on AWS. Setting up and managing data lakes today involves a lot of manual and time-consuming tasks. AWS Lake Formation automates these tasks so you can build and secure your data lake in days instead of months.
For your data lake storage, Amazon S3 is the best place to build a data lake because it has:
- Unmatched 99.999999999% of durability and 99.99% availability.
- The best security, compliance, and audit capabilities with object level audit logging and access control.
- The most flexibility with five storage tiers.
- The lowest cost with pricing that starts at less than $1 per TB per month.
S3 gives you robust capabilities to manage access, cost, replication, and data protection.

Performance and cost-effectiveness
In addition to industry-leading price performance for analytics services, S3 intelligent tiering saves you up to 70% on storage cost for data stored in your data lake.
Amazon EC2 provides access to an industry-leading choice of over 200 instance types, up to 100 billions of bits per second (Gbps) network bandwidth, and the ability to choose between on-demand, reserved, and spot instances.
With Amazon Redshift RA3 instances with managed storage, you can choose the number of nodes based on your performance requirements, and pay only for the managed storage that you use. Advanced Query Accelerator (AQUA) is an analytics query accelerator for Amazon Redshift that uses custom-designed hardware to speed up queries that scan large datasets.
Seamless data movement
- As the data in your data lakes and purpose-built data stores continues to grow, you need to be able to easily move a portion of that data from one data store to another. AWS enables you to combine, move, and replicate data across multiple data stores andyour data lake.

Centralized governance
One of the most important pieces of a modern analytics architecture is the ability for customers to authorize, manage, and audit access to data. This can be challenging, because managing security, access control, and audit trails across all of the data stores in your organization is complex, time-consuming, and error-prone.
With capabilities like centralized access control and policies, and column-level filtering of data, no other analytics provider gives you the governance capability to manage access to all of your data across your data lake and your purpose-built data stores from a single place.
With capabilities like centralized access control and policies combined with column and row-level filtering, AWS gives you the fine-grained access control and governance to manage access to data across a data lake and purpose-built data stores from a single point of control.
Lake House architecture on AWS
As data in data lakes, data warehouses, and purpose-built stores continues to grow, it becomes harder to move all this data around. We call this data gravity. To make decisions with speed and agility, you need to be able to use a central data lake and a
ring of purpose-built data services around that data lake.You also need to acknowledge data gravity by easily moving the data you need between these data stores in a secure and governed way. AWS calls this modern approach to analytics the Lake House
Architecture.
Analytics patterns using a Lake House approach on AWS
Many organizations are moving all their data from various silos into a single location, often called a data lake, to perform analytics and ML.
These same companies also store data in purpose-built data stores for the performance, scale, and cost advantages they provide for specific use cases.
Lake House architecture on AWS provides a strategic vision of how multiple AWS data and analytics services can be combined into a multi-purpose data processing and analytics environment. There are the three analytics patterns you can derive insights from by using a Lake House approach on AWS:
- Inside-out data movement
- Outside-in data movement
- Data movement around the perimeter
Derive insights with inside-out data movement
- To get the most from your data lakes and these purpose-built stores, you need to move data between these systems easily. For example, clickstream data from web applications can be collected directly in a data lake and a portion of that data can bemoved out to a data warehouse for daily reporting. We think of this concept as insideout data movement.
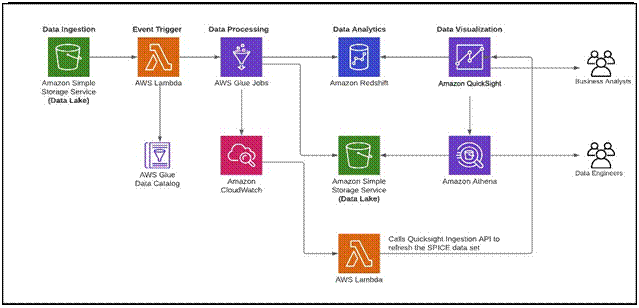
Derive real time event-based visualization insights from your Lake house with Amazon Redshift and Amazon QuickSight
The following diagram illustrates the Lake House inside-out data movement with Amazon Redshift and Amazon QuickSight to perform data visualization insights.

Derive persona-centric insights from your Lake House with AWS Glue DataBrew, Amazon Athena, Amazon Redshift, and Amazon QuickSight
The following diagram illustrates the Lake House inside-out data movement with AWS Glue DataBrew, Amazon Athena, Amazon Redshift, and Amazon QuickSight to perform persona-centric data analytics
Derive insights with outside-in data movement
- You can also move data in the other direction: from the outside-in. For example, you can copy query results for sales of products in a given Region from your data warehouse into your data lake, to run product recommendation algorithms against a larger data set using machine learning. Think of this concept as outside-in datamovement.
Derive insights from Amazon DynamoDB data for real-time prediction with Amazon SageMaker
The following diagram illustrates the Lake House outside-in data movement with DynamoDB data to derive personalized recommendations.

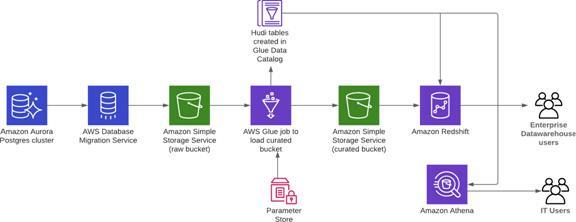
Derive insights from Amazon Aurora data with Apache Hudi, AWS Glue, AWS DMS, and Amazon Redshift
The following diagram illustrates the Lake House outside-in data movement with Amazon Aurora Postgres-changed data to derive analytics.
Derive insights with moving data around the perimeter
In other situations, you want to move data from one purpose-built data store to another: data movement around-the-perimeter.
For example, you may copy the product catalog data stored in your database to your search service to make it easier to look through your product catalog and offload the search queries from the database. We think of this concept as data movement around the perimeter.
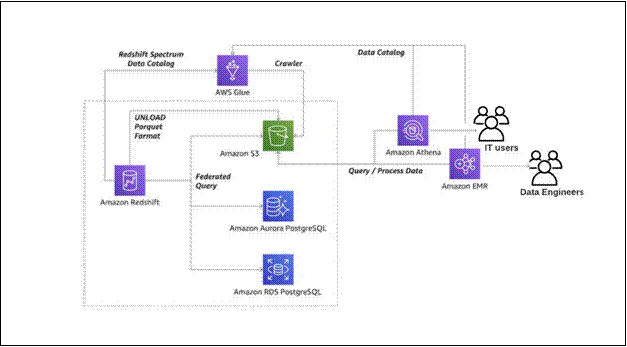
Derive insights from your data lake, data warehouse and operational databases
The following diagram illustrates the moving the data around the perimeter Lake House approach with S3, Amazon Redshift, Amazon Aurora PostgreSQL, and Amazon EMR to derive analytics.
Derive insights from your data lake, data warehouse, and purpose-built analytics stores by using Glue Elastic Views
The following diagram illustrates the moving the data around the perimeter Lake House approach with AWS Glue Elastic Views to derive insights.

Key benefits
- Lake House architecture on AWS provides the following key benefits:
- Unified analytics across operational, data warehouse, and data lake
- Democratizes machine learning with SQL, no ETL needed
- Empowers all personas use best-fit analytics services
- Security, compliance, and audit capabilities across the data lake
- Cost-effective, durable storage with global replication capabilities
- A comprehensive set of integrated tools enables every user equally
- Centralized management of fine-grained permissions empowers security officers
- Simplified ingestion and cleaning enables data engineers to build faster
Conclusion
- A Lake House architecture, built on a portfolio of purpose-built services, helps you quickly get insight from all your data to all your users. It enables you to build for the future so you can easily add new analytic approaches and technologies as they becomeavailable.
Reference
Original Link: https://dev.to/awsmenacommunity/derive-insights-from-aws-lake-house-aws-white-paper-summary-2p2m
Dev To
More About this Source Visit Dev To