
An Interest In:
Web News this Week
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
- March 26, 2024
- March 25, 2024
Some of Our Sources
- Slashdot
- Mashable
- Simplebits
- Team Treehouse
- Joshua Blankenship
- Pearsonified
- Creative Curio
- Fuel Your Creativity
- Web Design Ledger
- TechPowerUp
Help Webnuz
Referal links:
How to Rock the Party with Apollo GraphQL Cache
Hi, Im apollo-cache-inmemory a.k.a. Apollo Cache. I am the default implementation of cache in your Apollo Client. So Let me explain why we are here!
Im going to help you access and manipulate cache whenever you need. Did you perform a mutation? No worries! I can update the cache for you. Oh, by the way, that Redux guy is cool, but you may not need to store data with him anymore . Allow me
Er... Thanks, Apollo Cache for the intro, but I think Ill take it from here.
Okay, so when I first tried apollo cache it was way over my head. There are so many different use cases that I was bound to get lost. Add the __typename thing to all that confusion. So I decided to make apollo cache my friend. Here is how it went:
First, you gotta invite Apollo Cache to your party :
npm install apollo-cache-inmemory --saveNow Apollo Cache will start to rock the party out of the box. Just introduce it to Apollo Client(Apollo Client has a special liking towards cache) and boom!
const cache = new InMemoryCache();const client = new ApolloClient({ link: new HttpLink(), cache});But we want it to do a lot more things. So, make it understand your party rules so that it behaves the way you want. Something like code of conduct? We will provide the code of conduct in its constructor. By the way, this is totally optional. So here we go!
Code of Conduct:

addTypename: A boolean to specify whether to add __typename to the document. (Default is true). More on this later.
dataIdFromObject: Cache normalizes all the data before saving it in the store. This is a function that takes the data object and returns a unique id. More on its use later in the story.
fragmentMatcher: Apollo Cache by default uses heuristic fragment matcher. This is a weird thing that you need to tell apollo cache if you plan on using fragments on unions and interfaces.
cacheRedirects: Sometimes, we request data that apollo cache already has in its store but under a different resource key. With cacheRedirects, we tell apollo cache where to look for the already existing data.

Apollo Cache was instantly popular in the party. All the party guests (you can imagine them as components) were interacting with the cache. We were playing React and Act in which the cache held all the events that we could act upon and also the scores of each team. And let me tell you, it did an awesome job. Apollo cache did three things to store and retrieve the data quickly
- split the data into individual objects
- create a unique identifier for each object
- store data in a flattened data structure
It used code of conduct points addTypename and dataIdFromObject to do this. Typically cache uses id and _id fields found in the data along with __typename to create a unique identifier. If the ids are not provided in the data it will key off of __typename. dataIdFromObject function tells the cache to use a specific field in your data as a unique identifier so that it can be referenced in any interaction (query) with Apollo cache later.
I know its confusing. So, lets talk more on this:
But first, How does the cache remember everything? Simply put, Apollo cache remembers the way you interacted with it. Cache calls this as query path.
query { Events (category = 'happy') { name }}For the above query, the cache will create the query path as follows: RootQuery -> Events(category = happy) -> name. It assumes that for one query path there must be exactly one resource that it points to. So next time when anyone asks cache the same query it answers it instantly. For instance, one of the guests asked apollo cache about the team's score and list of events from category happy.
query { Score(team = 'A') { points } Events (category = 'happy') { name }}The cache already knew about the list of events as someone had already requested about it. So it answered instantly. Snappy!
The cache tries its best to remember things. But sometimes, the query path isnt clear enough. For instance, These were the questions asked by two other guests:
Guest A: Hey, Apollo Cache. Can you give me the event that falls in the category dancing?
Guest B: Cache, can you provide me with the event in 2nd category? (here the category is referenced by the id)
Now it happened that id = 2 (or second category) was actually an event that fell into dancing category. How did the cache view these requests?
// 1st Requestquery { Event (category = 'dancing') { name }}// 2nd Requestquery { Event (id = 2) { name }}Here, the cache was unaware that both the request referred to the same result. In a normal scenario, the cache would fetch that data and save it twice in its store. At this point, the cache was able to figure out what was happening with those requests using dataIdFromObject rule.
How? With a little help from us. So, in dataIdFromObject we specify a unique identifier for any object that we need to query. Here, we need to be careful that we do not provide raw ids (SQL primary keys) as a unique identifier because id = 5 can represent both an event or a guest. We need to combine this with __typename . So an identifier like Event:5 only represents event data that has id = 5 and Guest:5 only represents guest data that has id = 5.
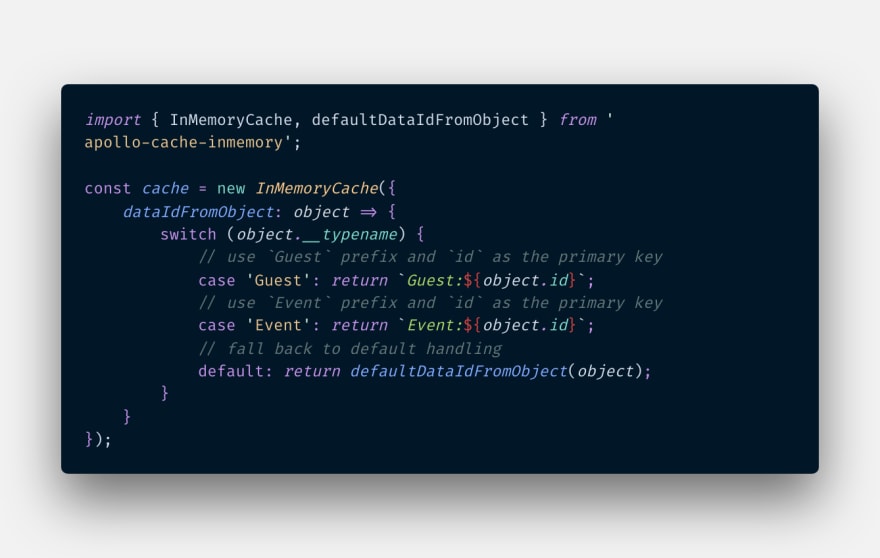
If the event name in the dancing category gets changed from bachata to salsa, both above queries will get updated answers. Easy and neat!
Apollo cache has many other tricks up its sleeve. Let's discuss them some other time!
Thanks to twitter user @DrunkBB8 fro original pictures.
Original Link: https://dev.to/akshar07/how-to-rock-the-party-with-apollo-graphql-cache-361l
Dev To
More About this Source Visit Dev To