
An Interest In:
Web News this Week
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
- March 26, 2024
- March 25, 2024
- March 24, 2024
Some of Our Sources
- Slashdot
- Mashable
- Techcrunch
- Just Creative
- Abduzeedo
- Creative Curio
- Naldz Graphics
- Specky Boy
- Web Resource Source
- Android Headlines
Help Webnuz
Referal links:
PyTorch Hello World
I recently started working with PyTorch, a Python framework for neural networks and machine learning. Since machine learning involves processing large amounts of data, sometimes it can be hard to understand the results that one gets back from the network. Before getting into anything more complicated, let's replicate a really basic backpropagation as a sanity check. To run the code in this article, you'll need to install NumPy and PyTorch.
In neural networks primer, we saw how to manually calculate the forward and back propagation for a trivial network consisting of one input neuron, one hidden layer neuron, and one output neuron:
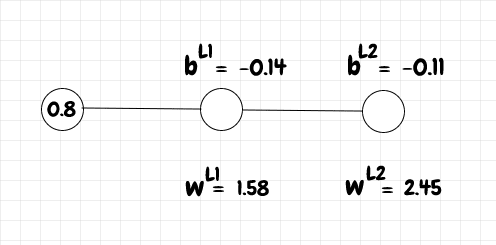
We ran an input of 0.8 through the network, then backpropagated using 1 as the target value. We used sigmoid as the activation function and the quadratic cost function to compare the actual output from the network with the desired output.
The code below uses PyTorch to do the same thing:
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.hidden_layer = nn.Linear(1, 1) self.hidden_layer.weight = torch.nn.Parameter(torch.tensor([[1.58]])) self.hidden_layer.bias = torch.nn.Parameter(torch.tensor([-0.14])) self.output_layer = nn.Linear(1, 1) self.output_layer.weight = torch.nn.Parameter(torch.tensor([[2.45]])) self.output_layer.bias = torch.nn.Parameter(torch.tensor([-0.11])) def forward(self, x): x = torch.sigmoid(self.hidden_layer(x)) x = torch.sigmoid(self.output_layer(x)) return xnet = Net()print(f"network topology: {net}")print(f"w_l1 = {round(net.hidden_layer.weight.item(), 4)}")print(f"b_l1 = {round(net.hidden_layer.bias.item(), 4)}")print(f"w_l2 = {round(net.output_layer.weight.item(), 4)}")print(f"b_l2 = {round(net.output_layer.bias.item(), 4)}")input_data = torch.tensor([0.8])output = net(input_data)print(f"a_l2 = {round(output.item(), 4)}")target = torch.tensor([1.])criterion = nn.MSELoss()loss = criterion(output, target)net.zero_grad()loss.backward()optimizer = optim.SGD(net.parameters(), lr=0.1)optimizer.step()print(f"updated_w_l1 = {round(net.hidden_layer.weight.item(), 4)}")print(f"updated_b_l1 = {round(net.hidden_layer.bias.item(), 4)}")print(f"updated_w_l2 = {round(net.output_layer.weight.item(), 4)}")print(f"updated_b_l2 = {round(net.output_layer.bias.item(), 4)}")output = net(input_data)print(f"updated_a_l2 = {round(output.item(), 4)}")Some notes on this code:
nn.Linearis used for fully connected, or dense, layers. For this simple case, we have a single input and a single output for each layer.- The
forwardmethod is called when we pass the input into the network withoutput = net(input_data). - By default, PyTorch sets up random weights and biases. However, here we initialize them directly since we want the results to match our manual calculation (shown later in the article).
- In PyTorch,
tensoris analogous toarrayin numpy. criterion = nn.MSELoss()sets up the quadratic cost function - though it's called the mean squared error loss function in PyTorch.loss = criterion(output, target)calculates the cost, also known as the loss.- Next we use
net.zero_grad()to reset the gradient to zero (otherwise the backpropagation is cumulative). It isn't strictly necessary here, but it's good to keep this mind when running backpropagation in a loop. loss.backward()computes the gradient, i.e. the derivative of the cost with respect to all of the weights and biases.- Finally we use this gradient to update the weights and biases in the network using the
SGD(stochastic gradient descent) optimizer, with a learning rate of 0.1.
The results are below:
C:\Dev\python\pytorch>python backprop_pytorch.pynetwork topology: Net( (hidden_layer): Linear(in_features=1, out_features=1, bias=True) (output_layer): Linear(in_features=1, out_features=1, bias=True))w_l1 = 1.58b_l1 = -0.14w_l2 = 2.45b_l2 = -0.11a_l2 = 0.8506updated_w_l1 = 1.5814updated_b_l1 = -0.1383updated_w_l2 = 2.4529updated_b_l2 = -0.1062updated_a_l2 = 0.8515We print out the network topology as well as the weights, biases, and output, both before and after the backpropagation step.
Below, let's replicate this calculation with plain Python. This calculation is almost the same as the one we saw in the neural networks primer. The only difference is that PyTorch's MSELoss function doesn't have the extra division by 2, so I've adjusted the code below, dc_da_l2 = 2 * (a_l2-1), to match what PyTorch does:
import numpy as npdef sigmoid(z_value): return 1.0/(1.0+np.exp(-z_value))def z(w, a_value, b): return w * a_value + bdef a(z_value): return sigmoid(z_value)def sigmoid_prime(z_value): return sigmoid(z_value)*(1-sigmoid(z_value))def dc_db(z_value, dc_da): return sigmoid_prime(z_value) * dc_dadef dc_dw(a_prev, dc_db_value): return a_prev * dc_db_valuedef dc_da_prev(w, dc_db_value): return w * dc_db_valuea_l0 = 0.8w_l1 = 1.58b_l1 = -0.14print(f"w_l1 = {round(w_l1, 4)}")print(f"b_l1 = {round(b_l1, 4)}")z_l1 = z(w_l1, a_l0, b_l1)a_l1 = sigmoid(z_l1)w_l2 = 2.45b_l2 = -0.11print(f"w_l2 = {round(w_l2, 4)}")print(f"b_l2 = {round(b_l2, 4)}")z_l2 = z(w_l2, a_l1, b_l2)a_l2 = sigmoid(z_l2)print(f"a_l2 = {round(a_l2, 4)}")dc_da_l2 = 2 * (a_l2-1)dc_db_l2 = dc_db(z_l2, dc_da_l2)dc_dw_l2 = dc_dw(a_l1, dc_db_l2)dc_da_l1 = dc_da_prev(w_l2, dc_db_l2)step_size = 0.1updated_b_l2 = b_l2 - dc_db_l2 * step_sizeupdated_w_l2 = w_l2 - dc_dw_l2 * step_sizedc_db_l1 = dc_db(z_l1, dc_da_l1)dc_dw_l1 = dc_dw(a_l0, dc_db_l1)updated_b_l1 = b_l1 - dc_db_l1 * step_sizeupdated_w_l1 = w_l1 - dc_dw_l1 * step_sizeprint(f"updated_w_l1 = {round(updated_w_l1, 4)}")print(f"updated_b_l1 = {round(updated_b_l1, 4)}")print(f"updated_w_l2 = {round(updated_w_l2, 4)}")print(f"updated_b_l2 = {round(updated_b_l2, 4)}")updated_z_l1 = z(updated_w_l1, a_l0, updated_b_l1)updated_a_l1 = sigmoid(updated_z_l1)updated_z_l2 = z(updated_w_l2, updated_a_l1, updated_b_l2)updated_a_l2 = sigmoid(updated_z_l2)print(f"updated_a_l2 = {round(updated_a_l2, 4)}")Here are the results:
C:\Dev\python\pytorch>python backprop_manual_calculation.pyw_l1 = 1.58b_l1 = -0.14w_l2 = 2.45b_l2 = -0.11a_l2 = 0.8506updated_w_l1 = 1.5814updated_b_l1 = -0.1383updated_w_l2 = 2.4529updated_b_l2 = -0.1062updated_a_l2 = 0.8515We can see that the results match the ones from the PyTorch network! In the next article, we'll use PyTorch to recognize digits from the MNIST database.
The code is available on github:
This project contains scripts to demonstrate basic PyTorch usage. The code requires python 3, numpy, and pytorch.
Assuming numpy and pytorch are installed, the scripts in this project can be run directly from the command line.
Related
Original Link: https://dev.to/nestedsoftware/pytorch-hello-world-37mo
Dev To
More About this Source Visit Dev To