
An Interest In:
Web News this Week
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
Some of Our Sources
- Slashdot
- Techcrunch
- TutsPlus - Code
- Smashing Apps
- Creative Curio
- Inspiredology
- Web Design Ledger
- CSS Globe
- Web Resource Source
- Willems Lab
Help Webnuz
Referal links:
Building personalised recommendation system (p.2)
In the first part of the series on building a personalised music recommendation system, we discussed the use of machine learning algorithms such as Collaborative Filtering and Co-occurrence Counting to create an items similarity matrix. This resulted in a set of files, each representing the similarities between various artists and tracks.
As an example, one of these files may look like this:
00FQb4jTyendYWaN8pK0wa 0C8ZW7ezQVs4URX5aX7Kqx ... 66CXWjxzNUsdJxJ2JdwvnR02kJSzxNuaWGqwubyUba0Z 137W8MRPWKqSmrBGDBFSop ... 3nFkdlSjzX9mRTtwJOzDYB04gDigrS5kc9YWfZHwBETP 0du5cEVh5yTK9QJze8zA0C ... 1Xyo4u8uXC1ZmMpatF05PJ06HL4z0CvFAxyc27GXpf02 4AK6F7OLvEQ5QYCBNiQWHq ... 26VFTg2z8YR0cCuwLzESi207YZf4WDAMNwqr4jfgOZ8y 23zg3TcAtWQy7J6upgbUnj ... 6LuN9FCkKOj5PcnpouEgnyHere, the first entry is the key entity, followed by N entities that are similar to it.
In this second part of the series, we will delve into the process of building a Node.js application that utilises this data and other information to provide real-time music recommendations to users, based on their individual tastes. We will explore the use of different database paradigms to ensure our solution is both scalable and performant.
If you're just joining and want to follow along as we build this system, but don't want to dive into the world of machine learning, you'll need the following data:
- The original raw playlist dataset, which can be found at Kaggle.
- The similarity matrices, which can be found at GitHub, and contain artist similarities (matrix factorization, MLP, and co-occurrence) and track similarities (matrix factorization).
With that out of the way, let's get started!
System Architecture
The Node.js application we are building will consist of three peripheral services and a high-level recommendation service with a fluent API, a request handler, and an express route to handle requests.
The following diagram gives a high-level overview of the application architecture:
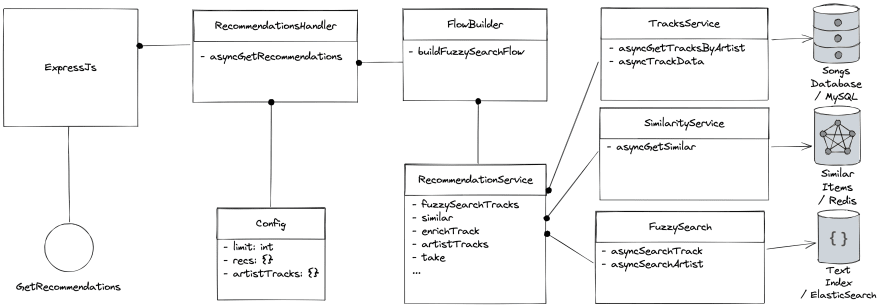
To build this app, we will start by implementing the lower-level services before moving on to the higher-level ones. This approach is known as building bottom-up, and I hope it will help understand the process better.
Services
TracksService
To store and retrieve the track and artist data, we will use a relational database paradigm. This requires us to create two tables: one for storing artists, and another for storing the tracks of each artist.
Here is the SQL code needed to create these tables:
CREATE TABLE artists ( uri varchar(32) NOT NULL, name varchar(100) NOT NULL, PRIMARY KEY (uri));CREATE TABLE tracks ( uri varchar(32) NOT NULL, name varchar(100) NOT NULL, artist_uri varchar(32) NOT NULL, PRIMARY KEY (uri), KEY artist_uri (artist_uri), CONSTRAINT tracks_fk_1 FOREIGN KEY (artist_uri) REFERENCES artists (uri));To run all the services we need, we will use Docker containers. One option is to use docker-compose with the mysql image to create these tables and store the data persistently.
Here is an example of a docker-compose.yml file that can be used to create a MySQL container and set up the necessary environment variables, volumes, and ports:
services: mysql-server: image: mysql:8.0.31 command: --default-authentication-plugin=mysql_native_password environment: MYSQL_ROOT_PASSWORD: admin123 MYSQL_DATABASE: music MYSQL_USER: user MYSQL_PASSWORD: user123 volumes: - db:/var/lib/mysql ports: - 3306:3306volumes: db:You need to have a
docker-composeinstalled on your machine.
Using the above docker-compose.yml file, we can easily start a MySQL server and connect to it from our Node.js application.
To populate the data from the raw playlist dataset into the database, we will need to write a script. I used Python for this task as it is simple to use, but since the main focus of this article is the Node.js application for recommendations, I will not go into the details of how the script works. You can find the script in the GitHub repo.
You can run this script to import the data from the raw dataset into the database. Once the data is imported, our application can then use this data to query tracks and artists.
Now, let's implement the TracksService class. This service will be responsible for handling various queries related to track data, this is the service interface:
class TrackService { /** @type {knex.Knex} */ #db constructor(db) { this.#db = db } asyncTrackData = async (trackIds) => { ... } asyncGetTracksByArtist = async (artistIds, {fanOut, randomize}) => { ... }}The first function is a simple query for track data. It selects tracks by their URI and renames the uri column to id, which we will need later on.
/** * Gets track data from db * * @param {string[]} trackIds * * @returns {Promise<Object.<string, any>[]>} tracks data */asyncTrackData = async (trackIds) => { const rows = await this.#db .select() .from('tracks') .whereIn('uri', trackIds) return rows.map(({ uri: id, ...rest }) => ({ id, ...rest }))}This function accepts an array of track IDs as an input and returns a promise that resolves to an array of track data. It uses the knex.js library to connect and query the MySQL database.
The second function of the TracksService class allows us to query track IDs by their authors. It may appear complex at first glance, but the complexity arises from the fact that we want to limit the maximum number of tracks per author.
/** * Get list of tracks per artist. * * @param {string[]} artistIds list of artist ids * @param {Object} options configuration: * @param {number} [options.fanOut] max number tracks per artist * @param {boolean} [options.randomize = false] when fan_out specified - if true, will randomly shuffle tracks before limiting * * @returns {Promise<Object.<string, string[]>>} map where key is artist_id and value is a list of artist track_ids */asyncGetTracksByArtist = async (artistIds, { fanOut = null, randomize = false } = {}) => { const rows = await this.#db .select({ track_id: 'uri', artist_id: 'artist_uri' }) .from('tracks') .whereIn('artist_uri', artistIds) const fanOutFun = randomize ? (v) => _.sampleSize(v, fanOut) : (v) => _.slice(v, 0, fanOut) const applyLimitToArtist = R.map(([k, v]) => [k, fanOutFun(v)]) const groupByArtist = R.groupBy(R.prop('artist_id')) const limitPerArtist = fanOut ? R.pipe( R.toPairs, // split object to a list of tuples applyLimitToArtist, // per tupple apply the limit function R.fromPairs // construct the object back ) : R.identity // if fanout is false, do nothing /* For each value within parent object, take field track_id Convert { artist_id1: [{ track_id: a, artist_id: artist_id1}], artist_id2: [{ track_id: b, artist_id: artist_id2}] } to { artist_id1: [a], artist_id2: [b] } */ const projectTrackId = R.mapObjIndexed(R.pluck('track_id')) return R.pipe(groupByArtist, limitPerArtist, projectTrackId)(rows)}It starts by querying an unlimited number of tracks per artist, and then, depending on the input arguments, randomly or deterministically limits the number of tracks. We make use of two additional libraries here: Ramda and Lodash for object and array manipulations.
It's important to note that artist_uri column in the tracks table is a foreign key, which means that MySQL creates a secondary index on this field. Having a secondary index ensures that our query will run quickly even when we have a large amount of data in the database, as we do not need to perform a full scan of the table.
SimilarityService
Our next service helps us to find similar entities. As you may recall, we previously created similarity matrices, which hold the similarity relations.
The service API is straightforward: given a list of entity IDs and an index (which serves as an identifier for the ML model used to build a similarity matrix), the function returns a list of similar entities.
class SimilarityService { /** @type {redis.RedisClientType} */ #redis constructor(redis) { this.#redis = redis } asyncGetSimilar = async (ids, { indexName, fan_out }) => { ... }}While it would be possible to use SQL to model this functionality, I propose using a key-value based NoSQL solution. We can use an in-memory database, such as Redis, to store our similarity matrices, as they can fit in RAM. For example, the artist files use less than 500 KB and the track files need 2 MB. Even if we had 1,000 or 10,000 more artists (and tracks), it would still fit within memory. Additionally, we can also shard if more memory is needed.
Using RAM based storage type we ensure that request is fulfilled with the least possible delay. Redis also has persistence mode, which we will use for durability of the data.
To use our similarity service, we will need to update our docker-compose file to start a Redis server as well. Here is an example of how we can do that:
services: redis: image: redis ports: - 6379:6379 volumes: - redis:/data command: redis-server --save 60 1 --loglevel warningvolumes: redis:The schema we will use for storing the similarity data in Redis is as follows:
- key: list[entity_id]
The key consists of two parts: <index_name>:<entity_id>.
We will also need a script that populates Redis with similarity data. This script can be found here. Once the script is run, it will create four different similarity indices.
With the setup in place, we can now write the implementation for the similarity service:
/** * For provided entity ids fetches similar entities * * @param {string[]} ids * @param {Object} options * @param {string} options.indexName redis index name * @param {number} [options.fanOut = 10] limit number of similar entities per entity * * @returns {Promise<Object.<string, string[]>>} map of similar entities, where key is input entity_id and values are similar entity_ids */asyncGetSimilar = async (ids, { indexName, fanOut = 10 }) => { const key = (id) => `${indexName}:${id}` // creates array of promises const pendingSimilarities = ids.map(async (id) => { const similarIds = await this.#redis.lRange(key(id), 0, fanOut) if (similarIds.length == 0) return null return [id, similarIds] }) // when promises are awaited, we get a list of tuples [id, similarIds] // ideally we want to have some error handling here const similarities = (await Promise.allSettled(pendingSimilarities)).filter((r) => r.value).map((r) => r.value) return Object.fromEntries(similarities)}The implementation is simple - it executes N concurrent requests to Redis to get array slices for the provided entity keys. It returns an object, where the key is the original entity ID and the value is an array of similar entity IDs.
Ideally we should have error handling for the promises here to handle any errors that might occur when querying Redis.
FuzzySearch
Our recommendation system is not based on user activities, and we do not have access to internal track IDs. Instead, we will be relying on arbitrary strings of text entered by the user to specify track or artist names. In order to provide accurate recommendations, we will need to implement a fuzzy search mechanism for tracks and artists.
Fuzzy search is an approach that can help us build a robust system for finding actual tracks based on user input. It allows for a degree of flexibility in the user's search queries, making it less prone to errors. A standard example of a system which supports such queries is ElasticSearch.
To begin, let's take a look at our docker-compose configuration for setting up ElasticSearch:
services: elastic: image: elasticsearch:8.6.0 ports: - 9200:9200 - 9300:9300 environment: - xpack.security.enabled=false - discovery.type=single-node volumes: - elastic:/usr/share/elasticsearch/datavolumes: elastic:In our implementation, we will be using two types of indices in ElasticSearch: one for indexing tracks with artists, and another for indexing just artists. This is similar to a reverse representation of the original SQL model.
The diagram below illustrates how we are storing and querying data in SQL:
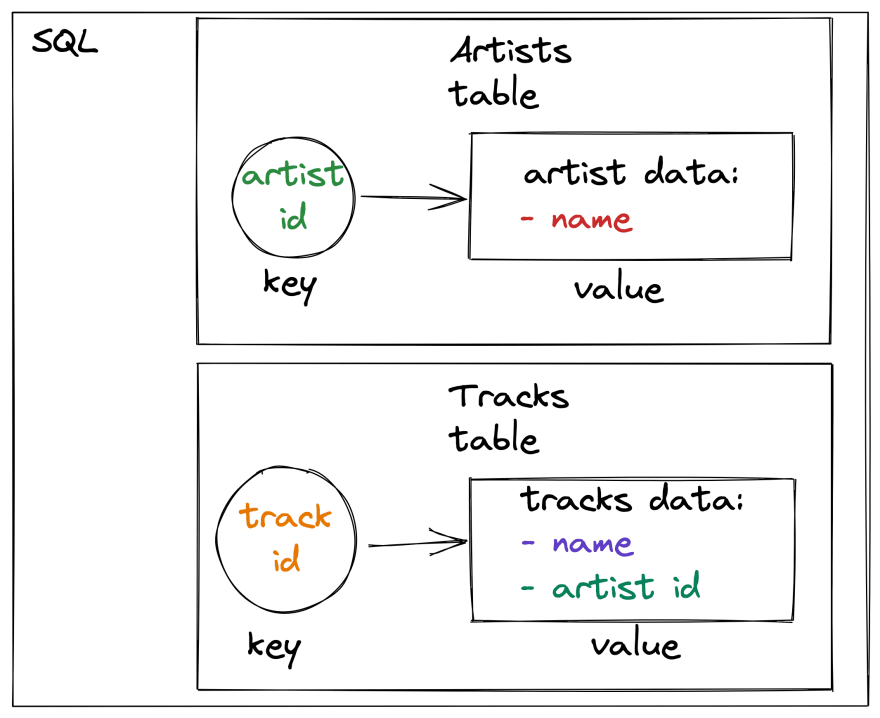
And this is how we are storing them in ElasticSearch:

The ElasticSearch indices allow us to query the required track and artist IDs by their names very quickly, providing a fast and efficient search process. This improves the overall user experience, as the system is able to provide recommendations in a timely manner.
The built-in fuzzy search mechanism enables us to handle variations in the user's input, such as misspellings or slight variations in the search query. This ensures that our system can still provide accurate recommendations even if the user's input is not perfect.
The FuzzySearch class is responsible for handling the search functionality in our recommendation system:
class FuzzySearch { /** * @type {Client} */ #es constructor(es) { this.#es = es } asyncSearchArtist = async (artists) => { ... } asyncSearchTrack = async (tracks) => { ... }}The asyncSearchArtists method is responsible for searching for artists in the "artists" index using the provided name(s) as the search query. The method uses a helper method called matchField to compose the "SELECT" part of the ElasticSearch query.
/** * @param {string} fieldName field name which need to match * @param {string} value matching value * @returns elasticsearch query for matching <fieldName> field */const matchField = (fieldName, value) => ({ match: { [fieldName]: { query: value, operator: 'AND' } }})The asyncSearchArtists method then constructs the full request, specifying the "artists" index and the query for each artist. It uses the ElasticSearch client's msearch (multiple search) method to perform the search:
/** * @param {{artist: string}[]} artists * array of query strings for matching artists * each object must contain artist name * @returns {Promise<SearchResult[]>} track and artist ids */asyncSearchArtists = async (artists) => { const { responses } = await this.#es.msearch({ searches: artists.flatMap(({ artist }) => [ { index: 'artists' }, { query: matchField('name', artist) } ]) }) return maybeGetFirstFrom(responses)}The search results returned by ElasticSearch may contain zero to many matched objects, so we need to flatten the result set. For simplicity, lets select the first result from the result set if it exists.
const maybeGetFirstFrom = (responses) => responses.flatMap((r) => { if (!r.hits.hits) return [] const { _id } = r.hits.hits[0] return [ { id: _id } ] })When searching for tracks, we have two cases: when artist name search clause is present or is missing, so lets create a helper function for constructing the query:
/** * @param {{track: string, artist: ?string}} value matching value * @returns {{match: Object}[]} array of matching clauses in elastic query dsl */const searchTrackTerms = ({ track, artist = null }) => { const trackTerm = matchField('name', track) if (!artist) { return [trackTerm] } const artistTerm = matchField('artist', artist) return [trackTerm, artistTerm]}The asyncSearchTracks method makes use of this helper function to construct the query for searching for tracks in the "tracks" index.
/** * @param {{track: string, artist: ?string}[]} tracks * array of query strings for matching tracks * each object must contain either track name or track and artist names * having artist name present increases likelyhood of finding the right track * @returns {Promise<{id: string}[]>} track ids for matched queries */asyncSearchTracks = async (tracks) => { const { responses } = await this.#es.msearch({ searches: tracks.flatMap((track) => [ { index: 'tracks' }, { query: { bool: { must: searchTrackTerms(track) } } } ]) }) return maybeGetFirstFrom(responses)}This concludes the implementation of peripheral services. In summary, we have implemented three services which well use to build our recommendation system:
- Data retrieval using an SQL model: This service allows us to quickly lookup data by its ID, providing fast access to the required information.
- Similarity retrieval using an in-memory key-value model: This service provides a blazing fast access to the similarity matrix, which is crucial for generating recommendations based on similar items.
- Fuzzy search using a text index: This service allows us to quickly find relevant entity IDs, even when the user's input is not perfect. The built-in search mechanism in the text index provides a degree of flexibility in the search process, handling variations in the user's input.
Each of these services targets to decrease latency time in their respective zones of responsibility. Together, they provide a robust and efficient ground for the recommendation system that can handle variations in user input, while providing accurate and timely recommendations.
Fluent API
In the remaining sections, we will look at how we can integrate the services we have built to create a functional recommendation system. While we could start using the services as-is, building a real-world recommendation flow would become tedious and cumbersome.
To improve the development process, we need to build a data model and a service that provides a fluent API for construction recommendation flows.
The core concepts in this data model will be a dynamic entity and a pipe. A dynamic entity represents a piece of data that can change over time, such as a user's query or a track's artist. A pipe represents a flow of data through the system, allowing us to apply different operations on the data as it moves through the system.
The data model and service will provide a simple and intuitive way to build recommendation systems, making it easy to experiment with different approaches and fine-tune the system to achieve the desired performance.
Entity
As mentioned previously, a dynamic entity is just a container of properties. It is a plain JavaScript object that can hold any properties that are relevant to the recommendation system.

We won't enforce any specific structure for this entity, and the responsibility of type checking will be on the client of this API. This allows for maximum flexibility in the data model, and makes it easy to add or remove properties as needed.
Pipe
A pipe is an asynchronous function that receives an array of entities and returns a modified array of entities. It can perform various operations on them, such as filtering, sorting, or transforming the data. For example, a pipe can filter out entities that do not meet certain criteria, sort based on a specific property, or transform the entities by adding or removing properties.
If a pipe creates a new entity, it copies over properties from the parent entity. This allows for the preservation of relevant information from the original entity, while also allowing for the addition of new properties.
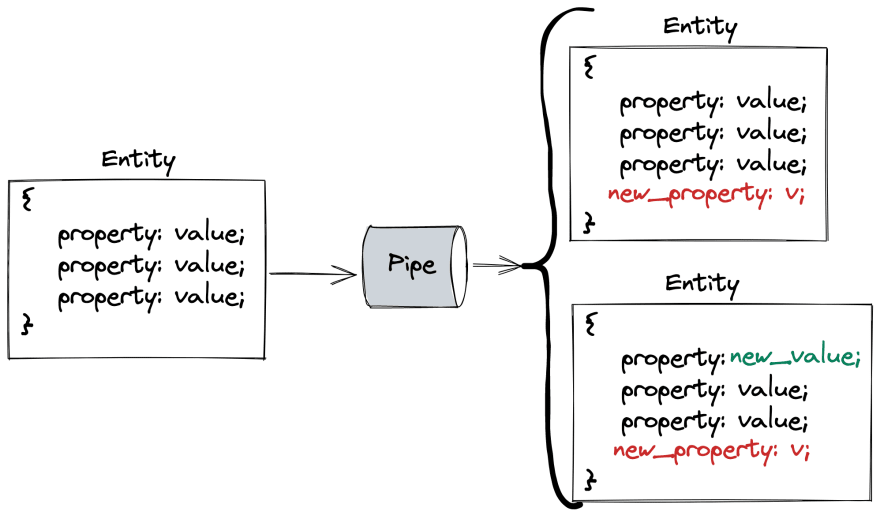
RecommendationService
With the concepts of dynamic entities and pipes, we can now introduce the RecommendationService API.
type Config = Objecttype Entity = { [string]: any }type OneOrMany<A> = A | A[]type Pipe = (OneOrMany<Entity> => Promise<Entity[]>)class RecommendationService { /* Peripheral API */ fuzzySearchTracks: Pipe fuzzySearchArtists: Pipe enrichTrack: Pipe similar: (options: Config) => Pipe artistTracks: (options: Config) => Pipe /* Util API */ dedupe: (by: string | string[]) => Pipe diversify: (by: string | string[]) => Pipe sort: (by: string | string[]) => Pipe take: (limit: int) => Pipe set: (from: string, to: string) => Pipe setVal: (key: string, value: any) => Pipe /* Composition API */ merge: (...pipes: Pipe[]) => Pipe compose: (...pipes: Pipe[]) => Pipe /* internals */ #similarityService: SimilarityService #trackService: TrackService #fuzzyService: FuzzySearch}The API is split into three main sections: peripheral API, util API and composition API.
Peripheral API provides the core services that are necessary to build a recommendation system, such as the fuzzySearchTracks, fuzzySearchArtists, enrichTrack, similar and artistTracks methods. These methods provide access to the services that were previously created and make it easy to retrieve data from the system.
Util API provides utility methods for manipulating the data as it moves through the system, such as the dedupe, diversify, sort, take, set, and setVal methods.
Composition API provides methods for composing and merging pipes. These methods allow for the creation of complex data manipulation flows by combining multiple individual pipe functions.
The full implementation of the RecommendationService service is not included in the article, but it can be found in the GitHub repository.
Lets take a look at the fuzzySearchTracks method as an example of how we can implement one of the peripheral API methods in the RecommendationService. The method takes an input of user search requests, which are represented as dynamic entities. Each entity must contain a track name and optionally an artist name:
/** * @typedef {Object.<string, any>} Entities * @param {Entity|Entity[]} input user search requests. Each entity must contain track name and optionally artist name * @returns {Promise.<Entity[]>} found track ids */fuzzySearchTracks = async (input) => { input = toArray(input) const trackInputs = input.filter((v) => v.track) const searchResults = await this.#fuzzyService.asyncSearchTracks(trackInputs) return searchResults}The fuzzySearchTracks method does not preserve any of the parent properties of the input entities, as they have no use in the recommendation flow. The method serves as an entry point and its primary function is to retrieve the relevant track ids.
The similar method is another example of how we can implement one of the peripheral API methods. It takes an input of entities and an options object, and finds similar entities.
/** * Finds similar entities. Copies properties from parent to children. * @typedef {Object.<string, any>} Entities * @param {Object|Function} options see SimilarityService#asyncGetSimilar options * @param {Entity|Entity[]} input * @returns {Promise<Entity[]>} similar entities for every entity from input */similar = (options) => async (input) => { input = toArray(input) options = _.isFunction(options) ? options() : options const ids = input.map(R.prop('id')) const similarMap = await this.#similarityService.asyncGetSimilar(ids, options) return input.flatMap((entity) => { const similar = similarMap[entity.id] || [] return similar.map((id) => ({ ...entity, id })) })}The method then maps over the input entities and for each entity, it flattens an array of similar entities by copying over the properties from the parent entity to the child entities, which get new ids. This allows for the preservation of relevant information from the original entity.
Lets also overview how composition functions work. We have two of those: merge and compose.
The merge takes a list of pipes and runs them in parallel, creating a higher-level pipe. The high-level pipe internally feeds input to the composed parts, runs them concurrently, and then merges their output.

/** * Merges few pipes into single pipe * @typedef {Object.<string, any>} Entities * @param {...(Entity[] => Promise<Entity[]>)} pipes * @returns high level pipe */merge = (...pipes) => async (input) => { // converging function receives an array of triggered promisses // and awaits all of them concurrently const convergingF = async (...flows) => (await Promise.allSettled(flows)) .filter((v) => v.value) // missing error handling .map((v) => v.value) .flat() return R.converge(convergingF, pipes)(input)}The merge function is a powerful tool that allows us to run multiple pipes concurrently, which can greatly speed up the process of generating recommendations.
The compose function is another composition function in the RecommendationService. It creates a sequential execution of pipes, where the output of one pipe is fed as input to the next pipe:

/** * Creates sequential composition of pipes * @typedef {Object.<string, any>} Entities * @param {...(Entity[] => Promise<Entity[]>)} pipes * @returns high level pipe */compose = (...pipes) => async (input) => { return R.pipeWith(R.andThen, pipes)(input)}Using the compose function we can create complex recommendation flows.
FlowBuilder
We can now utilise this API to construct a recommendation flow. The flow will be split into two branches: we will be recommending tracks based on the user's track preferences and also based on their artist preferences, as seen in the flow diagram.

The following is the interface for the flow builder:
const buildFuzzySearchFlow = (config, recs: RecommendationService) => { // Importing the fluent API interface const { fuzzySearchTracks, fuzzySearchArtists, similar, enrichTrack, artistTracks, dedupe, diversify, take, set, setVal, merge, compose } = recs // Flow implementation ...}And this is how we can implement the flow based on user search input:
const artistFlow = compose( dedupe('artist'), fuzzySearchArtists, dedupe('id'), set('id', 'recommender'), setVal('flow', 'artist-flow'), similar(config.recs.artist.mlp), dedupe('id'), artistTracks(config.artistTracks), diversify(['recommender', 'artist_id']), take(50))const trackFlow = compose( fuzzySearchTracks, dedupe('id'), set('id', 'recommender'), setVal('flow', 'track-flow'), similar(config.recs.track), dedupe('id'), diversify('recommender'), take(50))return compose( merge(artistFlow, trackFlow), dedupe('id'), diversify('flow'), take(config.limit), enrichTrack)Lets dive into the specifics of the artist recommendations branch.
To begin, we use the compose function to build a sequential chain of underlying pipes. This allows us to perform a series of operations in a specific order.
First, we use the dedupe function to take unique artist names (based on the user's search input) and then query ElasticSearch to retrieve artist IDs. Then, we use the dedupe function again to ensure that the results from ElasticSearch are also unique.
dedupe('artist')fuzzySearchArtistsdedupe('id')Next, we use the set and setVal functions to create new properties on each entity.
set('id', 'recommender')setVal('flow', 'artist-flow')The set function creates a new property called "recommender" by copying the value of the entity's "id" property. The setVal function creates a new property called "flow" with a constant value of "artist-flow". These two functions will allow us to trace the origin of recommendations later on when needed.
We then move on to finding similar artists to the ones provided by the user.
similar(config.recs.artist.mlp)dedupe('id')This is done by querying the similar index with values specified in the config file. We then use the dedupe function again to remove any duplicate results.
Finally, the last step in the artist flow is to retrieve the songs for the recommended artists and limit the number of results.
artistTracks(config.artistTracks)diversify(['recommender', 'artist_id'])take(50)To ensure a more natural shuffle of the results, the diversify function is used, which uses a Round-Robin shuffling mechanism:

When we call the full flow, we will receive results similar to the example shown below.
[ { id: '1VpSH1BPdKa7KYVjH1O892', recommender: '711MCceyCBcFnzjGY4Q7Un', flow: 'artist-flow', artist_id: '4F84IBURUo98rz4r61KF70', name: 'The Air Near My Fingers', artist_uri: '4F84IBURUo98rz4r61KF70' }, { id: '32lm3769IRfcnrQV11LO4E', flow: 'track-flow', recommender: '08mG3Y1vljYA6bvDt4Wqkj', name: 'Bailando - Spanish Version', artist_uri: '7qG3b048QCHVRO5Pv1T5lw' }, { id: '76wJIkA63AgwA92hUhpE2V', recommender: '711MCceyCBcFnzjGY4Q7Un', flow: 'artist-flow', artist_id: '1ZwdS5xdxEREPySFridCfh', name: 'Me Against The World', artist_uri: '1ZwdS5xdxEREPySFridCfh' }, ...]Each result will have properties such as "id", "recommender", "flow", "artist_id", "name", and "artist_uri". These properties provide information about the recommended track, as well as where it came from in the recommendation flow.
The full code, that includes a request handler and express app, can be found in the GitHub repository.
That's it. I hope you have enjoyed building the recommendation systems and learned something new!
Original Link: https://dev.to/vhutov/building-personalised-recommendation-system-p2-53gk
Dev To
More About this Source Visit Dev To