
An Interest In:
Web News this Week
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
Some of Our Sources
- Slashdot
- TutsPlus - Code
- Web Designer Wall
- Spoon Graphics
- Smashing Magazine
- Inspiredology
- Naldz Graphics
- Specky Boy
- Web Resource Source
- Android Headlines
Help Webnuz
Referal links:
Building a Data Lakehouse for Analyzing Elon Musk Tweets using MinIO, Apache Airflow, Apache Drill and Apache Superset
Every act of conscious learning requires the willingness to suffer an injury to one's self-esteem. That is why young children, before they are aware of their own self-importance, learn so easily.
Thomas Szasz
Motivation
A Data Lakehouse is a modern data architecture that combines the scalability and flexibility of a data lake with the governance and performance of a data warehouse. This approach allows organizations to store and analyze large amounts of structured and unstructured data in a single platform, enabling more efficient and effective data-driven decision making.
To deep dive in this, we will build a Data lakehouse solution for analyzing tweets from Elon Musk using MinIO as storage, Apache Drill as query engine, Apache Superset for visualization and Apache Airflow for orchestration. This article will take you through the process of building and utilizing this solution to gain insights and make data-driven decisions.
Then, well use Docker-Compose to easily deploy our solution.
Architecture
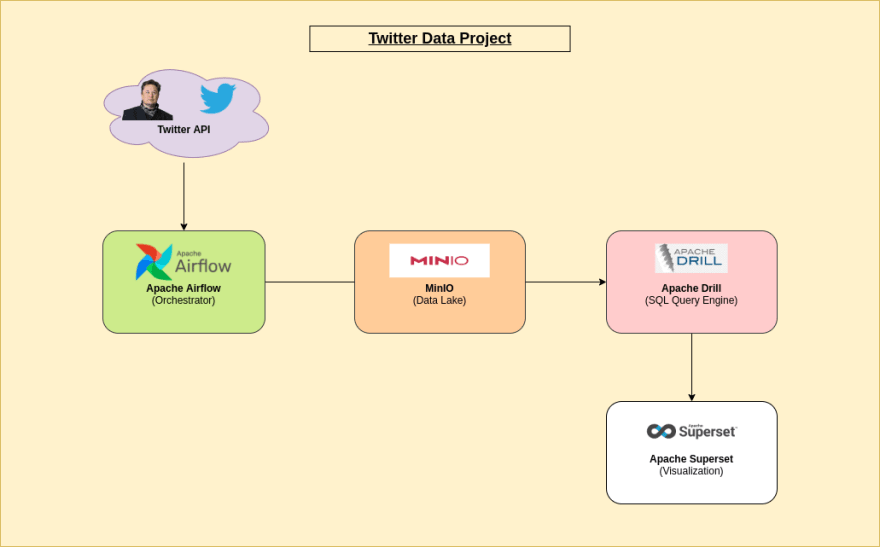
Table of Content
- What is Apache Airflow?
- What is MinIO ?
- What is Apache Drill ?
- What is Apache Superset ?
- Code
- get_twitter_data()
- clean_twitter_data()
- write_to_bucket()
- DAG (Direct Acyclic Graph)
- Apache Drill Configuration
- Apache Superset Configuration
- docker-compose & .env files
- Result
What is Apache Airflow
Airflow is a platform created by the community to programmatically author, schedule and monitor workflows.
Apache Airflow is an opensource workflow orchestration written in Python. It uses DAG (Direct Acyclic Graphs) to represent workflows. It is highly customizable/flexible and have a quite active community.
You can read more here.
What is MinIO
MinIO offers high-performance, S3 compatible object storage.
MinIO is an opensource Multi-cloud Object Storage and fully compatible with AWS s3. With MinIO you can host your own on-premises or cloud Object storage.
You ca read more here.
What is Apache Drill
Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage.
MinIO is an opensource Multi-cloud Object Storage and fully compatible with AWS s3. With MinIO you can host your own on-premises or cloud Object storage.
You ca read more here.
What is Apache Superset
Apache Superset is a modern data exploration and visualization platform.
Superset is fast, lightweight, intuitive, and loaded with options that make it easy for users of all skill sets to explore and visualize their data, from simple line charts to highly detailed geospatial charts.
You ca read more here.
Code
The full code can be accessed here:
Source code:
https://github.com/mikekenneth/twitter_data-lakehouse_minio_drill_superset
get_twitter_data()
Below is the python Task that pulls Elons tweets from Twitter API into a Python list:
import osimport jsonimport requestsfrom airflow.decorators import dag, task@taskdef get_twitter_data(): TWITTER_BEARER_TOKEN = os.getenv("TWITTER_BEARER_TOKEN") # Get tweets using Twitter API v2 & Bearer Token BASE_URL = "https://api.twitter.com/2/tweets/search/recent" USERNAME = "elonmusk" FIELDS = {"created_at", "lang", "attachments", "public_metrics", "text", "author_id"} url = f"{BASE_URL}?query=from:{USERNAME}&tweet.fields={','.join(FIELDS)}&expansions=author_id&max_results=50" response = requests.get(url=url, headers={"Authorization": f"Bearer {TWITTER_BEARER_TOKEN}"}) response = json.loads(response.content) print(response) data = response["data"] includes = response["includes"] return data, includesclean_twitter_data()
Below is the python Task that cleans & transform the tweets in the right format:
from uuid import uuid4from datetime import datetimefrom airflow.decorators import dag, task@taskdef clean_twitter_data(tweets_data): data, includes = tweets_data batchId = str(uuid4()).replace("-", "") batchDatetime = datetime.now().strftime("%Y-%m-%d %H:%M:%S") # Refine tweets data tweet_list = [] for tweet in data: refined_tweet = { "tweet_id": tweet["id"], "username": includes["users"][0]["username"], # Get username from the included data "user_id": tweet["author_id"], "text": tweet["text"], "like_count": tweet["public_metrics"]["like_count"], "retweet_count": tweet["public_metrics"]["retweet_count"], "created_at": tweet["created_at"], "batchID": batchId, "batchDatetime": batchDatetime, } tweet_list.append(refined_tweet) return tweet_list, batchDatetime, batchIddump_data_to_bucket()
Below is the python task transforms the tweets list into a Pandas Dataframe, then writes it in our MinIO Object Storage as a Parquet file.
import osfrom airflow.decorators import dag, task@taskdef write_to_bucket(data): tweet_list, batchDatetime_str, batchId = data batchDatetime = datetime.strptime(batchDatetime_str, "%Y-%m-%d %H:%M:%S") import pandas as pd from minio import Minio from io import BytesIO MINIO_BUCKET_NAME = os.getenv("MINIO_BUCKET_NAME") MINIO_ROOT_USER = os.getenv("MINIO_ROOT_USER") MINIO_ROOT_PASSWORD = os.getenv("MINIO_ROOT_PASSWORD") df = pd.DataFrame(tweet_list) file_data = df.to_parquet(index=False) client = Minio("minio:9000", access_key=MINIO_ROOT_USER, secret_key=MINIO_ROOT_PASSWORD, secure=False) # Make MINIO_BUCKET_NAME if not exist. found = client.bucket_exists(MINIO_BUCKET_NAME) if not found: client.make_bucket(MINIO_BUCKET_NAME) else: print(f"Bucket '{MINIO_BUCKET_NAME}' already exists!") # Put parquet data in the bucket filename = ( f"tweets/{batchDatetime.strftime('%Y/%m/%d')}/elon_tweets_{batchDatetime.strftime('%H%M%S')}_{batchId}.parquet" ) client.put_object( MINIO_BUCKET_NAME, filename, data=BytesIO(file_data), length=len(file_data), content_type="application/csv" )DAG (Direct Acyclic Graph)
Below is the DAG itself that allows specifying the dependencies between tasks:
from datetime import datetimefrom airflow.decorators import dag, task@dag( schedule="0 * * * *", start_date=datetime(2023, 1, 10), catchup=False, tags=["twitter", "etl"],)def twitter_etl(): raw_data = get_twitter_data() cleaned_data = clean_twitter_data(raw_data) write_to_bucket(cleaned_data)twitter_etl()Apache Drill Configuration
To grant Apache Drill access to our MinIO (s3) bucket, we need to defining Access Keys in the Drill
core-site.xmlfile:<?xml version="1.0" encoding="UTF-8" ?><configuration> <property> <name>fs.s3a.access.key</name> <value>minioadmin</value> </property> <property> <name>fs.s3a.secret.key</name> <value>minioadmin</value> </property> <property> <name>fs.s3a.endpoint</name> <value>http://minio:9000</value> </property> <property> <name>fs.s3a.connection.ssl.enabled</name> <value>false</value> </property> <property> <name>fs.s3a.path.style.access</name> <value>true</value> </property></configuration>Next, well configure the S3 Storage Plugin to specify the buckets to be access by Apache Drill in the
storage-plugins-override.conffile:"storage": { s3: { type: "file", connection: "s3a://twitter-data", workspaces: { "root": { "location": "/", "writable": false, "defaultInputFormat": null, "allowAccessOutsideWorkspace": false } }, formats: { "parquet": { "type": "parquet" }, "csv" : { "type" : "text", "extensions" : [ "csv" ] } }, enabled: true }}
You can read more here.
Apache Superset Configuration
To be able to query Apache-Drill, we need to build a custom image of apache/superset using superset_drill.Dockerfile:
FROM apache/superset# Switching to root to install the required packagesUSER root# install requirements for Apache DrillRUN pip install sqlalchemy-drill# Switching back to using the `superset` userUSER supersetYou can read more here.
docker-compose & .env files
Below is the .env file that we need to create that hold the environmental variables needed to run our pipeline:
You can read this to learn our to generate the TWITTER_BEARER_TOKEN.
# TwitterTWITTER_BEARER_TOKEN="TOKEN"# MinioMINIO_ROOT_USER=minioadminMINIO_ROOT_PASSWORD=minioadminMINIO_BUCKET_NAME='twitter-data'# SupersetSUPERSET_USERNAME=adminSUPERSET_PASSWORD=admin#Apache Airflow## Meta-DatabasePOSTGRES_USER=airflowPOSTGRES_PASSWORD=airflowPOSTGRES_DB=airflow## Airflow CoreAIRFLOW__CORE__FERNET_KEY=''AIRFLOW__CORE__EXECUTOR=LocalExecutorAIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION=TrueAIRFLOW__CORE__LOAD_EXAMPLES=FalseAIRFLOW_UID=50000AIRFLOW_GID=0## Backend DBAIRFLOW__DATABASE__SQL_ALCHEMY_CONN=postgresql+psycopg2://airflow:airflow@postgres/airflowAIRFLOW__DATABASE__LOAD_DEFAULT_CONNECTIONS=False## Airflow Init_AIRFLOW_DB_UPGRADE=True_AIRFLOW_WWW_USER_CREATE=True_AIRFLOW_WWW_USER_USERNAME=airflow_AIRFLOW_WWW_USER_PASSWORD=airflow_PIP_ADDITIONAL_REQUIREMENTS= "minio pandas requests"And below is the docker-compose.yaml file that allow to spin up the needed infrastructure for our pipeline:
version: '3.4'x-common: &common image: apache/airflow:2.5.0 user: "${AIRFLOW_UID}:0" env_file: - .env volumes: - ./app/dags:/opt/airflow/dags - ./app/logs:/opt/airflow/logsx-depends-on: &depends-on depends_on: postgres: condition: service_healthy airflow-init: condition: service_completed_successfullyservices: minio: image: minio/minio:latest ports: - '9000:9000' - '9090:9090' volumes: - './data:/data' env_file: - .env command: server --console-address ":9090" /data healthcheck: test: [ "CMD", "curl", "-f", "http://localhost:9000/minio/health/live" ] interval: 30s timeout: 20s retries: 3 drill: env_file: - .env image: apache/drill:latest ports: - '8047:8047' - '31010:31010' volumes: # If needed, override default settings - ./conf/drill/core-site.xml:/opt/drill/conf/core-site.xml # Register default storage plugins - ./conf/drill/storage-plugins-override.conf:/opt/drill/conf/storage-plugins-override.conf stdin_open: true tty: true superset_drill: env_file: - .env ports: - '8088:8088' build: context: . dockerfile: superset_drill.Dockerfile volumes: - ./superset.db:/app/superset_home/superset.db postgres: image: postgres:13 container_name: postgres ports: - "5433:5432" healthcheck: test: [ "CMD", "pg_isready", "-U", "airflow" ] interval: 5s retries: 5 env_file: - .env scheduler: <<: *common <<: *depends-on container_name: airflow-scheduler command: scheduler restart: on-failure ports: - "8793:8793" webserver: <<: *common <<: *depends-on container_name: airflow-webserver restart: always command: webserver ports: - "8080:8080" healthcheck: test: [ "CMD", "curl", "--fail", "http://localhost:8080/health" ] interval: 30s timeout: 30s retries: 5 airflow-init: <<: *common container_name: airflow-init entrypoint: /bin/bash command: - -c - | mkdir -p /sources/logs /sources/dags chown -R "${AIRFLOW_UID}:0" /sources/{logs,dags} exec /entrypoint airflow versionResult
When we access the Apache-Airflow Web UI, we can see the DAG and we can run it directly to see the results.
DAG (Apache-Airflow web UI):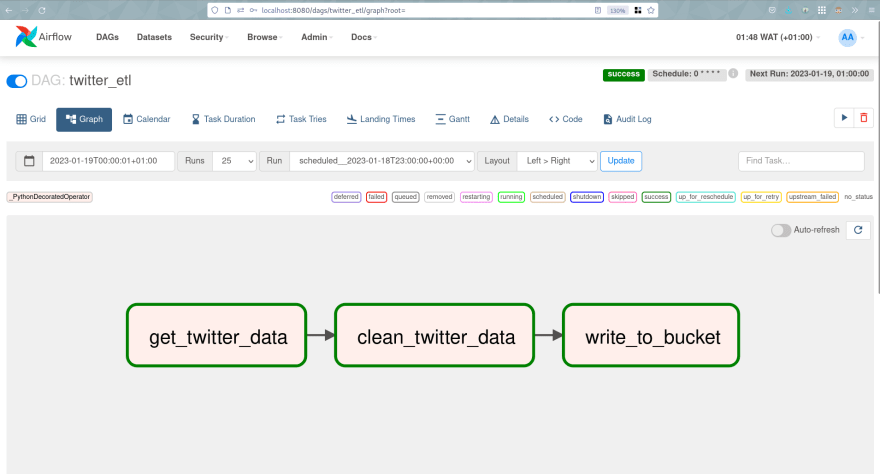
Tweets Parquet file generated in our bucket (MinIO Console):

If needed, we can query our Data-Lakehouse directly using Apache-Drill Web Interface:
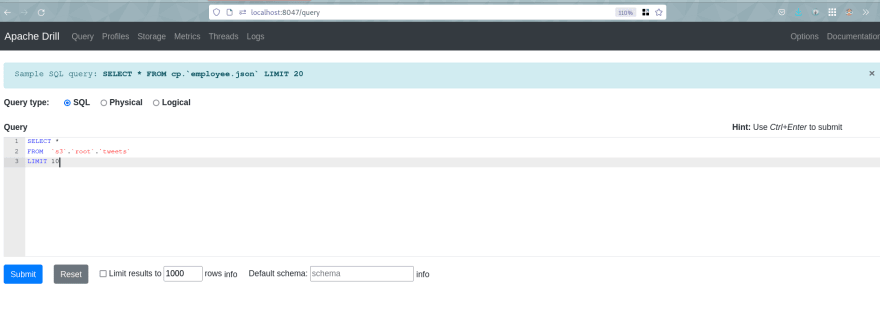
Finally, we can visualize our Dashboard (I built this already, but it can be easily modified and the data is stored in the
superset.dbfile):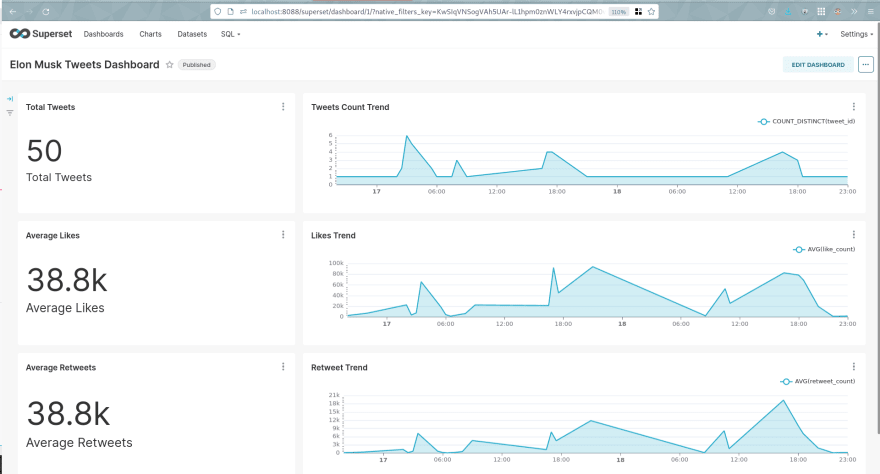
This is a wrap. I hope this helps you.
About Me
I am a Data Engineer with 3+ years of experience and more years as a Software Engineer (5+ years). I enjoy learning and teaching (mostly learning ).
You can get in touch with me through Twitter & LinkedIn or [email protected].
Original Link: https://dev.to/mikekenneth77/building-a-data-lakehouse-for-analyzing-elon-musk-tweets-using-minio-apache-airflow-apache-drill-and-apache-superset-2i3d
Dev To
More About this Source Visit Dev To