
An Interest In:
Web News this Week
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
Some of Our Sources
- Pearsonified
- Spoon Graphics
- You The Designer
- Web Designer Depot
- Fudge Graphics
- Wal You
- Web Resource Source
- Codrops
- The Verge
- TechPowerUp
Help Webnuz
Referal links:
Moving data from CockroachDB to PostgreSQL or YugabyteDB
A user asked on the YugabyteDB community slack how to migrate from CockroachDB. You may think that "wire-compatibility" with PostgreSQL makes it easy, it is not. The ways we usually export data from PostgreSQL doesn't work with CRDB. However because PostgreSQL is powerful and YugabyteDB benefits from all those SQL features, there is an easy solution with Foreign Data Wrapper.
Start the lab
For this test I'm starting the two databases in Docker, initialize the TPCC demo database in CockroachDB and create an empty one in YugabyteDB
# start containersdocker run --network yb -d --rm --name yb -p 5433:5433 -p 7000:7000 -p 15433:15433 yugabytedb/yugabyte:latest bash -c "yugabyted start --background false --tserver_flags="ysql_beta_features=true""docker run --network yb -d --rm --name cr -p 26257:26257 cockroachdb/cockroach:latest bash -c "cockroach start-single-node --insecure"# create demo tpcc tables in docker exec -it cr cockroach workload init tpcc# create empty db in PGHOST=localhost PGPORT=5433 PGUSER=yugabyte PGDATABASE=yugabyteuntil pg_isready ; do sleep 1 ; done | uniq &&psql -c "create database tpcc"PGDATABASE=tpccDDL: Migrate the schema
CRDB accepts connections though the PostgreSQL protocol but is not compatible with the PostgreSQL catalog views, and then doesn't support pg_dump:
Franck@YB:~ $ pg_dump -U root -h localhost -p 26257 -d tpcc -spg_dump: error: query failed: ERROR: column "x.tableoid" does not existpg_dump: error: query was: SELECT x.tableoid, x.oid, x.extname, n.nspname, x.extrelocatable, x.extversion, x.extconfig, x.extcondition FROM pg_extension x JOIN pg_namespace n ON n.oid = x.extnamespaceHowever, they provide a proprietary way to generate the CREATE TABLE statements:
# export ddlpsql -U root -h localhost -p 26257 -d tpcc -Ato ddl.sql -c "show create all tables"I like this simple command, even if not compatible with PostgreSQL, it is a good workaround for the absence of pgdump --schema-only.
I have extracted the DDL in a ddl.sql file: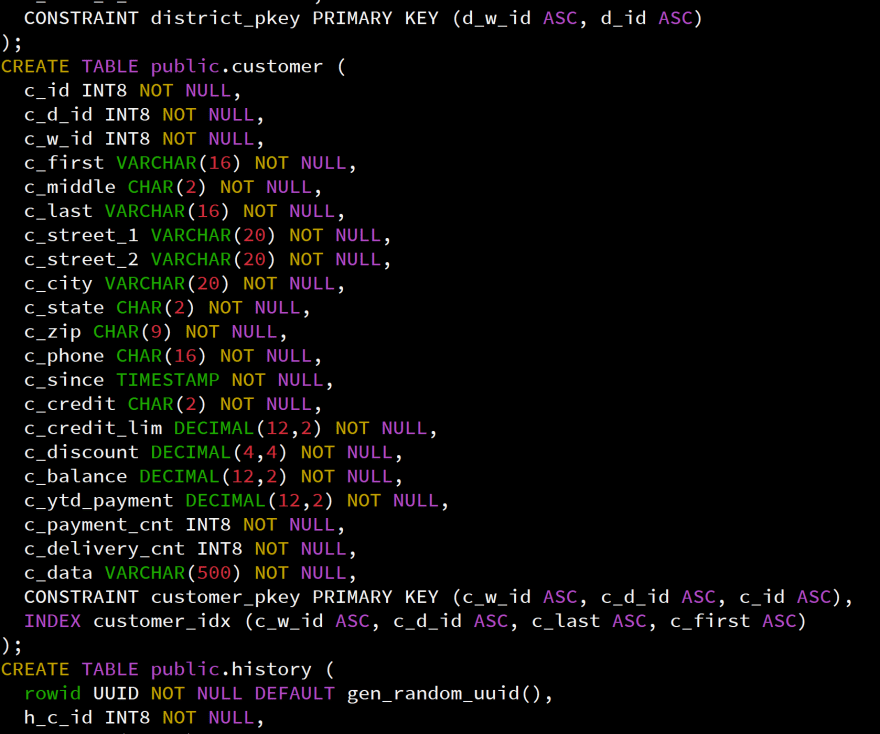
As you can see, the DDL generated is not PostgreSQL-compatible. I have been working with a lot of SQL databases and have never seen this. In SQL we create indexes with CREATE INDEX. Indexes can be created implicitly from CREATE TABLE to enforce unique constraints, but declaring an index with the logical attributes (columns and constraints) is not common.
I've quickly written a small awk script to get it back to PostgreSQL-compatible DLL:
awk '# create extensions that are default in CRNR==1{ print "create extension if not exists pgcrypto;" > "tab-"FILENAME}# remove all reference to schema public/TABLE public[.]/{ $0=gensub(/(REFERENCES |TABLE )public[.]/,"\\1","g")}# move commas at the end of lines to the begining of next linenextline!=""{ $0=gensub(/(^*)(.*)$/,"\\1"nextline"\\2",1) nextline=""}/,$/{ sub(/,$/,"") nextline=","}# INDEX clause in the CREATE TABLE is not a SQL syntax/^CREATE TABLE/{ table=gensub(/^CREATE TABLE (.*) [(]/,"\\1",1)}/^*,(UNIQUE )?INDEX/{ indexes=indexes"
"gensub(/ STORING /," INCLUDE ",1,gensub(/^*,(UNIQUE )?(INDEX)([^(]+)(.*)( STORING)?(.*)$/,"create \\1\\2 \\3 on "table" \\4 \\5 \\6;",1)) $0=gensub(/(^*),(.*)$/,"\\1--\\2",1)}# validate constraints at creation/^ALTER TABLE.*ADD CONSTRAINT.*/{ $0=gensub(/(.*)(NOT VALID)?(;)$/,"\\1\\3",1) {print > "ref-"FILENAME} $0="--"$0}/^ALTER TABLE.*VALIDATE CONSTRAINT.*;$/{$0="--"$0}# print that to the create table file{print > "tab-"FILENAME}END{print indexes > "ind-"FILENAME}' ddl.sqlThis does a few additional transformations:
- remove references to
publicschema to be able to create into a dedicated one - move the ending comma (
,) to the beginning of next line to make it easier to comment out - comment the INDEX declaration and generate the CREATE INDEX statement to run after the import of data
- add create extension for the functions that CRDB use without declaration (
gen_random_uuid()here) - I move the creation of referential integrity constraints into another script to run it at the end, instead of creating them immediately as NOT VALID. By the way, with COPY in YugabyteDB you can create them before and import DISABLE_FK_CHECK if you want to bypass the check
The result goes in a tab-ddl.sql file for the table creation, ind-ddl.sql for the secondary indexes and ref-ddl.sql for the foreign keys.
This is easy to run on the YugabyteDB target, I'm defining search_path to create those tables in a tpcc schema (this is the reason I removed references to public in the DDL script):
psql -v ON_ERROR_STOP=1 \ -c 'create schema tpcc' -c 'set search_path=tpcc,"$user", public' \ -ef tab-ddl.sql | tee tab-ddl.logI'm using the PostgreSQL psql here with failure on the first error because when you migrate data, you don't want any unseen surprise. Better stop than expecting you to read the log.
I can see the tables from the YugabyteDB web console on http://localhost:15433/

They are empty. Ready to import data.
DML: Migrate the data
Dump
CockroachDB has no tool to dump data in a format that is easy to import elsewhere. You may be surprised by that, but I'm not. Oracle was famous by providing a SQL*Loader with no SQL*Unloader (the rumors say that it was ready to be released when Larry Ellison decided to remove a tool that makes it too easy to move out of his major source of revenues).
The same with CockroachDB:
- In 2017, supporting
pg_dumpis not a priority and the solution iscockroach dump( https://github.com/cockroachdb/cockroach/issues/20296) - In 2020, this alternative
cockroach dumpis deprecated (https://github.com/cockroachdb/cockroach/issues/54040) - Later, exporting to CSV seem to be the solution but there is no reliable tool provided
Export to CSV
The answers to the absence of dump mention an export to CSV with cockroach sql --format csv. I tried it but it is just displaying the result with commas to separate fields. It doesn't provide the quality needed for a migration. For example, I tried with the TPCC schema but encountered many errors in timestamp format or even worse: no distinction between a NULL value and the 'NULL' character string:
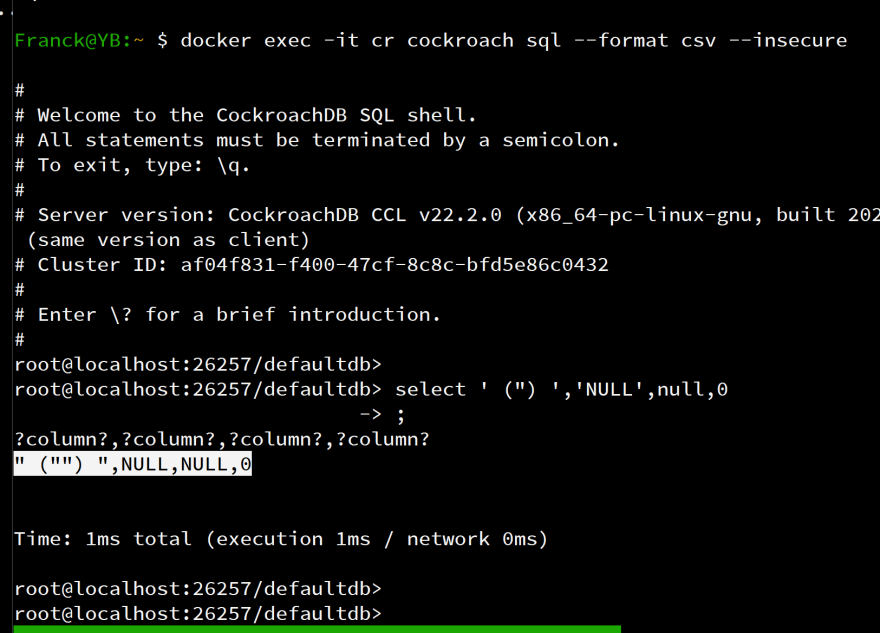
as you can see, " ("") ",NULL,NULL,0 is the CSV for (' (") ','NULL',null,0) where it should be " ("") ",NULL,,0
For a migration, you cannot rely on such a tool.
As a comparison, here is what PostgreSQL or YugabyteDB provides:

Foreign Data Wrapper
As YugabyteDB is PostgreSQL compatible, we can use the Foreign Data Wrapper. Of course it also depend on the compatibility of the remote database. I tried this in psql:
psql <<'SQL'CREATE EXTENSION postgres_fdw;CREATE SERVER cr FOREIGN DATA WRAPPER postgres_fdw OPTIONS ( host 'cr', port '26257', dbname 'tpcc');CREATE USER MAPPING FOR yugabyte SERVER cr OPTIONS ( user 'root', password '');IMPORT FOREIGN SCHEMA public FROM SERVER cr INTO public;\detSQLand this was looking good...
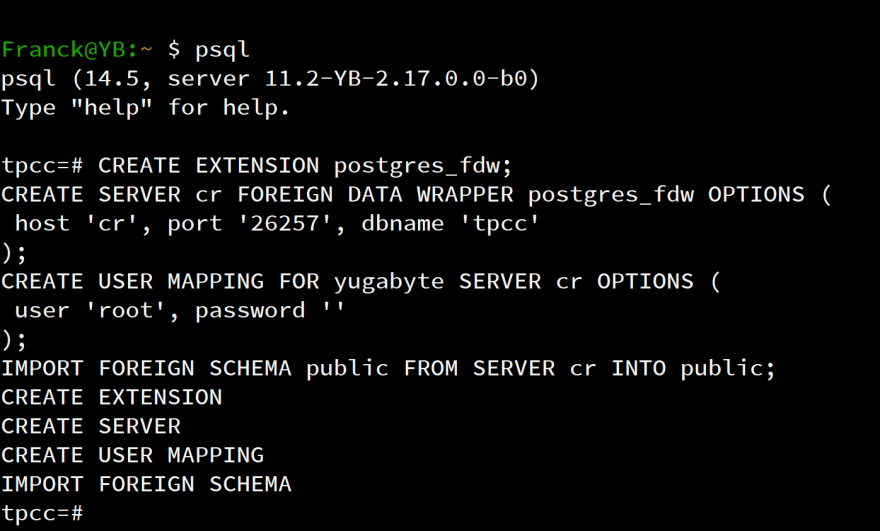
...except that nothing is there:
yugabyte=# \det List of foreign tables Schema | Table | Server--------+-------+--------(0 rows)Unfortunately nothing was imported from the schema. This is not a surprise as CockroachDB is not compatible with PostgreSQL catalog views.
Let's try with a table, declaring the structure:
CREATE foreign TABLE warehouse ( w_id INT8 NOT NULL ,w_name VARCHAR(10) NOT NULL ,w_street_1 VARCHAR(20) NOT NULL ,w_street_2 VARCHAR(20) NOT NULL ,w_city VARCHAR(20) NOT NULL ,w_state CHAR(2) NOT NULL ,w_zip CHAR(9) NOT NULL ,w_tax DECIMAL(4,4) NOT NULL ,w_ytd DECIMAL(12,2) NOT NULL) server cr;this looks good:
CREATE FOREIGN TABLEtpcc=# \det List of foreign tables Schema | Table | Server--------+-----------+-------- public | warehouse | cr(1 row)tpcc=# select * from warehouse; w_id | w_name | w_street_1 | w_street_2 | w_city | w_state | w_zip | w_tax | w_ytd------+--------+------------+------------+--------+---------+-----------+--------+----------- 0 | 8 | 17 | 13 | 11 | SF | 640911111 | 0.0806 | 300000.00(1 row)tpcc=# insert into tpcc.warehouse select * from warehouse;INSERT 0 1tpcc=# select * from tpcc.warehouse; w_id | w_name | w_street_1 | w_street_2 | w_city | w_state | w_zip | w_tax | w_ytd------+--------+------------+------------+--------+---------+-----------+--------+----------- 0 | 8 | 17 | 13 | 11 | SF | 640911111 | 0.0806 | 300000.00(1 row)tpcc=# truncate table tpcc.warehouse;TRUNCATE TABLEI was able to read data from CockroachDB and insert it into my YugabyteDB. Great. I'll do that for all tables. I have removed what I imported because I'll automate this for all tables.
As in YugabyteDB we are like in PostgreSQL, with the same catalog views, I'm generating the CREATE FOREIGN TABLE and INSERT from it:
withn as ( select oid as relnamespace , nspname as sch from pg_namespace where nspname ='tpcc'), c as ( select oid as attrelid , relnamespace , relname as tab from pg_class where relkind='r'), a as ( select attrelid , attname as col , format('%I %s',attname,format_type(atttypid, atttypmod)) as def from pg_attribute where attnum>0 and not attisdropped)select format( 'create foreign table %I (%s) server cr' ,tab , string_agg(def,', ') )from n natural join c natural join a group by sch,tabunion allselect format( 'insert into %I.%I(%s) select %s from %I' ,sch ,tab ,string_agg(col,',') ,string_agg(col,','),tab)from n natural join c natural join a group by sch,tabunion allselect format( 'drop foreign table %I' ,tab )from n natural join c\gexecThis generates the statements reading the structure of the target tabels (in schema tpcc) and executes the result with \gexec:

My warehouse foreign table was already created, the others are created here. Then rows are imported. And at the end I drop the foreign tables to be sure we don't use them anymore. The application can now work on the new tables in YugabyteDB after creating the secondary indexes and foreign keys:
psql -v ON_ERROR_STOP=1 \ -c 'set search_path=movr,"$user", public' \ -ef ind-ddl.sql | tee ref-ddl.logAll this is an example and can be customized. For large tables, you may want to pre-split them, but if not, YugabyteDB can auto-split when they grow. And if you prefer to go though CSV files, create the foreign tables only and use PostgreSQL COPY to get a reliable CSV file. Here is how to generate the \copy commands with the previous query WITH clause:
...union allselect format( '\copy (select * from %I) to %L csv;' ,tab,tab||'.csv' )from n natural join c;Of course, your application must be down for this kind of migration. To reduce downtime (and stress) there are replication solutions like https://www.arcion.io/connectors which has all connectors.
If you are migrating from CockroachDB you may be surprised by the new possibilities offered by PostgreSQL-compatible ecosystem. All this was standard PostgreSQL queries, on pg_catalog schema, with psql and \gexec. I didn't install any other tools here. And they are reliable because a tons of PostgreSQL users work with it on all kind of data, for years. YugabyteDB re-uses the same code for the SQL layer, changing only what is needed to scale-out with high performance.
Original Link: https://dev.to/franckpachot/moving-data-from-cockroachdb-to-postgresql-or-yugabytedb-462h
Dev To
More About this Source Visit Dev To