
An Interest In:
Web News this Week
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
Some of Our Sources
- Team Treehouse
- Spoon Graphics
- Smashing Apps
- Inspiredology
- FanExtra - PSD
- Noupe
- Line 25
- 24 Ways
- Spyre Studios
- The Verge
Help Webnuz
Referal links:
Finding bugs by fuzzing your code
If you have ever worked on a large scale project, you know that finding and tracking bugs can be very tedious and lengthy.
Did you know it could be automated? There are multiple ways to achieve this, starting with unit & integration tests run regularly to detect regressions, end-to-end tests to ensure a functionality is behaving as intended, and much more.
However, writing those tests is also a lengthy process, and you miss some hard to find bugs. We are going to focus on fuzzing, an automated crash detection process.
What is fuzzing?
According to wikipedia, fuzzing is an automated software testing technique that involves providing invalid, unexpected, or random data as inputs to a computer program (https://en.wikipedia.org/wiki/Fuzzing).
Given a set of inputs your program can work on, a fuzzer will generate as much diverging data as possible and feed it to your program, recording each crash.
Fuzzing in practice
If you don't know me yet, I am the developper of ArkScript, an easy to embed scripting language, and I have worked on dozen of new functionalities this past year. However, this can (and it has) introduce bugs, sometimes quite tricky to find.
Fuzzing comes to the rescue here! I didn't want (nor had time) to write thousands of tests by hand, so I just wrote the basic tests, checking that every good input leads to the expected output. What was missing was the "bad input leads to bad output" kind of tests.
Introducing AFL++
AFL++ is a superior fork of AFL (American Fuzzy Lop), a fuzzer originally developed by Google.
Here is how it operates:
It is very easy to use, you have to recompile your project using afl-cc and/or afl-c++, give it an input corpus, and let it work for you until you are satisfied.
Generating an input corpus
Since I wanted to fuzz a programming language, my input corpus was easy to put together: code samples, parts of the standard library, some tests files.
The process is as follows:
- given the corpus, we want to generate an unique corpus to remove inputs from the corpus that do not produce a new path/coverage in the target
- minimizing the corpus: the shorter the input files that still traverse the same path within the target, the better the fuzzing will be.
# step 1)afl-cmin -i fuzzing/corpus -o fuzzing/unique -- ${buildFolder}/arkscript @@ -L ./libmkdir -p fuzzing/inputcd fuzzing/unique# step 2)for i in *; do afl-tmin -i "$i" -o "../input/$i" -- ../../${buildFolder}/arkscript @@ -L ../../libdoneYou may have noticed the -- ${buildFolder}/arkscript @@ -L ./lib bit: this is the command to run the inputs against, with @@ being the filename of the input generated by AFL++.
Then we can run the fuzzer as follows, and get crashes:
afl-fuzz -i fuzzing/input -o fuzzing/output -s 0 -- ${buildFolder}/arkscript @@ -L ./libThe -s 0 is here to set the RNG seed to 0, to be able to reproduce RNG based crashes more easily ; every crash will be stored under fuzzing/output/.
And here we are, the fuzzer is running and finding bugs for us.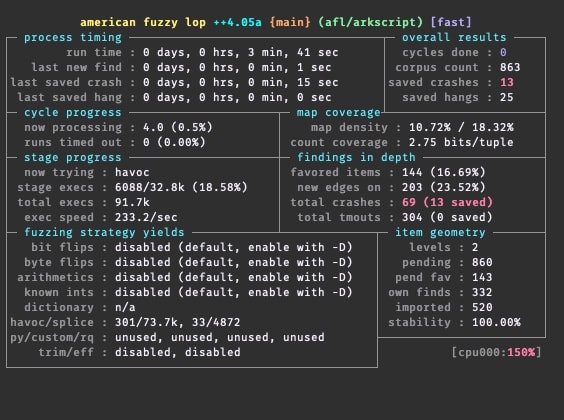
Analysing crashes
Now comes the hard part, reducing the input to find the smallest input sample which still generates the bug. Oftentimes, this has to be done by hand, and it is a tedious process, but finding those buggy inputs by hand would have taken much more time, so it's still a win!
AFL++ has tools to minimize the crashes, helping you to find the bugs:
afl-tmin -i fuzzing/output/main/crashes/id... -o fuzzing/minimized_result -- ./build/arkscript @@ -L ./libOnce you have your smallest input possible for a given crash, and you have fixed it, it is a good idea to keep it somewhere to be able to run the next version(s) of your program on it and see if it is still fixed. This has personally helped me starting a collection of bad inputs, to check in my tests if they are correctly handled.
Some things to note about fuzzing:
- a lot of crashes can be very similar, when the AFL++ fuzzer finds a bugs it will use it and derive it to find others
- because of 1) you might want to run multiple fuzzers at the same time, it will find more bugs, plus it was designed to work that way (one master instance and multiple variants)
- you don't have to limit the memory allocated to each fuzzer, but if you don't you might exhaust all your RAM
- a fuzzer can run for a very long time and not find anything, that doesn't mean your program is bug free!
Because fuzzing can require a lot of time and ressources, you might want to run those tests once in a while, for example for every new release instead of for every commit or test added.
Original Link: https://dev.to/superfola/finding-bugs-by-fuzzing-your-code-1b0e
Dev To
More About this Source Visit Dev To