
An Interest In:
Web News this Week
- April 25, 2024
- April 24, 2024
- April 23, 2024
- April 22, 2024
- April 21, 2024
- April 20, 2024
- April 19, 2024
Some of Our Sources
- Simplebits
- Web Designer Wall
- Team Treehouse
- Web Designer Depot
- Reencoded
- Specky Boy
- Spyre Studios
- Daily Now
- The Verge
- TechPowerUp
Help Webnuz
Referal links:
Vaultree and AlloyDB: the world's first Fully Homomorphic and Searchable Cloud Encryption Solution
What is AlloyDB?
AlloyDB is a fully managed PostgreSQL compatible database service that Google claims to be twice as fast for transactional workload compared to AWS Aurora PostgreSQL. If you've worked with Google Cloud already, you probably had some contact with CloudSQL for PostgreSQL and Spanner, which offers a PostgreSQL interface. So, what's actually new about this AlloyDB?
AlloyDB at the core is the standard PostgreSQL with changes in the kernel to leverage Google Cloud infrastructure at full by disaggregating compute and storage at every layer of the stack. What does it mean? This architecture allows the storage layer to be better equipped to handle changing workloads, more elastic and distributed, fault-tolerant and highly available.
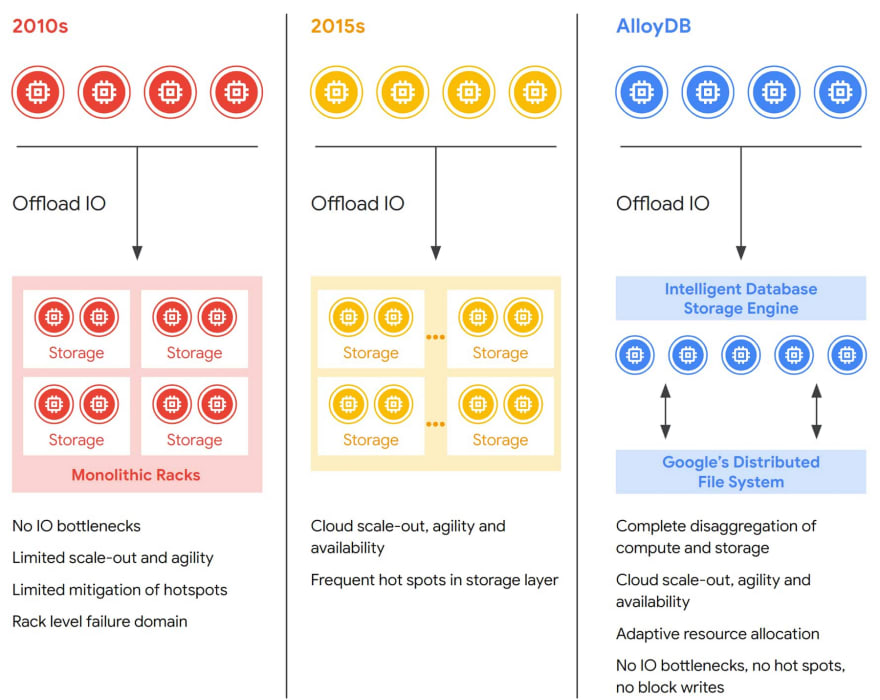
Figure 1: Evolution of disaggregation of compute and storage
Image Credit: Google
AlloyDB brings an Intelligent Database Storage Engine that basically helps offload many housekeeping operations using the Log Processing System (LPS) to the storage layer. This further increases the throughput for primary instances as they can now focus only on the queries rather than the maintenance operations. It also enables smart caching, actively updating cache based on the most frequent database queries.
Overall Architecture
AlloyDB is branched into Database layer and Storage layer. So, the database layer is used to be compatible with PostgreSQL protocol, parsing SQL statements and converting them into read/write requests to address to the storage layer. When it comes to the storage layer, it can be subdivided into three layers.
Log storage layer: The DB layer converts writes into operation logs, or WALs and writes them to the storage layer. It is responsible for effective writing and storage of these log records.
LPS Layer: The Log Processing Service (LPS) layer absorbs the WALs from the log storage layer and generates blocks, which is a Materialised process.
Block Storage Layer: The block layer corresponding to standalone PostgreSQL, used to serve queries, providing parallelism through sharding and fault tolerance between zones through replication.
I will make it more clear with the following image:
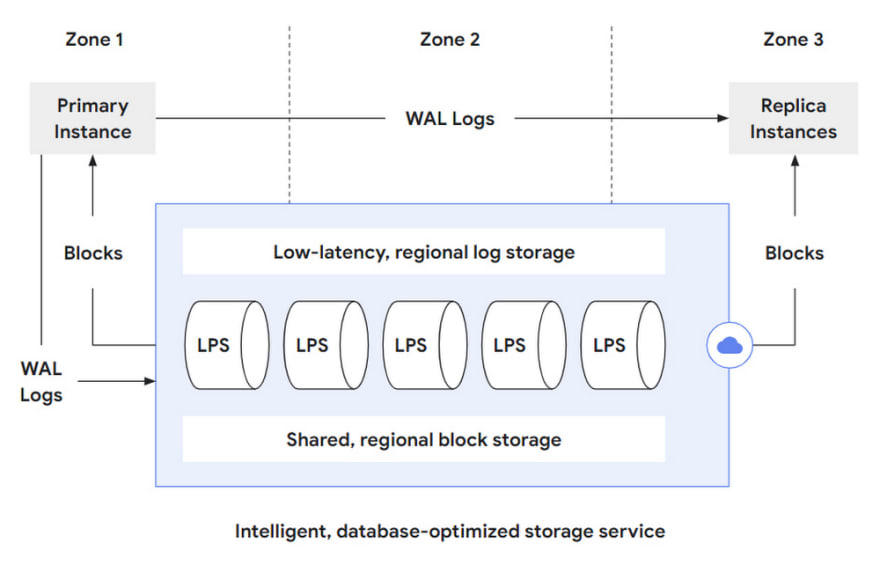
Figure 2: Overview of PostgreSQL as integrated with the storage service.
Image Credit: Google
That is, AlloyDB splits its storage layer into two storage layers and one compute layer to disentangle the complexity of them.
log storage layer, which takes over the write requests from the database layer. But it only supports append writes, so it can achieve low latency and high availability, and can use LSN to do read/write concurrency control and distributed transactions.
The block storage layer takes over the query requests from the database layer. Although not mentioned in the text, it blindly guesses that the block provided only supports single write multiple reads (write once then becomes immutable), in order to facilitate version control and caching.
The LPS layer, the data mover between the two sub-storage layers, is responsible for both block generation and reading, stateless and scalable. Instances can be dynamically added or deleted to keep track of changing load based on various signals such as load and statistical information.
The storage layer is essentially to provide block read and write services, AlloyDB split out the log storage layer for writing and the block storage layer for reading. Materialising the storage tier based on log services is a classic architecture in the field of distributed databases, but how to combine them efficiently is still a test of engineering abilities.
Another great aspect of the log service-based materialisation is that the same data can be materialised in different ways to support different workloads, such as materialising data on demand into data formats optimised for TP and AP, i.e., supporting HTAP.
Read and Write Flow
A write request, a SQL insert for example, initiated by the client to the primary instance, is parsed by the database layer and sent to the storage layer as a set of WAL Records. After a successful WAL synchronous write, the transaction commit is successfully returned. After that, LPS materialises the logs asynchronously as Blocks.

Figure 3: Processing of a write operation in AlloyDB
Image Credit: Google
The article found on Google's AlloyDB official page did not expand on this, but how to segment and fault-tolerant the logs, how to deploy them in multiple locations, and how to manage the log lifecycle are also critical design points.
A read request (a SQL query for instance), initiated by the client to any instance, is parsed at the database layer and returned directly if it hits the cache in that database layer; if there is not enough data cache for the request, it can go to a larger, second-level cache-like Ultra-fast Cache to retrieve it, and if it hits, it can still not access the storage layer.
If the Ultra-fast Cache is still missing the required block, a block read request is sent to the storage layer with block id and LSN.
Block id is used to retrieve the block.
LSN is used to wait for LPS to apply progress to ensure consistency in the visualisation.
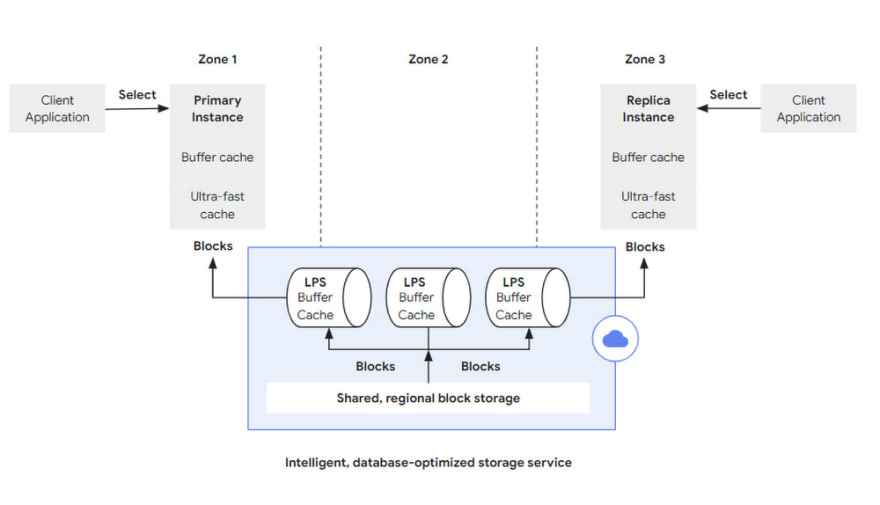
Figure 4: Processing of a read operation in AlloyDB
Image Credit: Google
In the storage layer, LPS's are responsible for block reads and writes, and each LPS maintains a Buffer Cache, which is an interesting term.
Buffer, which is generally used when writing to improve write throughput by combining multiple writes into only one block.
Cache, generally used for reads, bridges the access speeds of different media to decrease latency.
Here, the two are combined into one, LPS first writes to its own Buffer Cache during log replay, at which time the Buffer Cache acts as a buffer to be flushed to the block storage in bulk; LPS receives a Buffer Cache before it flushes the Buffer Cache to the block storage, if it receives a block read request and hits the Buffer Cache before it flushes the Buffer Cache to the block storage, it can return directly, and then the Buffer Cache acts as the cache.
Of course, LPS needs to keep a data structure like a dirty table for Buffer Cache to track the life cycle of each block and the expiration time of the next swipe.
Resilient Scaling
To handle varying loads, the number of LPS instances is designed to be scalable: that is, to adjust the mapping relationship between the LPS and the block shard. Before explaining further how to scale, let's clarify the concept of block, shard and LPS instances and the relationship.
A set of blocks is assembled into a shard, and a shard is handled by at most one LPS instance, but an LPS instance can handle multiple shards at the same time.
By analogy with a restaurant, a block can be understood as a guest, a shard as a table and an LPS instance as a waiter:
When the load is low, only one waiter is needed to serve all the guests at the restaurant tables.
When the load is too high, even one waiter can be assigned to each table.
This dynamic setting can be fully automated without user awareness or intervention. And since LPS is stateless (Buffer Cache doesn't count as state, think why), it can scale quickly.
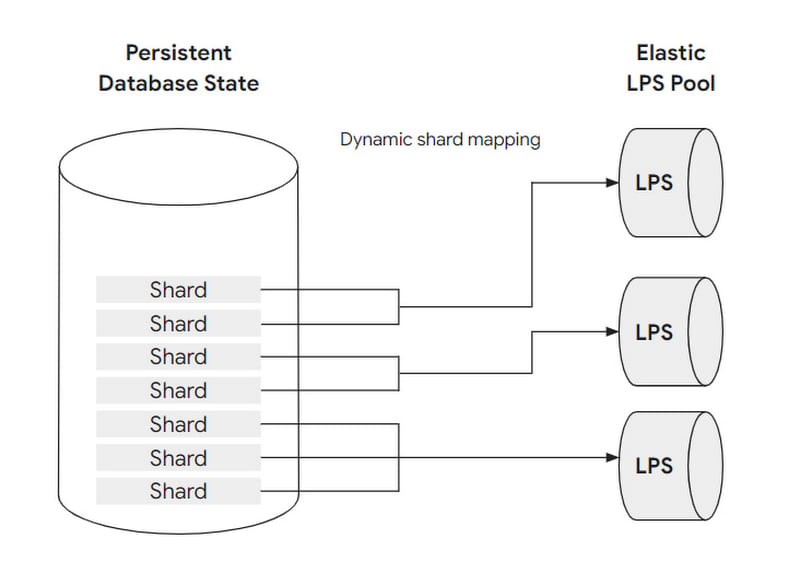
Figure 5: Dynamic mapping of shards to LPS instances allows for load balancing and LPS elasticity
Image Credit: Google
Zones
To tolerate zone failures, AlloyDB places multiple copies of each block slice in different zones.
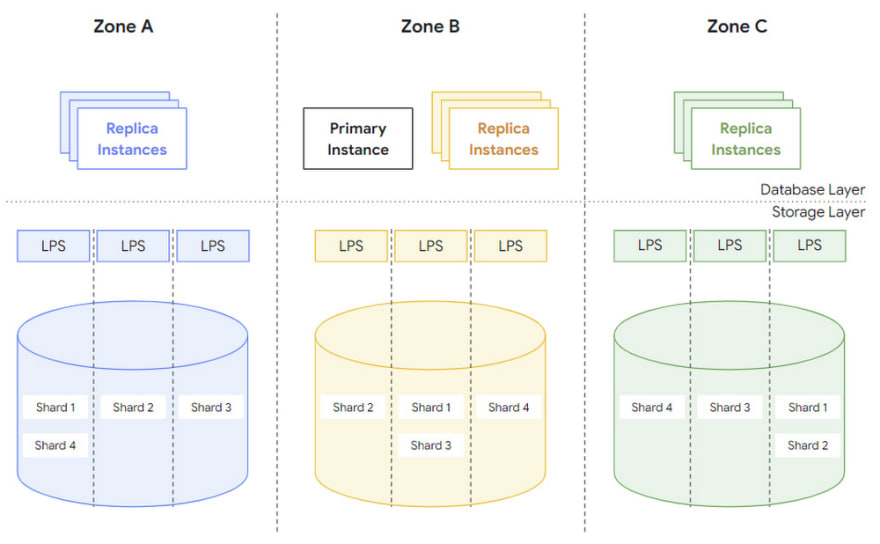
Figure 6: The fully replicated, fully sharded, multi-zone database state
Image Credit: Google
In the official Google article it reads:
"The goal of AlloyDB is to provide data durability and high system availability even in case of zonal failures, e.g., in case of a power outage or a fire in a data centre. To this end, the storage layer of every AlloyDB instance is distributed across three zones. Each zone has a complete copy of the database state, which is continuously updated by applying WAL records from the low-latency, regional log storage system discussed above."
There are two concepts mentioned in the official AlloyDB announcement, region and zone, region refers to physical region and zone refers to logical region. When a zone fails, a new zone is pulled in the same region and the data is recovered:
First use a snapshot of another copy to recover.
Then play back the WAL after that snapshot.
Under normal situations, each zone can be serviced independently and there is no specific amount of traffic between zones.
Furthermore, AlloyDB also supports logical manual and automatic backups (e.g. a database) to prevent users from accidentally deleting data.
Final Thoughts on AlloyDB
This is a welcome addition to Google Cloud's database offering and could be an excellent offering to enable companies to confidently move their legacy Oracle databases to GCP somewhere in the future.
In my opinion, Google has built some fantastic database services like Bigtable and Spanner, which literally changed the industry for good, and I am eager to see how they will build upon this new service. With AlloyDB's disaggregated architecture, the dystopian world where I only pay for SQL databases per query and the stored data on GCP seems closer than ever.
Vaultree + AlloyDB
Congratulations to whoever made it this far in this article because the best part starts now!
The question you may have: where does Vaultree enter the AlloyDB story?
Vaultree's Data-in-Use Encryption is now available for Google's AlloyDB! We know how fast and performant AlloyDB can be, however, we at Vaultree are also concerned about the security of your data in AlloyDB. Some of you might think that Fully Homomorphic Encryption was not possible in the cloud, right? Well, I bring you good news with great joy: Vaultree has done it!
Via this brilliant partnership with Google's AlloyDB, we hope to achieve a new stage in data security through:
Processing encrypted data and never decrypt, no matter if simple search, broad analysis or complex computation
Keeping it simple and transparent with zero friction to the environment, staff and processes where Vaultree is installed
Power up using Vaultree encryption technology with performance comparable to processing unencrypted data
How It Works
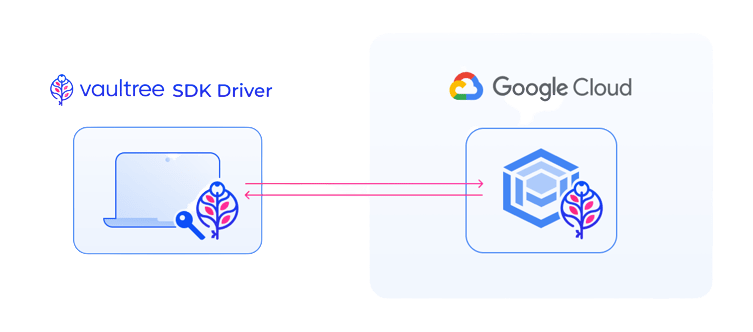
Vaultrees solution consists of two components one installed on the database, the other on the application. Applications, architecture, and database(s) remain unchanged, aside from insertion of the Vaultree components.
Choose what to encrypt
Encrypt only what you want, PII or what you deem sensitive info - stay lean
No server-side decryption
Query & Compute always encrypted data and choose where it is decrypted, nobody will ever see your data
Manage your own keys
Maintain full control of your keys via your preferred KMS
Minimal performance loss
Process your fully encrypted data with comparable performance to that of processing unencrypted data
Zero learning and changes
No change to the existing query languages and syntax, rely only on standard SQL
Zero overhead implementation
No change to the data structure, architecture, network topology, or policies / permissions
An Encrypted Tomorrow
Vaultree's unprecedented development and innovation are geared towards meeting customers' data protection needs and legal requirements with unparalleled performance and simplicity.
The only way forward is always encrypted. To date, missing usability and performance has limited the adoption of encryption-in-use solutions, but Vaultree made it possible and took one step further: Taking it into Google Cloud. - Tilo Weigandt, Co-Founder & COO.
AlloyDB combines the best of Google with one of the most popular open-source database engines, PostgreSQL, for superior performance, scale, and availability. With this preview, Vaultree is enabling Google's AlloyDB customers to preview a reliable, fast and seamless integration of the most advanced encryption product on the market. Check it out yourself.
About Vaultree
Vaultrees Encryption-in-use enables businesses of all sizes to process (search and compute) fully end-to-end encrypted data without the need to decrypt. Easy to use and integrate, Vaultree delivers peak performance without compromising security, neutralizing the weak spots of traditional encryption or other Privacy Enhancing Technology (PET) based solutions. Follow Vaultree on Twitter (@Vaultree), LinkedIn, Reddit (r/Vaultree) or dev.to. Visit www.vaultree.com, sign up for a product demo and our newsletter to stay up to date on product development and company news.

Original Link: https://dev.to/vaultree/vaultree-and-alloydb-the-worlds-first-fully-homomorphic-and-searchable-cloud-encryption-solution-26kj
Dev To
More About this Source Visit Dev To