
An Interest In:
Web News this Week
- April 18, 2024
- April 17, 2024
- April 16, 2024
- April 15, 2024
- April 14, 2024
- April 13, 2024
- April 12, 2024
Some of Our Sources
- Engadget
- Technology Review
- Web Designer Wall
- Smashing Apps
- Abduzeedo
- Fuel Your Creativity
- Crazy Leaf Design
- CSS Globe
- Freelance Switch
- Willems Lab
Help Webnuz
Referal links:
Deep Learning Library From Scratch 6: Integrating new autodiff module and MNIST digit classifier
Hello and welcome to part 6 of this series of building a deep learning library from scratch.
The github repo for this series is....
 ashwins-code / Zen-Deep-Learning-Library
ashwins-code / Zen-Deep-Learning-Library
Deep Learning library written in Python. Contains code for my blog series on building a deep learning library.
Zen - Deep Learning Library
A deep learning library written in Python.
Contains the code for my blog series where we build this library from scratch
- mnist.py contains an example for a MNIST digit recogniser using the library
- rnn.py contains an example of a Recurrent Neural Network which learns to fit to the graph sin(x) * cos(x)
What are we doing?
If you recall from the previous post, we finished the code for our automatic differentiation module (for now at least!)
Deep learning libraries rely on an automatic differentiation module to handle the backpropagation process during model training. However, our library currently calculates weight derivatives "by hand". Now that we have our own autodiff module, let's have our library use it to carry out backpropagation!
We are also going to build a digit classifier to test out if everything works.
What was wrong with doing without the module?
Doing it without the module was not wrong as such. After all, it did work perfectly fine.
However, when we start to implement more complex types of layers and activation functions in our library, hard coding the derivative calculations may begin to become difficult to get your head around.
An autodiff module provides that layer of abstraction for us, calculating the derivates for us, so we don't have to.
nn.py
Let's create a file called "nn.py".
This file will contain all the components that make up a neural network such as layers, activations etc...
Linear Layer
import autodiff as adimport numpy as npimport loss import optimnp.random.seed(345)class Layer: def __init__(self): passclass Linear(Layer): def __init__(self, units): self.units = units self.w = None self.b = None def __call__(self, x): if self.w is None: self.w = ad.Tensor(np.random.uniform(size=(x.shape[-1], self.units), low=-1/np.sqrt(x.shape[-1]), high=1/np.sqrt(x.shape[-1]))) self.b = ad.Tensor(np.zeros((1, self.units))) return x @ self.w + self.bQuite simple so far. __call__ simply carries out the forward pass when an instance of this class is called as a function. It also initialises the layer's parameters if it's being called for the first time.
The weights and biases are now instances of the Tensor class, which means they will become part of the computation graph when operations begin. This means that our autodiff module will be able to calculate their derivatives.
Note how there is no backward method like we had previously. We don't need it anymore since the autodiff module will calculate the derivates for us!
Activations
class Sigmoid: def __call__(self, x): return 1 / (1 + np.e ** (-1 * x))class Softmax: def __call__(self, x): e_x = np.e ** (x - np.max(x.value)) s_x = (e_x) / ad.reduce_sum(e_x, axis=1, keepdims=True) return s_xclass Tanh: def __call__(self, x): return (2 / (1 + np.e ** (-2 * x))) - 1These stay the pretty much same as before, just without the backward method of course!
Model class
class Model: def __init__(self, layers): self.layers = layers def __call__(self, x): output = x for layer in self.layers: output = layer(output) return output def train(self, x, y, epochs=10, loss_fn = loss.MSE, optimizer=optim.SGD(lr=0.1), batch_size=32): for epoch in range(epochs): _loss = 0 print (f"EPOCH", epoch + 1) for batch in tqdm(range(0, len(x), batch_size)): output = self(x[batch:batch+batch_size]) l = loss_fn(output, y[batch:batch+batch_size]) optimizer(self, l) _loss += l print ("LOSS", _loss.value)The model class stays similar to how it was before but now can train on the dataset in batches.
Training in batches, rather than using the whole dataset at once, enables the model to better understand the data it's given.
loss.py
loss.py will contain the different loss functions we implement in the library.
import autodiff as addef MSE(pred, real): loss = ad.reduce_mean((pred - real)**2) return lossdef CategoricalCrossentropy(pred, real): loss = -1 * ad.reduce_mean(real * ad.log(pred)) return lossAgain, same as before, just without the backward methods.
New Autodiff functions
Before we got onto optimisers, you may have noticed so far that the code uses some new functions from the autodiff module!
Here are the new functions
def reduce_sum(tensor, axis = None, keepdims=False): var = Tensor(np.sum(tensor.value, axis = axis, keepdims=keepdims)) var.dependencies.append(tensor) var.grads.append(np.ones(tensor.value.shape)) return vardef reduce_mean(tensor, axis = None, keepdims=False): return reduce_sum(tensor, axis, keepdims) / tensor.value.sizedef log(tensor): var = Tensor(np.log(tensor.value)) var.dependencies.append(tensor) var.grads.append(1 / tensor.value) return varoptim.py
optim.py will contain the different optimisers we implement in this library.
SGD
from nn import Layerclass SGD: def __init__(self, lr): self.lr = lr def delta(self, param): return param.gradient * self.lr def __call__(self, model, loss): loss.get_gradients() for layer in model.layers: if isinstance(layer, Layer): layer.update(self)Momentum
class Momentum: def __init__(self, lr = 0.01, beta=0.9): self.lr = lr self.beta = beta self.averages = {} def momentum_average(self, prev, grad): return (self.beta * prev) + (self.lr * grad) def delta(self, param): param_id = param.id if param_id not in self.averages: self.averages[param_id] = 0 self.averages[param_id] = self.momentum_average(self.averages[param_id], param.gradient) return self.averages[param_id] def __call__(self, model, loss): loss.get_gradients() for layer in model.layers: if isinstance(layer, Layer): layer.update(self)RMSProp
class RMSProp: def __init__(self, lr = 0.01, beta=0.9, epsilon=10**-10): self.lr = lr self.beta = beta self.epsilon = epsilon self.averages = {} def rms_average(self, prev, grad): return self.beta * prev + (1 - self.beta) * (grad ** 2) def delta(self, param): param_id = param.id if param_id not in self.averages: self.averages[param_id] = 0 self.averages[param_id] = self.rms_average(self.averages[param_id], param.gradient) return (self.lr / (self.averages[param_id] + self.epsilon) ** 0.5) * param.gradient def __call__(self, model, loss): loss.get_gradients() for layer in model.layers: if isinstance(layer, Layer): layer.update(self)Adam
class Adam: def __init__(self, lr = 0.01, beta1=0.9, beta2=0.999, epsilon=10**-8): self.lr = lr self.beta1 = beta1 self.beta2 = beta2 self.epsilon = epsilon self.averages = {} self.averages2 = {} def rms_average(self, prev, grad): return (self.beta2 * prev) + (1 - self.beta2) * (grad ** 2) def momentum_average(self, prev, grad): return (self.beta1 * prev) + ((1 - self.beta1) * grad) def delta(self, param): param_id = param.id if param_id not in self.averages: self.averages[param_id] = 0 self.averages2[param_id] = 0 self.averages[param_id] = self.momentum_average(self.averages[param_id], param.gradient) self.averages2[param_id] = self.rms_average(self.averages2[param_id], param.gradient) adjust1 = self.averages[param_id] / (1 - self.beta1) adjust2 = self.averages2[param_id] / (1 - self.beta2) return self.lr * (adjust1 / (adjust2 ** 0.5 + self.epsilon)) def __call__(self, model, loss): loss.get_gradients() for layer in model.layers: if isinstance(layer, Layer): layer.update(self)The code here has changed quite a bit from what it was from before.
Let's have a closer look at what's going on.
__call__
def __call__(self, model, loss): loss.get_gradients() for layer in model.layers: if isinstance(layer, Layer): layer.update(self)When an instance of an optimiser class is called, it takes in the model it's training and the loss value.
loss.get_gradients()Here we utilise our autodiff module!
If you can remember, the get_gradients method is part of the Tensor class and computes the derivates of all variables involved in the calculation of this tensor.
This means all the weights and biases in the network now have their derivatives computed, which are all stored in their gradient property.
for layer in model.layers: if isinstance(layer, Layer): layer.update(self)Now that the derivates have been computed, the optimiser will iterate through each layer of the network and update their parameters by calling the layer's update method, passing itself as a parameter to it.
The update method in our Linear layer class is as such...
#nn.pyclass Linear(Layer): ... def update(self, optim): self.w.value -= optim.delta(self.w) self.b.value -= optim.delta(self.b) self.w.grads = [] self.w.dependencies = [] self.b.grads = [] self.b.dependencies = []This method takes an instance of an optimiser and updates the layer's parameters by a delta value calculated by the optimiser.
self.w.value -= optim.delta(self.w)self.b.value -= optim.delta(self.b)delta is a method in the optimiser's class. It takes in a tensor and uses its derivative to return the value of how much this tensor should adjust by.
The delta method varies depending on the optimiser that is being used.
Let's have a look at one of the delta methods.
class RMSProp: ... def rms_average(self, prev, grad): return self.beta * prev + (1 - self.beta) * (grad ** 2) def delta(self, param): param_id = param.id if param_id not in self.averages: self.averages[param_id] = 0 self.averages[param_id] = self.rms_average(self.averages[param_id], param.gradient) return (self.lr / (self.averages[param_id] + self.epsilon) ** 0.5) * param.gradient ...param_id = param.idif param_id not in self.averages: self.averages[param_id] = 0Remember that most optimisers keep track of a type of average of each parameter's gradients to help locate the global minimum.
This is why we assigned an id to each tensor, so that their gradient averages could be kept track of by an optimiser.
self.averages[param_id] = self.rms_average(self.averages[param_id], param.gradient) return (self.lr / (self.averages[param_id] + self.epsilon) ** 0.5) * param.gradientIf necessary, the parameter's gradient average is recalculated (remember SGD does not maintain an average).
The method then computes how much the parameter should be adjusted by and returns this value.
Have a look at the other optimisers and to help you figure out how it all works.
MNIST Digit Classifier
To see if all our new changes work as expected, let's build a neural network to classify images of handwritten digits.
Import modules
from sklearn.datasets import load_digitsimport numpy as npimport nnimport optimimport lossfrom autodiff import *from matplotlib import pyplot as pltPrepare dataset
def one_hot(n, max): arr = [0] * max arr[n] = 1 return arrmnist = load_digits()images = np.array([image.flatten() for image in mnist.images])targets = np.array([one_hot(n, 10) for n in mnist.target])The mnist dataset contains images as 2D arrays. However, our library does not have layers that accept 2D inputs yet, so we have to flatten them.
one_hot takes in a number and returns the one hotted array for it of length max
one_hot(3, 10) => [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]Building the model
model = nn.Model([ nn.Linear(64), nn.Tanh(), nn.Linear(32), nn.Sigmoid(), nn.Linear(10), nn.Softmax()])This is a simple feed-forward network, which uses the softmax function to output a probability distribution.
This distribution specifies the probability of each class (each digit in this case) being true given its input (the image).
Training the model
model.train(images[:1000], targets[:1000], epochs=50, loss_fn=loss.CategoricalCrossentropy, optimizer=optim.RMSProp(0.001), batch_size=128)All we need to train our model is this one line.
I've decided to use the first 1000 images to train the model (there are around 1700) in the dataset.
Feel free to see how the model reacts when you change the training configuration. Maybe try changing the optimiser, loss function or the learning rate and see how that affects training.
Testing the model
images = images[1000:]np.random.shuffle(images)for image in images: plt.imshow(image.reshape((8, 8)), cmap='gray') plt.show() pred = np.argmax(model(np.array([image])).value, axis=1) print (pred)Here we shuffle the images that the model didn't train on into a random order.
We then go through each image, display it and get our model to predict what digit the image shows.
Let's run it!
Here is the output just after the model trains
****EPOCH 1100%|| 16/16 [00:00<00:00, 153.60it/s]LOSS 3.4742936714113055**EPOCH 2100%|| 16/16 [00:00<00:00, 166.29it/s]LOSS 3.046120806655171...EPOCH 49100%|| 16/16 [00:00<00:00, 143.15it/s]LOSS 0.003474840987802178**EPOCH 50 100%|| 16/16 [00:00<00:00, 139.63it/s]LOSS 0.0031392859241948746Here you can see the model finishes with a loss of 0.0031392859241948746. Not bad at all.
Note how each epoch doesn't even take a second to complete! It seems our autodiff module is able to compute several derivatives at an acceptable speed.
Now let's see if the model can really classify digits...
These were the first 4 random digits when I ran the code...
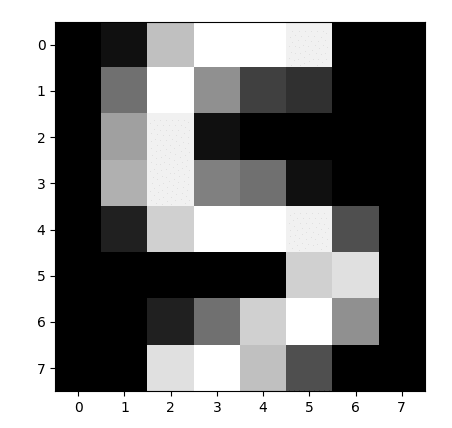



These look like a 5, 6, 5 and a 7 to me....
(maybe the last one is a 3. I can't tell haha)
Let's see what the model predicted
![]()
Looks good to me!
Just to make sure, let's make it go through all the images and calculate it's accuracy.
correct = 0cnt = 0for image in images: pred = np.argmax(model(np.array([image])).value, axis=1) real = np.argmax(targets[cnt]) if pred[0] == real: correct += 1 cnt += 1print ("accuracy: ", correct / cnt)Running this results in the following output...
accuracy: 0.9604897050639956Wow! It is safe to say that our model has successfully trained for this specific task.
Thank you for reading
Thank you for reading through this post. The next few posts will involve implementing more layer types such as recurrent layers and convolutional layers, so I hope you stay tuned for that!
Original Link: https://dev.to/ashwinscode/deep-learning-library-from-scratch-6-integrating-new-autodiff-module-and-mnist-digit-classifier-co9
Dev To
More About this Source Visit Dev To