
An Interest In:
Web News this Week
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
Some of Our Sources
- Slashdot
- BoingBoing
- Techcrunch
- Just Creative
- Pearsonified
- Abduzeedo
- Vandelay Design
- Creative Curio
- Stylized Web
- Hashedout
Help Webnuz
Referal links:
How to build your own LinkedIn Profile Scraper in 2022
Introduction
LinkedIn is the largest professional network over the internet accessible through mobile or web to look for jobs, internship and enlarge your network. On LinkedIn, you can find people with similar skills, interests, and experience. To access the platform, you need to sign up and create a profile.
On Linkedin you can search for jobs, internships, and people with similar skills, interests, and experience. What do you say of automating this search process ? This let us to web scraping.
Web scraping is mostly used on sites with big data like Google, Amazon or Twitter. As a whole web scraping is refers to the extraction of data from a website. This information is collected and then exported into a format that is more useful for the user mostly csv file though some other formats are also possible like json.
What follows is tutorial on how to build a scraper in python that can be used to extract data from LinkedIn.
Procedure
Though the scraping is mostly an wutomation process, it is a broad process that can be broken down into several steps.
Environment setup
Python is the chosen language for this tutorial and as you can guess some precautions should be done to make sure that the environment is setup correctly and the main OS I'll use is Ubuntu(a Linux distro) virtual environment is a tool that helps you to isolate your code from the rest of the system. It is a good idea to create a virtual environment for your project.
- Make a new directory on your desktop and cd into it.
# create the directory mkdir linkedin_scraper # cd into the directory cd linkedin_scraper- To create a virtual environment, run the following command:
python -m venv venv # or python3 -m venv venv- To activate the virtual environment, run the following command:
# For linux and mac userssource venv/bin/activate# For windows users.\venv\Scripts\activate- Install the following packages:
pip install ipython selenium parsel pip-chillCheck the installed packages using the following command:
# To list only the main packages installed in the virtual environment, run the following command:pip-chill- For this automation process we will use
ipythonwhich is a python shell. It is a good idea to use it to run the automation process. On your terminal type the following command:
ipythonThe output is
Note: Alternatively a jupyter notebook or a python file can be use for this process.
ipythonwas chosen since it is a good shell and it is easy to use with no much prior requirements and interactive results.
Our environment is setup and we're ready to go.
Scraping Samples
To access linkedin data we need to login and thus automating this feature too. To automate the login process we will use the selenium package together with the chrome drivers. Follow these commands on your IDE.
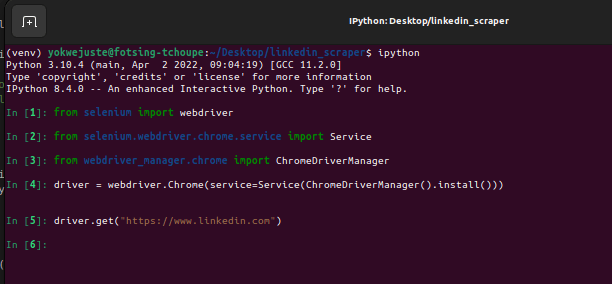
This will give as result a chorme window having the login page of LinkedIn and most of all it should be having the banner having the message below.
Chrome is being contrrolled by an automated software.
As shown below:
- Next, we need to login to LinkedI using automation, for this we'll tell our bot it need to provide the login informations. For this we'll use the chrome dev tool and get the login fields ids. To access this tool we use the keyboard shortcut
Ctrl+Shift+ior we userf12to open the dev tool.

The image below shows the dev tool and illustrates the login fields with their identifiers, follow same on your prompter browser window.
Now click on the circled Inspect Elements icon, you can hover over any element on the webpage the code will appear highlighted as seen above. You want to look for the class and id attributes.
from selenium.webdriver.common.by import By# Setting the variables for the login fieldsusername = driver.find_element(By.CLASS_NAME, 'input__input')username.send_keys('Your Linkedin Email')password = driver.find_element(By.ID, 'session_password')password.send_keys('Your Linkedin Password') # Clicking on the login buttonlog_in_button = driver.find_element(By.CLASS_NAME, 'sign-in-form__submit-button')log_in_button.click()Fronm here, you'll be directed to your LinkedIn profile. Guess what, you successfully automated your login process.
Next we want to make a search query on google that will target all the LinkedIn profiles matching the item "Web" AND "Javascript" on their profile.
Let go to google still using our terminal so that our automated chrome browser will be in use.
# To open the google search pagedriver.get('https://www.google.com')Let's make our query and click on the search button (this is done in the terminal).
search_query = driver.find_element(By.NAME,'q')search_query.send_keys('site:linkedin.com/in/ AND "Web" AND "Javascript"')from selenium.webdriver.common.keys import Keysearch_query.send_keys(Keys.ENTER)The search can be customized, feel free to modify at your needs.
Now we have these results. 
As seen above we still use the same method to get the class we have been using before.
linkedin_users_urls = driver.find_elements(By.CLASS_NAME, 'iUh30')Note: The class name is
iUh30and it is the class name of the link that contains the LinkedIn profile url.
Note: The method name we use now isfind_elementsand it is the method that is used to get all the elements of a certain class. Not thefind_elementmethod that get an element.
let's verify that we have some results. We will use the len function to get the length of the list.
len(linkedin_users_urls)I guess you noticed that the return is not what you wanted. We want to get the urls of the linkedin profiles. To get the urls we need to use the get_attribute method and some extra spices. Let's use a new variable to store the urls.
linkedin_users_urls_list = driver.find_elements(By.XPATH, '//div[@class="yuRUbf"]/a[@href]')# To check the list content we run the following command[users.text for users in linkedin_users_urls_list]The output will be as follows:

hohohoho, we got the urls of the linkedin profiles which means we can now start scraping the data(name, title, company, location, the profile url and more).
The following steps we'll enter a more complex task but we'll use the same methods and variables we used before.
The Web Scraping Process
we need now some files to create our scraper. In your project directory, create the files as follows.
touch variables.py main.py# Creates two files with the names above
variables.pymy_username = 'your email address'my_password = 'your passwowrd'file_name = 'results.csv' # file where the results will be savedquery = 'site:linkedin.com/in/ AND "Web" AND "Javascript"'Variables files contains the variables that we'll use to login to LinkedIn together with the query.
We'll use the main.py file to run the main code.
main.pyimport variablesfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.action_chains import ActionChainsfrom selenium.webdriver.common.keys import Keysdriver.get(variables.query) # google searchusername.send_keys(variables.username) # username fieldpassword.send_keys(linkedin_password) # password fieldlinkedin_users_urls_list = driver.find_elements(By.XPATH, '//div[@class="yuRUbf"]/a[@href]')[users.text for users in linkedin_users_urls_list]
This process is fast at times and to slow it down, use the sleep function from the time function and it can used at anytime in the code.
pythonfrom time import sleepsleep(2)The process is summarized as seen below:
- Login to linkedin
- Making the google search query and submit
- Getting the different displayed profiles in a list
profile_urls - Iterate over the list with the new url as index
- Get the profile url and open the profile page
- Get the name, title, company, location and more from the profile page
- Save the results to a csv file
We're done.
Full Code
The full source code available on GitHub, feel free to give me a star, create issues, make pull requests and lets promote the opensource communnity.
Conclusion
As you can see, we've made a scraper that can scrape the data from LinkedIn. We've used the following technologies:
Note: From time to time, Linkedin change their class and attreibutes, so for future releases, I'll try to update the scraper to work with the new Linkedin changes. Or you can try to use the Linkedin API to get the data.
Original Link: https://dev.to/yokwejuste/how-to-build-your-own-linkedin-profile-scraper-in-2022-5822
Dev To
More About this Source Visit Dev To