
An Interest In:
Web News this Week
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
Some of Our Sources
- TutsPlus - Code
- The Logo Smith
- Vandelay Design
- Fudge Graphics
- Web Design Ledger
- Line 25
- 24 Ways
- Web Resource Source
- Android Dissected
- Codrops
Help Webnuz
Referal links:
Kafka on the Serverless Shore: Building event-driven applications with Kafka
As I awake one morning from uneasy dreams, I found myself asking why I never tried to use Apache Kafka.
As a event-driven enthusiast and with the recent announcements of Amazon Managed Streaming for Apache Kafka (MSK) Serverless and the Serverless Kafka offering of Upstash I gave another try.
I played a little on my computer in the past, but only see the work to go to production. I confess was beyond what I was up to do in my free time. So the serverless come to rescue! This is one of best-selling point of not having to think about servers, you can just experiment with new technologies.
Since the AWS offering is in public preview and not General Available, I went with Upstash's Kafka Serverless offering.
What is Kafka?
I thought that since Kafka was a system optimized for writing, using a writers name would make sense. I had taken a lot of lit classes in college and liked Franz Kafka. Plus, the name sounded cool for an open source project.
So basically there is not much of a relationship.
Jay Kreps, Apache Kafkas co-creator on Quora
Kafka is a publish/subscribe messaging system. Other ways to describe it are distributed commit log or nowadays, as a distributing streaming platform.
The core entity for Kafka is a message. For all purposes, Kafka doesn't care about the content of the message. It's just an array of bytes. Messages also can optionally have a key. Kafka persistently stores the messages in the order. Is possible replay the stream to get to the state of a system at a point in time. A time machine for your transactions.
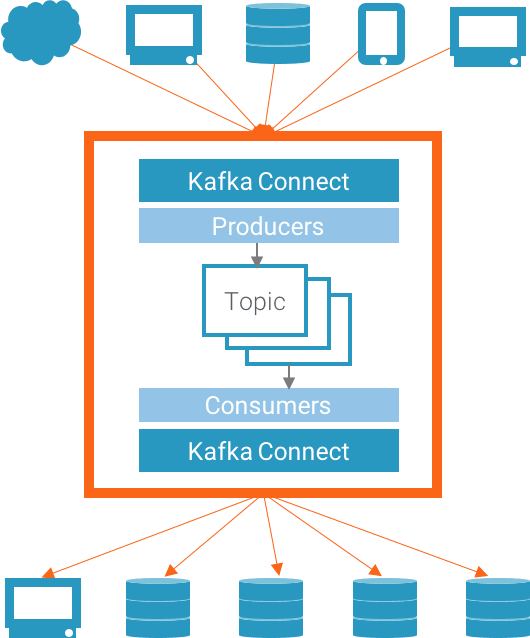
Topics are a way to categorize the messages in order to allow other applications to have some visibility of what messages they will access.
And then, the heart of the system: Producers and Consumers. Basically, the first, also called publishers or writers, produces messages, usually a lot of messages, to require Kafka, and other applications act upon those messages. Consumers read messages from a topic and. We can call them subscribers or readers too.
Kafka is a lengthy subject, worth of books, courses and hand-on practice. There are a lot more concepts that I will not cover in this post. Well is even subject for papers, like On Efficiently Partitioning a Topic in Apache Kafka. I highly recommend Apache Kafka for beginners - What is Apache Kafka?.
The benefits of a serverless offering is the overhead in management of brokers, partitions, the Zookepeer and all the other moving parts to allow a fault-tolerant and highly distributed applications is taken care for you. And then, you can focus on write the code you need in your domain, with your tools this is what I call the joy of serverless.
On the shore
To start, you just need to login, select Kafka and will create our first cluster. Kafka works in a distributed way from the get go.

To create the cluster, we'll need a name and select the region. And also, if we need to be in only one availability zone or span of over one. Choose a single-zone for testing/development, multi-zone for production use cases.

We will the create our first topic and choose our desired number of partitions. Partitions are how Kafka provides redundancy and scalability, and each one can live on a different server. This is a very important concern for performance and scaling.
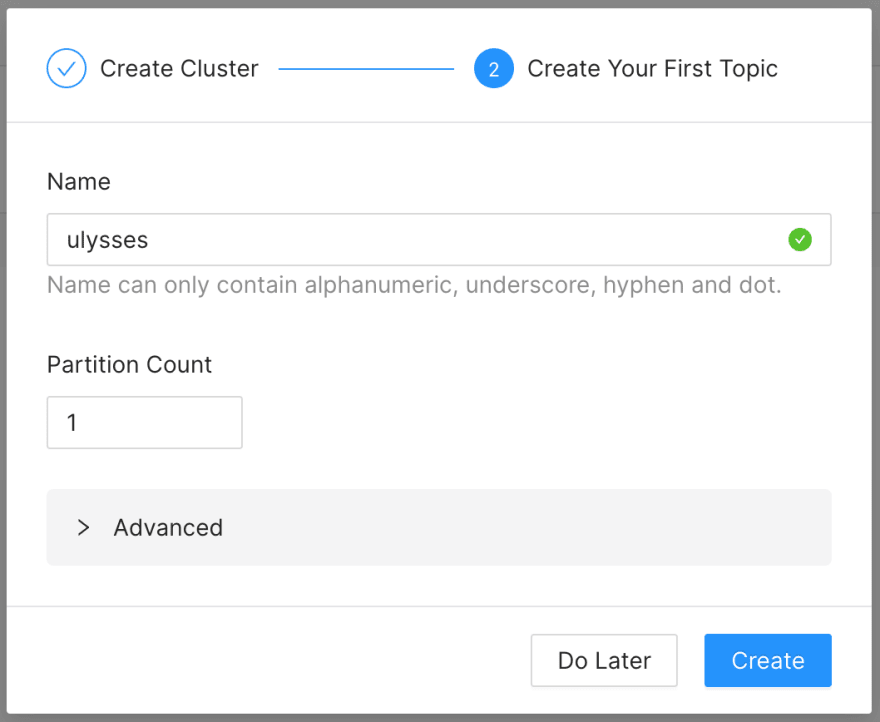
In the advanced options for topics, there will be several options with sensitive defaults. Some configurations will require an upgrade in your plan. So, plan for the go-live depending on your application needs.

And that's it. No need to worry about servers.

For this tutorial I will use Node.js on an AWS Lambda. Code is available in this GitHub repository using TypeScript:
 ibrahimcesar / lambda-serverless-kafka
ibrahimcesar / lambda-serverless-kafka
Kafka on the Serverless Shore
Kafka on the Serverless Shore
Experimenting the Upstash's Kafka Serverless.
Read Kafka on the Serverless Shore: Building event-driven applications with Kafka for context.
Deploying
You will need:
- An AWS account
- CDK v2 installed (
npm install -g aws-cdk) - CDK boostraped in the Account / Region we'll deploy
- A user for the CDK deploy with the right permissions
If you need help with all the above, open an Issue to see if there's enough people interested in a tutorial for that.
npm installcp .env.example .envFill .env with your credentials and names.
cdk deployRemember if you have multiple AWS profiles in your machine to pass the flag:
cdk deploy --profile namedProfileBootstraped with my CDK v2 Simple Lambda HTTP ApiGateway Starter
I'll use the vendor package (@upstash/kafka) that leverages the REST API. Since we are at the shore, we'll not go open sea and build a ship. Not even a boat. We'll just get our feets wet.
I'm writing an application that will read something, from some author. And post every line to Kafka. Then, I'll consume after that.
Basically is just two lambdas, one for each endpoint: a writer and a reader.
And we'll use my topic ulysses. I could send all lines with page numbers from the book Ulysses from James Joyce. Or analytics data. Or log data. You get the gist.
// This is just a edited. // View full file at: // https://github.com/ibrahimcesar/lambda-serverless-kafka/blob/main/src/lambda/producer.tsimport { Kafka } from "@upstash/kafka";const kafka = new Kafka({ // configuration});const writer = kafka.producer();try { const res = await writer.produce("ulysses", writing, { key: payload.author ?? "", }); response = res; } catch (err) { if (err instanceof Error) throw err; else throw new Error(`${err}`); }And to consume is simple. Note that I have there two hardcoded values, consumerGroupId and instanceId. You, at the time, basically can send whatever you want in the first request and Upstash will provision for you.
// Try and catch block. // View full file at: // https://github.com/ibrahimcesar/lambda-serverless-kafka/blob/main/src/lambda/consumer.ts try { const writing = await reader.consume({ consumerGroupId: "group_1", instanceId: "instance_1", topics: payload.topics, autoOffsetReset: payload.autoOffsetReset ?? "earliest", }); response = writing; } catch (err) { console.error(err); if (err instanceof Error) throw err; else throw new Error(`${err}`); }Little TypeScript goodie. I'm using the flag
useUnknownInCatchVariables: truein thetsconfig.jsonfile, so the catch is of typeunknown. Hat tip for Mike North to show the way.
And now we can start writing and reading. To write is just a POST.

Eventual consistency
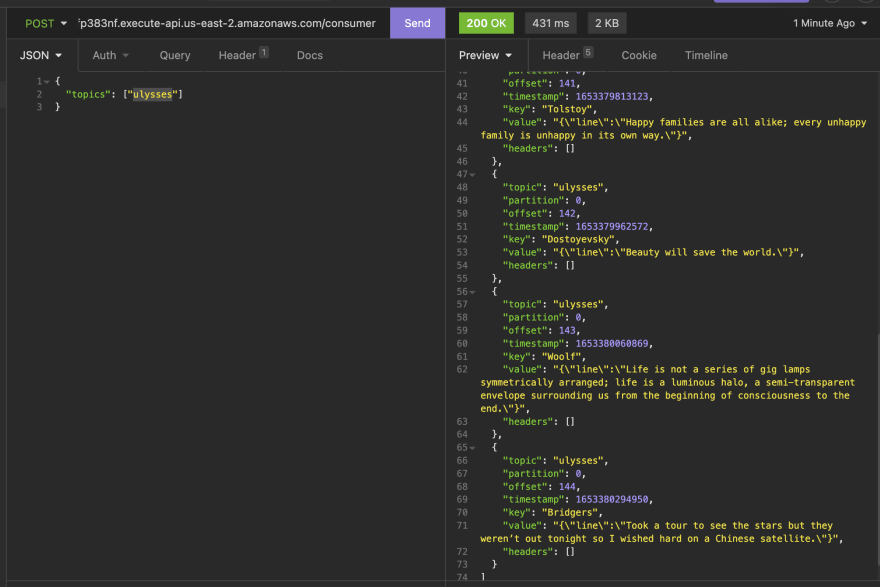
To read, we'll use another POST, but beware: Here comes something important about distributed systems. We have eventual consistency. Which means, your application cannot rely on the data being immediatly available for you just after the write. If you do, you could get... nothing, like a empty array in this case:

But, after very little time, you can see all data available in the topic:
Dive Deep
- Checkout Upstash's Docs on Kafka
- Be yourself a reader: Kafka: The Definitive Guide: Real-Time Data and Stream Processing at Scale
- Checkout the Confluent's content on Kafka
- AWS just released MKS Serveless, the Managed Streaming for Apache Kafka (MSK). But please note that, while is a serverless offering in the sense you'll not need to worry about cluster servers as they put: "Easily stream data with Amazon MSK without managing cluster capacity". Emphasis mine. You'll need to put a lot more effort than the Upstash's offering as you can see here: Getting Started - Step 2: Create a Client Machine
- All the code used is open to use in TypeScript, using AWS Cloud Developement Kit (CDK). So you'll have no problem at all in provisioning your infrastructure.
Original Link: https://dev.to/aws-builders/kafka-on-the-serverless-shore-building-event-driven-applications-with-kafka-23df
Dev To
More About this Source Visit Dev To