
An Interest In:
Web News this Week
- April 2, 2024
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
Some of Our Sources
- Techcrunch
- Web Designer Wall
- Joshua Blankenship
- The Logo Smith
- Smashing Apps
- Naldz Graphics
- CSS Globe
- 24 Ways
- Codrops
- Dev To
Help Webnuz
Referal links:
Manipulating the DOM using Javascript - how to select nodes (part 1)
In the beginning, websites were entirely made out of HTML and they could only display text (back in the early 90s, computer monitors only supported 16 colours). The browser was downloading the HTML document, render it and in the end the content was displayed on the user's screen. There was no way to change that text, so in a way we could say it was set in stone.
But people wanted more than displaying boring text so they started creating interactive sites. Internet Explorer was released and Javascript was created in 1995. This new exciting scripting language started to be used for webpages but the interactivity provided was very limited since UIs were generated using HTML and HTML couldn't be changed after the files were downloaded (that very limited interactivity eventually became known as DOM Level 0 or Legacy DOM).
From the need to be able to change the UI after the page was loaded (add, remove, edit or move elements around in the HTML document), the first standardized version of the DOM was born in 1998 and it was called DOM Level 1. Changing (manipulating) the DOM suddenly opened the door for infinite possibilities. We can now create applications that are customizable by the user, that react on user's input or even update the data we see on the screen without refreshing the page (so no extra trips to the server are needed). We can drag or move elements across the screen, delete some of them or add new ones if that's what we want.
Some concrete examples of DOM manipulation are:
- change the content/ color of a button after we clicked on it
- change the content of a paragraph when hovering over it
- remove an item from a "To Do" list after we checked it as completed
- adding a new item to a "To Do" list after we typed it in an input and clicked an "Add" button
- navigating to a different page after submitting a form
THE DOM (DOCUMENT OBJECT MODEL)
The Document Object Model is a cross-platform and language-independent interface that treats an XML or HTML document as a tree structure wherein each node is an object representing a part of the document. The DOM represents a document with a logical tree.
In simple terms this means that after the browser downloads the HTML document, it converts its content into a tree like structure called the DOM (Document Object Model) and stores it in its memory.
IMPORTANT
The DOM is not a programming language and it's not a part of Javascript. It is one of the multiple web APIs built into web browsers and it has been created to be independent of any language (think of web APIs like they're collections of functions). Implementations of the DOM can be built using other scripting languages besides Javascript and every non-empty webpage has a DOM, even the ones that don't use any Javascript. You don't have to modify the DOM if your pages display only text for example, but if you want interactivity, you will probably need to work with the DOM (some of the same interactivity Javascript offers can be achieved using CSS, but this is another topic).
Things might sound a bit abstract so before going any further, let's see how this DOM actually looks like. We have a very simple HTML code snippet:
<!DOCTYPE html><html> <head> <meta charset="utf-8"> <title>Simple DOM example</title> </head><body> <section> <h1>This is a header!</h1> <h4>This is a smaller header!</h4> <p>This is a paragraph!</p> <img src="mountains.jpg" alt="Mountains covered in snow"> </section> <section> <h2>This is another header!</h2> <h4>This is another small header!</h4> <p>This is a paragraph!</p> <p>This is another paragraph!</p> </section><script src="index.js"></script></body></html>Below we can see how the DOM for the above HTML code looks like (if you want to play around with this visual representation, you can use this Live DOM viewer).
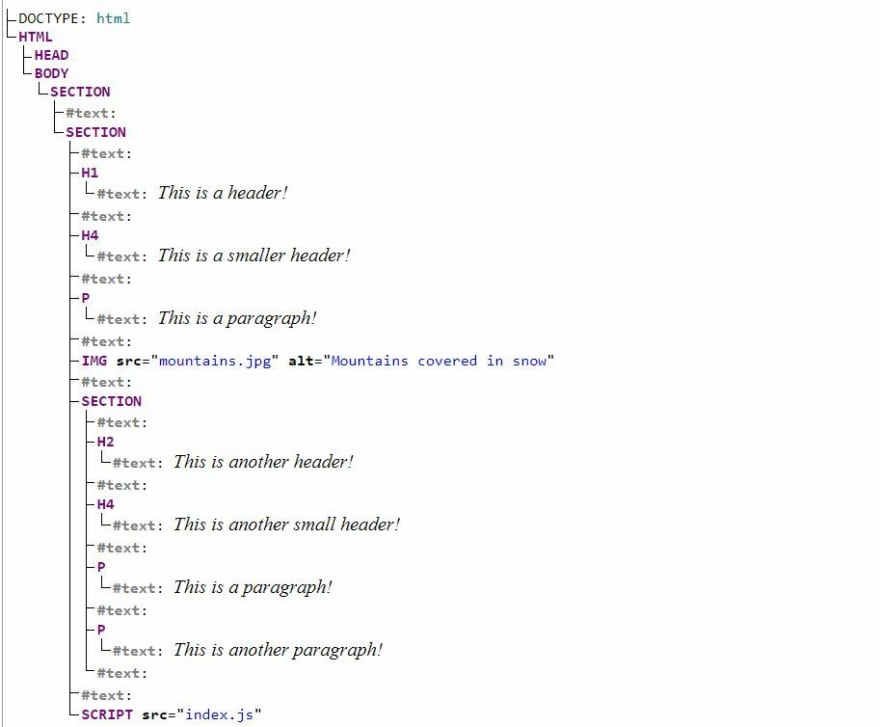
So this is the tree-like structure the HTML gets translated to. The tree is made out of nodes. Some nodes represent HTML elements (HTML, HEAD, BODY, SECTION etc) and other represent text (the ones represented as #text). A complete list of all node types can be found here.
Based on its position in the tree, a node can be a:
Root node
This is the top node of the tree, which in the case of HTML is the HTML node.
Parent node
A node which has other node(s) inside it. For example, BODY is the parent node of all nodes inside it.
Child node
A node directly inside another node. In our example, the H1 node is the child of the SECTION node.
Sibling nodes
These are nodes that are found on the same level in the DOM. H1, H4, P and IMG nodes are all siblings since they are on the same level inside the SECTION node.
Descendant node
This is a node that can be found anywhere inside another node. H4 is for example the descendant node of the BODY.
MANIPULATING THE DOM
What does manipulating the DOM means? It means we can change the nodes in the tree we've just seen, making use of APIs that can control the HTML and the styling of a page. Each node has its own properties and methods that can be manipulated using Javascript.
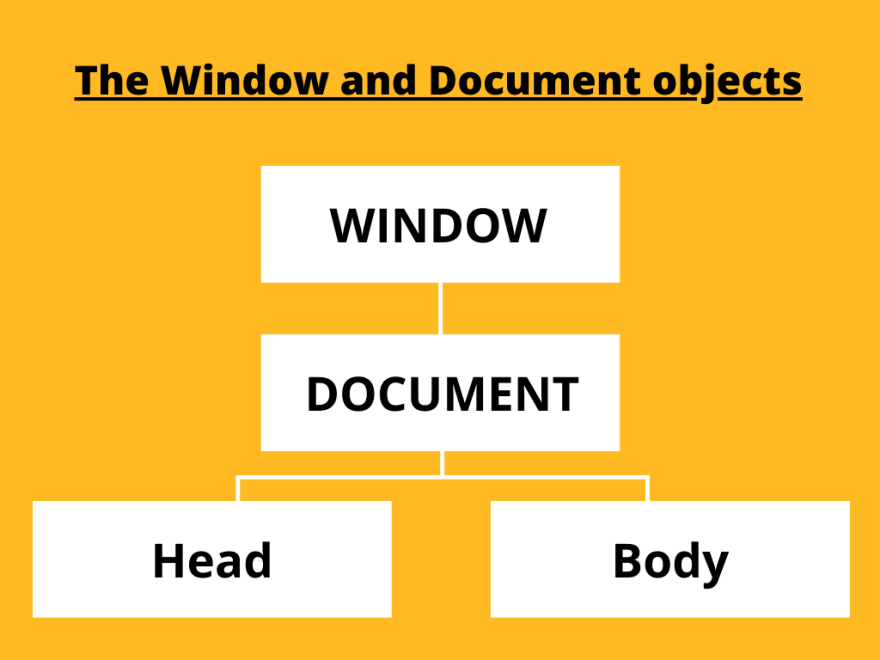
All of the properties, methods and events available for manipulating and creating web pages are organized into objects that we're going to call interfaces. There are many DOM interfaces working together but the ones that we're going to use most often are Window and Document. A complete list of the DOM interfaces can be found here.
- Window - The Window interface represents a window containing a DOM document (an open window in a browser). It holds the highest position in the DOM hierarchy, as it is a parent of the document object and all its children .
- Document - The Document interface represents any web page loaded in the browser and serves as an entry point into the web page's content, which is the DOM tree.
1.TARGETING NODES
In order to interact with any node in the tree, we first need to target (select) it. We can do this using one of the multiple methods the DOM API offers (notice that all these methods are called on the document object using the dot notation):
- getElementById(). We select and HTML element making use of its
id attribute. Element object describing the DOM element object matching the specified ID, or null if no matching element was found in the document.
<div id="idSelector">I will be selected based on id.</div>const elementById = document.getElementById("idSelector");console.log(elementById ); // will return <div id="idSelector"></div>- getElementsByClassName(). We select and HTML element based on its
class attribute. This method returns alive HTMLCollection(an array-like list) of HTML elements, possibly of length 0 if no matching elements are found.
<p class="classSelector">I am a paragraph.</p><p class="classSelector">I am too a paragraph.</p><p class="classSelector">I am, you guessed it, a paragraph.</p>const elementByClassName = document.getElementsByClassName("classSelector");console.log(elementByClassName); // will return HTMLCollection {0: HTMLParagraphElement {...}, // 1: HTMLParagraphElement {...}, // 2: HTMLParagraphElement {...}}// 0:<p class="classSelector"></p>// 1:<p class="classSelector"></p>// 2:<p class="classSelector"></p>- getElementsByTagName(). We target HTML elements based on their tag names. This method returns live HTMLCollection of all matching HTML elements, possibly of length 0 if no matching is found.
<p>This is fun!</p><p>I like writing this article!</p><h4>The DOM is so interesting!</h4>const elementByTagName = document.getElementsByTagName("p");console.log(elementByTagName); // will return HTMLCollection {0: HTMLParagraphElement {...}, // 1: HTMLParagraphElement {...}}// 0:<p ></p>// 1:<p ></p>- getElementsByName(). This method returns a live NodeList Collection of elements with a given name attribute in the document. If no match is found, the collection will be empty.
<input type="text" name="someInput" />const elementsByName = document.getElementsByName("someInput");console.log(elementsByName); // will return NodeList {0: HTMLInputElement {...}}// 0:<input type="text" name="someInput"></input>- querySelector(). Method that returns the first Element within the document that matches the specified selector, or group of selectors. If no matches are found, null is returned. We can provide any selector we want as an argument (a class, an ID etc).
<div class="divClass">This is just a div!</div><div id="thisIsAnId">This is another div!</div><p name="numberOnePara">This is just a paragraph!</p>const querySelectionByClass = document.querySelector(".divClass"); console.log(querySelectionByClass); // will return <div class="divClass"></div>const querySelectionById = document.querySelector("#thisIsAnId");console.log(querySelectionById); // will return <div id="thisIsAnId"></div>const querySelectorByName = document.querySelector("[name='numberOnePara']");console.log(querySelectorByName); // will return <p name="numberOnePara"></p>- querySelectorAll(). This method returns a static (not live) NodeList representing a list of the document's elements that match the specified group of selectors. The NodeList will be empty if no matches are found.
<p>Paragraph number 1!</p><p>Paragraph number 2!</p><p>Paragraph number 3!</p><p>Paragraph number 4!</p><p>Paragraph number 5!</p>const queryAllParas = document.querySelectorAll("p");console.log(queryAllParas); // will return NodeList {0: HTMLParagraphElement {...}, // 1: HTMLParagraphElement {...}, // 2: HTMLParagraphElement {...}, // 3: HTMLParagraphElement {...},// 4: HTMLParagraphElement {...}}// 0:<p ></p>// 1:<p ></p>// 2:<p ></p>// 3:<p ></p>// 4:<p ></p>GLOSSARY
HTML Collection - in simple terms, an HTML Collection is an array-like object that holds HTML elements extracted from a document. An HTML Collection can contain only Element Nodes.
NodeList - It's a collection of nodes. It is similar to an HTML Collection but it can contain all type of nodes (Element, Text and Attribute) not only Element Nodes.
Live HTMLCollection - The collection updates when the DOM updates.
Static HTML Collection - If the DOM updates, the changes are not reflected in the collection.
Live NodeList - The collection updates when the DOM updates.
Static NodeList - If the DOM updates, the changes are not reflected in the collection.
Resource refrences:
Header image source: Jackson So/@jacksonsophat on Unsplash
Original Link: https://dev.to/arikaturika/manipulating-the-dom-using-javascript-how-to-select-nodes-part-1-38j
Dev To
More About this Source Visit Dev To