
Some of Our Sources
- Mashable
- Web Designer Wall
- Joshua Blankenship
- The Logo Smith
- Fuel Your Creativity
- Line 25
- Specky Boy
- Freelance Switch
- Web Resource Source
- Willems Lab
Help Webnuz
Referal links:
SAINE is Mathematically One of the Best WORDLE Starting Words - Here's Why
TLDR: I wrote a Wordle solver bot with Javascript and UIlicious. You can run this snippet any day to get your daily Wordle solution. Try and see if you can get a better score than the bot! Feel free to edit it and optimise the solver algorithm!
The wordler solver is covered in 3 parts, which covers the
- UI interaction code
- Wordle Statistical model, and the math behind it (this article)
- Unit testing and benchmarking of the wordle solver (@ TODO)
All the statistical examples can be found at the following link: https://uilicio.us/wordle-statistics-sample
And is generated via code used here: https://github.com/uilicious/wordle-solver-and-tester

Our WORDLE strategy
Disclaimer, I do not claim for this to be the best WORDLE strategy (yet), But it is a rather good one =)
Before going into the statistics, let's first cover our WORLDE strategy.
One thing that humans do really well that classic computers are bad at is to "intuitively" figure things out. Unless I plan to train a neural network, the computer program I am developing will need to use a classic dictionary word list to make its guesses.
The one thing that computers do well however, is memorising giant lists of words or data. And performing math on it. So let's use this to our advantage by doing the following sequence.
Given the 2 word list, one full of possible answers ( ~2.3k words), and another with the full word list (13k words)...
- Filter out words in the possible answer list against the current game state from past guesses.
- Count the number of times each character appears in the answer word list in their respective word positions.
- From the full word list, choose the word which is most likely to find a correct character guess. Independently score it preferring words that give more information in the first 4 rounds with either an exact or partial match.
- Choose the highest scoring word and try it.
- Repeat from the top if needed.
Also to clarify: We do not memorise the previous Wordle solutions (I felt that was cheating as the system could end up just memorising the day-to-day list in sequence).
While the exact details of the scoring change slightly depending on the round - to optimise things. It does not change the overall concept on a high level.
So how does this work in practice? For our current iteration of the Wordle strategy, we will view this in practice step by step (without code).

Our starting word: SAINE - and why you should use it
An alias to sain, meaning: to make the sign of the cross over (oneself) so as to bless or protect from evil or sin
There has been lots of advice on the starting 2 words. And it makes sense that this word follows with:
- 3 very common vowels
- All unique characters
But let's figure out why the solver chooses this word by looking at the numbers.

Based on the statistics. "SAINE" has the highest chance of finding an exact green character match as an opening word while having 3 of the top vowels.
Reading the raw distributing table can be understandably hard to digest. So let me recontextualize those numbers here. SAINE has a
- 91.06% chance of partial matching at least 1 character (yellow/green);
- 55.94% chance of partial matching at least 2 characters (yellow/green);
- 50.24% chance of exactly matching at least 1 character (green).
There is a really high chance of getting at least one or 2 major clues. Inversely, because there are few words without A, I, and E, failure to match is a "huge clue."
Not bad for an opening huh?
What about other popular opening words such as "CRANE" and "ADEPT"?

The only key advantage, for "CRANE / ADEPT" is they both have a 0.04% chance of successfully doing a 1-word guess. I suspect the flaw of the previous public analysis was how they were limiting the opening word to the known answer list. I believe however, we should be using the full word list instead, to maximize the probabilities of clues in favor of a very narrow chance of doing a 1-word guess.
More importantly, SAINE has a significantly higher chance (by ~7%) of guessing an exact match (green) on the first try. Which is incredibly helpful as a clue.
With the starting word debate out of the way, we will see how the system reacts with the different results!

Understanding how the 2nd guess PLUTO, leads to PAUSE
So let us look at how the 2nd word is chosen for the answer "PAUSE" (left-hand side).
We are given the following information:
- Letter I & N is not in the word.
- A is the 2nd character, E is the 5th character.
- S is either the 3rd or 4th character (it is not the 1st character).
- Only 12 possible answers are in the word list
Pretty standard Wordle stuff. But let's look at how does this impacts the stats on the remaining possible answers. And how PLUTO was chosen.

With only 12 words left, lets find the most efficient way to eliminate our options.
- Because we already have information on the letters S, E, A, our scoring system will avoid them with a penalty (marked in red).
- The next biggest probabilities of characters in positions we do not know about are P, U, and T, in positions 1, 3, and 4, respectively (marked in orange).
- Finally, because we have positions 2 and 5 solved, we can make use of this to get additional information. So let us try our best to use the characters L & C.
From the following constraints, the only valid word to try was PLUTO. Although we know the letter O is not in the final answer, there is no word for PLUTC. Also, while the word PLUTO was not in the answer list, it was in the full word list, making it a valid guess.
After the submission, the system now knows the following:
- L, T, O is not in the word (O is a confirmation of an assumption).
- P is the 1st character, U is the 3rd character.
- S is the 4th character (is it can no longer be the 3rd character).
This means I no longer need stats because there is only one truth: PAUSE.

But what is with the crazy guessing pattern? With MOHUR, BLYPE, and finally ULCER
The Mohur is a gold coin that was formerly minted by several governments, including British India and some of the princely states which existed alongside it.
The statistics here is being evaluated live and the changes are dependent on the result of each round. So the result differed where:
- Letter S, A, I, N is not in the word.
- Letter E may be in positions 1, 2, 3, 4 but not 5.
Filtering out the possible answer list leads to the following statistics:

This may not make sense at first because the word does not start with C or B. With 187 words left, this is where the details of the scoring start to matter.
- Once again, we ignore the letter E, which is the information we already know (in red).
- The letter R at the end has the highest weightage (of 62 words) by a large margin. Finding out the answer for this character either halves (no match) the possibility list, or one-thirds it (it matches).
- From here, the next step is finding the word with the most matches against other letters in the respective positions such as O at position 2 (score of 37), followed by any remaining characters. Matching either their positional list or unique letters list.
This may not be the most optimal choice given the known answer list. However, this is intentional because, we want to focus on the information again until we have a very high confidence in a word. And in this process, we would penalize duplicate letters to focus on reducing the number of options.(Arguably there is room for improvements here)
The results from the guess were interesting.
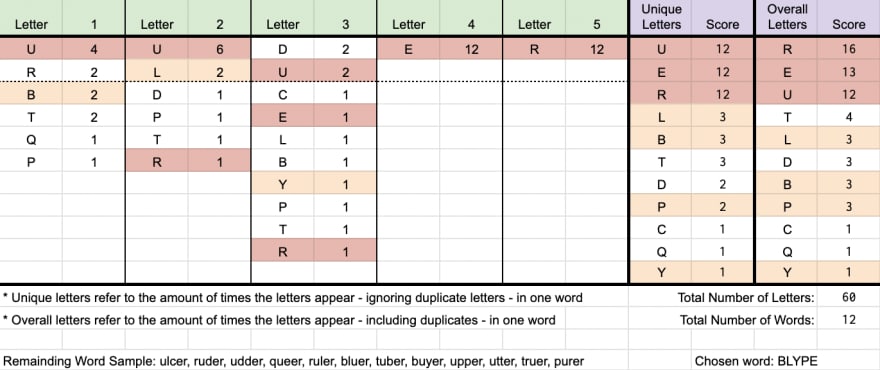
As weird and confusing as the word MOHUR was, the result reduced the possibility to 12 words. Once again, it tries to prioritises trying new characters and giving it the obscure word of BLYPE.
BLYPE: a piece or shred of skin
This word reduces the list of possibilities down to one word - ULCER, which is the final answer.
Side Note: If you notice, it is willing to try characters it knows that is not in the official answer list. This is intentional, and helps take into account Wordle clones because if the actual answer chosen is not within the original answer list, the system will automatically fall back to using the full word list instead. Making this more resilient against Wordle varients.

Code warning ahead: If you were only here for the math and stats then skip to the end. The remaining content in this article consists of JS code.
Show me the code
The full solving class can be found here.
This article will be focusing on the core functionality that is required to make this process work and not all parts of the code. If you have not read Part 1, .
The code here has been simplified to skip the "boilerplate" stuff.
The solver needs to do the following:
- Given the current game state, filter the possible word list.
- Given the filtered word list, calculate the statistics.
- Given the statistics, and game state, score the word following the strategy.
- Suggest a word.
Let us break it down, piece by piece.
Normalize The game state object (generated in part 1)
For every round, the game state would be generated with:
- .history [ ] : An array of past wordle guesses.
- .pos [ ]: An array of objects containing the following info.
- .hintSet : set of characters that are valid "hints".
- .foundChar: characters that are confirmed for the given position.
This is generated by using the information on the screen in part 1.
However, for our use case, we would need to normalize some of the common data set we would need. Through the _normalizeStateObj function, we get the following.
- badCharSet: Characters we know that is not in the word;
- goodCharSet: Characters we have confirmed are in the word.
This is easily generated by iterating .history, and the .pos data for building the good character list first. Then using that to build the bad character list inversely against the historical word list.
/** * Given the state object, normalize various values, using the minimum "required" value. * This does not provide as much data as `WordleSolvingAlgo` focusing on the minimum required * to make the current system work * * @param {Object} state * * @return {Object} state object normalized */function _normalizeStateObj( state ) { // Setup the initial charset state.badCharSet = new Set(); state.goodCharSet = new Set(); // Lets build the good charset for(let i=0; i<state.wordLength; ++i) { if( state.pos[i].foundChar ) { state.goodCharSet.add(state.pos[i].foundChar); } for(let char of state.pos[i].hintSet) { state.goodCharSet.add(char); } } // Lets iterate history and build badCharSet for(let i=0; i<state.history.length; ++i) { const word = state.history[i]; for( let w=0; w<word.length; ++w ) { // check the individual char let char = word.charAt(w); // If char is not in good set if( !state.goodCharSet.has(char) ) { // its in the bad set state.badCharSet.add(char); } } } // Return the normalize state object return state;}Filtering the possible word list
Now that we have the current game state, let us look into filtering the word list:
/** * Given the wordList, filter only for possible answers, using the state object. * And returns the filtered list. This function just returns the wordList, if state == null * @param {Array<String>} wordList * @param {Object} state */function filterWordList( wordList, state ) { // Skip if its not setup if( state == null || wordList.length <= 0 ) { return wordList; } // Get the word length const wordLength = wordList[0].length; // Filter and return return wordList.filter(function(s) { // Filtering logic // .... // all checks pass, return true return true; });}For the filtering logic, we first remove the words within the badCharSet.
// filter out invalid words (aka hard mode)for(const bad of state.badCharSet) { // PS : this does nothing if the set is empty if(s.includes(bad)) { return false; }}Followed by filtering out the words with wrong hint locations:
// filter out words with wrong hint locations, for each character positionfor(let i=0; i<wordLength; ++i) { // Get the word character let sChar = s.charAt(i); // Check if the chracter, conflicts with an existing found char (green) if(state.pos[i].foundChar && sChar != state.pos[i].foundChar) { return false; } // Check if the character is already a known mismatch (yellow, partial match) // for each position for(const bad of state.pos[i].hintSet) { if(sChar == bad) { return false; } }}For the subsequent words without all the known found (exact, and partial) matches:
// filter out words WITHOUT the hinted chars// PS : this does nothing if the set is emptyfor(const good of state.goodCharSet) { if(!s.includes(good)) { return false; }}In addition, we have a variant to filter out unique words for filterForUniqueWordList. This has no character duplicates and is used in the first few rounds:
let wordCharSet = new Set();// iterate the charactersfor(const char of s) { // Update the word charset wordCharSet.add(char);}// There is duplicate charactersif( wordCharSet.size != s.length ) { return false;}Generating the word statistics
After filtering for all possible answers remaining, statistics are generated via charsetStatistics( dictArray )
This is done by building an object for the type of statistics. Iterate the word list and incrementing the numbers:
/** * Analyze the given dictionary array, to get character statistics * This will return the required statistics model, to be used in guessing a word. * * Which is provided in 3 major parts, using an object, which uses the character as a key, followed by its frequency as a number * * - overall : Frequency of apperance of each character * - unique : Frequency of apperance of each character per word (meaning, duplicates in 1 word is ignored) * - positional : An array of object, which provides the frequency of apperance unique to that word position * * Note that because it is possible for the dataset to not have characters in the list / positional location, * you should assume any result without a key, means a freqency of 0 * * @param {Array<String>} dictArray - containg various words, of equal length * * @return Object with the respective, overall / unique / positional stats **/charsetStatistics( dictArray ) { // Safety check if( dictArray == null || dictArray.length <= 0 ) { throw `Unexpected empty dictionary list, unable to perform charsetStatistics / guesses`; } // The overall stats, for each character let overallStats = {}; // The overall stats, for each unique charcter // (ignore duplicates in word) let overallUniqueStats = {}; // The stats, for each character slot let positionalStats = []; // Lets initialize the positionalStats let wordLen = dictArray[0].length; for(let i=0; i<wordLen; ++i) { positionalStats[i] = {}; } // Lets iterate the full dictionary for( const word of dictArray ) { // Character set for the word const charSet = new Set(); // For each character, populate the overall stats for( let i=0; i<wordLen; ++i ) { // Get the character const char = word.charAt(i); // Increment the overall stat this._incrementObjectProperty( overallStats, char ); // Populate the charset, for overall unique stats charSet.add( char ); // Increment each positional stat this._incrementObjectProperty( positionalStats[i], char ); } // Populate the unique stats for( const char of charSet ) { // Increment the overall unique stat this._incrementObjectProperty( overallUniqueStats, char ); } } // Lets return the stats obj return { overall: overallStats, unique: overallUniqueStats, positional: positionalStats }}This is fairly straightforward for loopings across every word and every character increment within the respective statistical count.
The only gotcha is that we are unable to do a ++ increment on an object property when it's not initialized. This would result in the following error:
// This will give an exception for // TypeError: Cannot read properties of undefined (reading 'a')let obj; obj["a"]++;So we would need to use a simple helper function to increment our needed use case properly:
/*** Increment an object key, used at various stages of the counting process* @param {Object} obj * @param {String} key **/_incrementObjectProperty( obj, key ) { if( obj[key] > 0 ) { obj[key]++; } else { obj[key] = 1; }}
Scoring each word
At the heart of the solver is the scoring logic. Which is ranked on every possible word input with the given statistics and state.
Disclaimer: I do not claim that this is the most optimal word scoring function there is for Wordle. It definitely can be improved, but its quite good from my testing so far. =)
/*** The heart of the wordle solving system.* * @param {Object} charStats, output from charsetStats * @param {String} word to score * @param {Object} state object (to refine score)* * @return {Number} representing the word score (may have decimal places)**/function scoreWord( charStats, word, state = null ) { // Character set for the word, used to check for uniqueness const charSet = new Set(); // the final score to return let score = 0; // Wordle Strategy note: // // - Penalize duplicate characters, as they limit the amount of information we get // - Priotize characters with high positional score, this helps increase the chances of "exact green matches" early // reducing the effort required to deduce "partial yello matches" // - If there is a tie, in positional score, tie break it with "unique" score and overall score // this tends to be relevent in the last <100 matches // // - We used to favour positional score, over unique score in the last few rounds only // but after several trial and errors run, we found it was better to just use positonal score all the way // Lets do scoring math // ... // Return the score return score;}This goes through various stages: First, we add a safety net to prevent the system from suggesting a word again (huge negative score).
// Skip attempted words - like WHY ???if( state && state.history ) { if( state.history.indexOf(word) >= 0 ) { return -1000*1000; }}We then iterate each character of the word, and score them respectively:
// For each character, populate the overall statsfor( let i=0; i<word.length; ++i ) { // Get the character const char = word.charAt(i); // Does scoring for each character // ...}Penalizing words with repeated characters or known characters
// skip scoring of known character matches// or the attempted character hintsif( state ) { // Skip known chars (good/found) if( state.pos && state.pos[i].foundChar == char ) { score += -50; charSet.add( char ); continue; } // Skip scoring of duplicate char if( charSet.has( char ) ) { score += -25; continue; } // Skip known chars (good/found) if( state.goodCharSet && state.goodCharSet.has(char) ) { score += -10; charSet.add( char ); continue; }} else { // Skip scoring of duplicate char if( charSet.has( char ) ) { score += -25; continue; }}// Populate the charset, we check this to favour words of unique charscharSet.add( char );Finally, we calculate the score for each positional statistic with the unique character scoring being used as tie-breakers:
// Dev Note://// In general - we should always do a check if the "character" exists in the list.// This helps handle some NaN situations, where the character has no score// this is possible because the valid list will include words, that can be inputted// but is not part of the filtered list - see `charsetStatistics`if( charStats.positional[i][char] ) { score += charStats.positional[i][char]*10000;} if (charStats.unique[char]) { score += charStats.unique[char]}// -- Loops to the next char -- //Now that we have the scoring function we can start putting together all of the parts for the "suggestWord" function.

Suggesting a word (putting it together)
We have statistics that can then be used to score words. Now, let us put it together to suggest the best scoring word.
We start with being given the game state:
- normalize game state;
- generate filtered, unique, and full word lists
/*** Given the minimum state object, suggest the next word to attempt a guess.* * ---* # "state" object definition* * The solver, requires to know the existing wordle state information so this would consist of (at minimum)* * .history[] : an array of past wordle guesses* .pos[] : an array of objects containing the following info* .hintSet : set of characters that are valid "hints"* .foundChar : characters that are confirmed for the given position* * The above is compliant with the WordleAlgoTester state object format* Additional values will be added to the state object, using the above given information* --- * * @param {Object} state * * @return {String} word guess to perform*/suggestWord( state ) { // Normalize the state object state = this._normalizeStateObj(state); // Let'sLets get the respective wordlist let fullWordList = this.fullWordList; let filteredWordList = this.filterWordList( this.filteredWordList, state ); let uniqueWordList = this.filterForUniqueWords( this.uniqueWordList, state ); // As an object let wordList = { full: fullWordList, unique: uniqueWordList, filtered: filteredWordList }; // Lets do work on the various wordlist, and state // this is refactored as `suggestWord_fromStateAndWordList` // in the code base // ....}Once we have the various game states and word lists, We can decide on the "statistics word list", which we use to generate the statistics model.
// Let's decide on which word list we use for the statistics// which should be the filtered word list **unless** there is // no possible answers on that list, which is possible when// the system is being used against a WORDLE variant//// In such a case, lets fall back to the filtered version of the "full// word list", instead of the filtered version of the "answer list".let statsList = wordList.filtered;if( wordList.filtered == null || wordList.filtered.length <= 0 ) { console.warn("[WARNING]: Unexpected empty 'filtered' wordlist, with no possible answers : falling back to full word list"); statsList = this.filterWordList( wordList.full, state );}if( wordList.filtered == null || wordList.filtered.length <= 0 ) { console.warn("[WARNING]: Unexpected empty 'filtered' wordlist, with no possible answers : despite processing from full list, using it raw"); statsList = wordList.full;}Once we decide on the stats word list, we receive the stats:
// Get the charset statsconst charStats = this.charsetStatistics(statsList);Now we decide the word list to use in deciding a word. We refer to this list as the "scoredList".
In the first few rounds, we aim to use unique words as much as possible. Which would not include characters that we have tried previously. This may include words we know are not in the possible answer list.
This is intentional as we are optimizing for information gain but instead over a small random chance of early success.
However when this is emptied, or the game is in the final few rounds, we will fall back to the full list. During the final round, we will always guess using the filtered list when possible: (just give it our best answer).
// sort the scored list, use unique words in first few roundslet scoredList = wordList.unique;// Use valid list from round 5 onwards// or when the unique list is drained if( scoredList.length == 0 || state.round >= 5 ) { scoredList = wordList.full;}// Use filtered list in last 2 round, or when its a gurantee "win"if( wordList.filtered.length > 0 && // (wordList.filtered.length < state.roundLeft || state.roundLeft <= 1) //) { scoredList = wordList.filtered;}Once we decided on the scoring list to apply the stats, Let us score and sort it:
// Self referenceconst self = this;// Score word sortingscoredList = scoredList.slice(0).sort(function(a,b) { // Get the score let bScore = self.scoreWord( charStats, b, state, finalStretch ); let aScore = self.scoreWord( charStats, a, state, finalStretch ); // And arrange them accordingly if( bScore > aScore ) { return 1; } else if( bScore == aScore ) { // Tie breakers - rare // as we already have score breakers in the algori if( b > a ) { return 1; } else if( a > b ) { return -1; } // Equality tie ??? return 0; } else { return -1; }});And return the highest scoring item:
// Return the highest scoring word guessreturn scoredList[0];
Putting it all together
With the UI interaction code done in part 1. Hit the "Run" button to see how our Wordle bot does!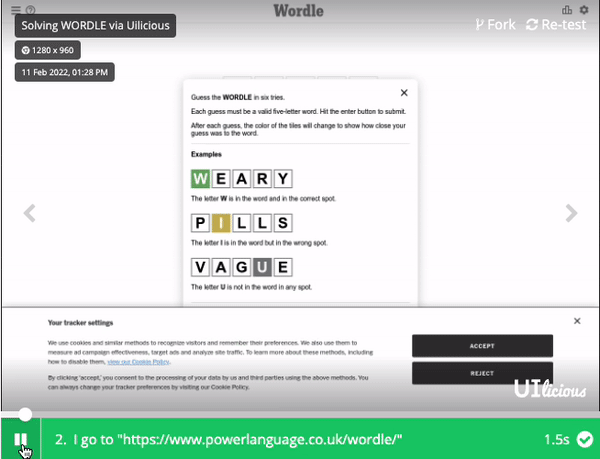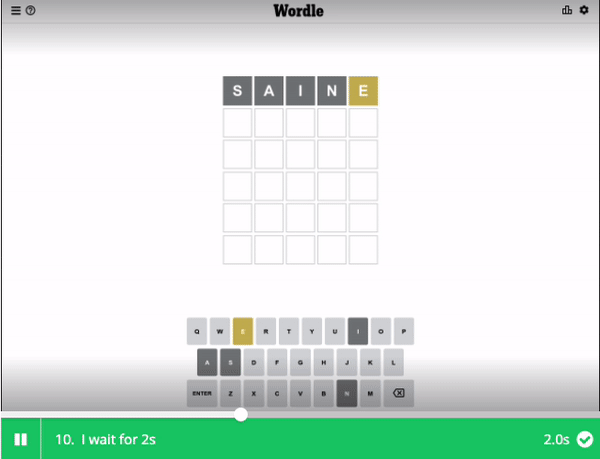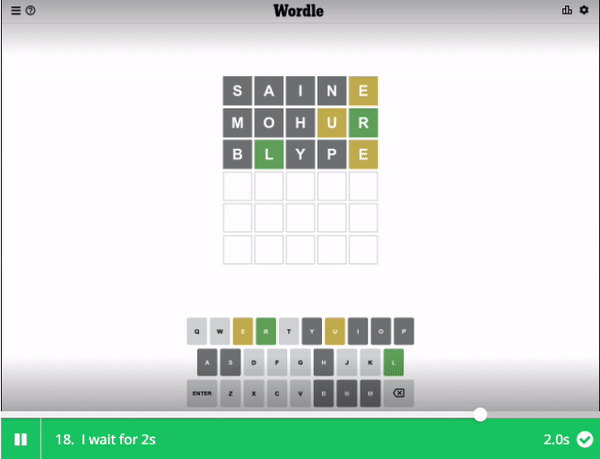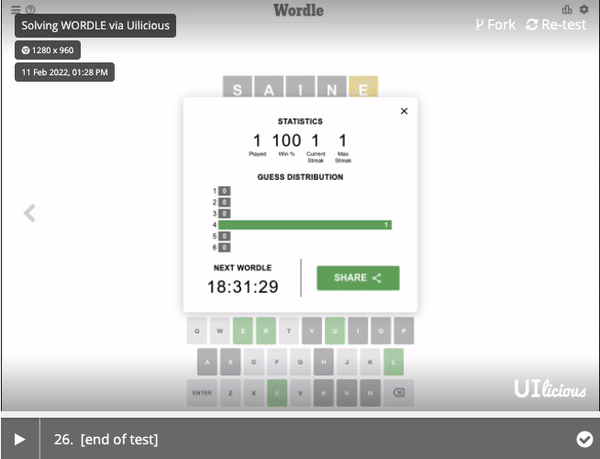
Hey, not bad, my bot solved today's Wordle!

Take away - for the humans?
Because the bots will use a rather "inhuman" technique of calculating probabilities with giant dictionaries.
Most humans will find that this is borderline of doing really weird and crazy guesses. Believe the math because it works.
While playing for the human team, your takeaway from this article is that you should just start with the word "SAINE", or whatever words you would like.
It is up to you since this is your game after all! =) Have fun.
Happy Wordling!
First published here
Original Link: https://dev.to/uilicious/saine-is-mathematically-one-of-the-best-wordle-starting-words-heres-why-2396
Dev To
More About this Source Visit Dev To