
An Interest In:
Web News this Week
- April 24, 2024
- April 23, 2024
- April 22, 2024
- April 21, 2024
- April 20, 2024
- April 19, 2024
- April 18, 2024
Some of Our Sources
- Technology Review
- Spoon Graphics
- Smashing Magazine
- Six Revisions
- Vandelay Design
- You The Designer
- Noupe
- Stylized Web
- Dev To
- Hashedout
Help Webnuz
Referal links:
Cheerio Vs Puppeteer for Web Scraping: Picking the Best Tool for Your Project
This post was originally featured on ScraperAPI.
Cheerio vs Puppeteer: Differences and When to Use Them
Cheerio and Puppeteer are both libraries made for Node.js (a backend runtime environment for Javascript) that can be used for scraping the web. However, they have major differences that you need to consider before picking a tool for your project.
Before moving into the details for each library, heres an overview comparison between Cheerio and Puppeteer:
Cheerio Vs Puppeteer
Cheerio was built with web scraping in mind.
Puppeteer was designed for browser automation and testing
Cheerio is a DOM parser, able to parser HTML and XML files.
Puppeteer can execute Javascript, making it able to scrape dynamic pages like single-page applications (SPAs).
Cheerio cant interact with the site or access content behind scripts.
Puppeteer can interact with websites, accessing content behind login forms and scripts.
Cheerio has an easy learning curve thanks to its simple syntax.
Puppeteer has a steep learning curve as it has more functionalities and requires Async for better results.
Cheerio is lightning fast in comparison to Puppeteer.
Compared to Cheerio, Puppeteer is quite slow.
Cheerio makes extracting data super simple using JQuery like syntax and CSS/XPath selectors to navigate the DOM.
Puppeteer can take screenshots, submit forms and make PDFs.
Now that you have a big picture vision, lets dive deeper into what each library has to offer and how you can use them to extract alternative data from the web.
What is Cheerio?
Cheerio is a Node.js framework that parses raw HTML and XML data and provides a consistent DOM model to help us traverse and manipulate the result data structure. To select elements, we can use CSS and XPath selectors, making navigating the DOM easier.
However, Cheerio is well known for its speed. Because Cheerio doesnt render the website like a browser (it doesnt apply CSS or load external resources), Cheerio is lightweight and fast. Although in small projects we wont notice, in large scraping tasks it will become a big time saver.
What is Puppeteer?
On the other hand, Puppeteer is actually a browser automation tool, designed to mimic users behavior to test websites and web applications. It provides a high-level API to control headless Chrome or Chromium over the DevTools Protocol.
In web scraping, Puppeteer gives our script all the power of a browser engine, allowing us to scrape pages that require Javascript execution (like SPAs), scrape infinite scrolling, dynamic content, and more.
Should You Use Cheerio or Puppeteer for Web Scraping?
Although you might already have an idea of the best scenarios, let us take all doubts out of the way. If you want to scrape static pages that dont require any interactions like clicks, JS rendering, or submitting forms, Cheerio is the best option, but If the website uses any form of Javascript to inject new content, youll need to use Puppeteer.
The reasoning behind our recommendation is that Puppeteer is just overkill for static websites. Cheerio will help you scrape more pages faster and in fewer lines of code.
That said, there are multiple cases where using both libraries is actually the best solution. After all, Cheerio can make it easier to parse and select elements, while Puppeteer would give you access to content behind scripts and help you automate events like scrolling down for infinite paginations.
Building a Scraper with Cheerio and Puppeteer [Code Example]
To make this example easy to follow, well build a scraper using Puppeteer and Cheerio thatll navigate to https://quotes.toscrape.com/ and bring back all quotes and authors from page 1.

Installing Node.js, Cheerio, and Puppeteer
Well download Node.js from the official site and follow the instructions from the installer. Then, well create a new project folder (we named it cheerio-puppeteer-project) and open it inside VScode you can use any other editor youd prefer. Inside your project folder, open a new terminal and type npm init -y to kickstart your project.

Open the Target Website Using Puppeteer
Now were ready to install our dependencies using npm install cheerio puppeteer. After a few seconds, we should be ready to go. Create a new file named index.js and import our dependencies at the top.
_const puppeteer = require('puppeteer');
const cheerio = require('cheerio');_
Next, well create an empty list named scraped_quotes to store all our results, followed by our async function, so we can have access to the await operator. Just so we dont forget, well write a browser.close() method at the of our function.
_scraped_quotes = [];
(async () => {
await browser.close();
});_
Using Puppeteer, lets launch a new browser instance, open a new page and navigate to our target website.
_const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://quotes.toscrape.com/');_
Parsing the HTML with Cheerio
To get access to the HTML of the website, we can use evaluate and return the raw HTML data this is an important step because Cheerio can only work with HTML or XML data, so we need to access it before being able to parse it.
_ const pageData = await page.evaluate(() => {
return { html: document.documentElement.innerHTML, };});_
For testing purposes, we can use console.log(pageData) to log the response to our terminal. Because we already know it works, well send the raw HTML to Cheerio for parsing.
_ const $ = cheerio.load(pageData.html);_
Now we can use $ to refer to the parsed version of the HTML file for the rest of our project.
Selecting Elements with Cheerio
Before we can actually write our code, we first need to find out how the page is structured. Lets go to the page itself on our browser and inspect the cards containing the quotes.

We can see that the elements were interested in are inside a div with the class quote. So we can select them and iterate through all of the divs to extract the quote text and the author.
After inspecting these elements, here are our targets:
- Divs containing our target elements: $('div.quote')
- Quote text: $(element).find('span.text')
- Quote author: $(element).find('.author')
Lets translate this into code:
_let quote_cards = $('div.quote');
quote_cards.each((index, element) => {
quote = $(element).find('span.text').text(); author = $(element).find('.author').text();});
_
Using the text() method we can access to the text inside the element instead of returning the string of HTML.
Pushing the Scraped Data Into a Formatted List
If we console.log() our data at this point, it will be a messy chunk of text. Instead, well use the empty list we created outside our function and push the data over there. To do so, add these two new lines to your script, right after your author variable:
_ scraped_quotes.push({
'Quote': quote, 'By': author, })_Finished Code Example
Now that everything is in place, we can console.log(scraped_quotes) before closing the browser:
_//dependencies
const puppeteer = require('puppeteer');
const cheerio = require('cheerio');
//empty list to store our data
scraped_quotes = [];
//main function for our scraper
(async () => {
//launching and opening our page
const browser = await puppeteer.launch();
const page = await browser.newPage();
//navigating to a URL
await page.goto('https://quotes.toscrape.com/');
//getting access to the raw HTML
const pageData = await page.evaluate(() => {
return { html: document.documentElement.innerHTML, };});
//parsing the HTML and picking our elements
const $ = cheerio.load(pageData.html);
let quote_cards = $('div.quote');
quote_cards.each((index, element) => {
quote = $(element).find('span.text').text(); author = $(element).find('.author').text(); //pushing our data into a formatted list scraped_quotes.push({ 'Quote': quote, 'By': author, })});
//console logging the results
console.log(scraped_quotes);
//closing the browser
await browser.close();
})();_
Resulting in a formatted list of data:
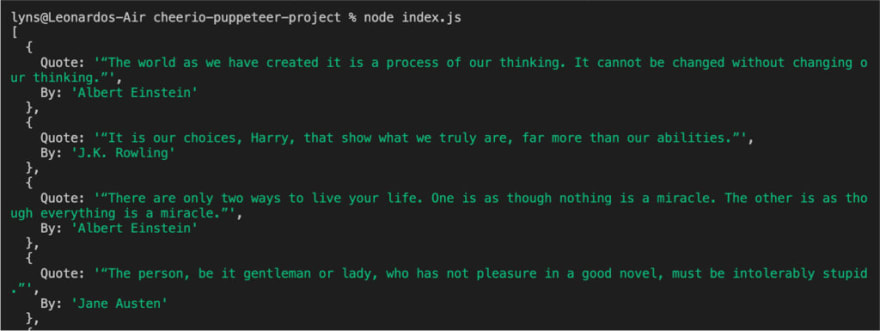
I hope you enjoyed this quick overview of arguably the two best web scraping tools available for Javascript/Node.js. Although in most cases youll want to use Cheerio over Puppeteer, for those extra complex projects Puppeteer brings the extra tools youll need to get the job done.
Original Link: https://dev.to/zoltan/cheerio-vs-puppeteer-for-web-scraping-picking-the-best-tool-for-your-project-4dkl
Dev To
More About this Source Visit Dev To