
An Interest In:
Web News this Week
- April 23, 2024
- April 22, 2024
- April 21, 2024
- April 20, 2024
- April 19, 2024
- April 18, 2024
- April 17, 2024
Some of Our Sources
- Engadget
- Mashable
- Techcrunch
- Pearsonified
- Smashing Apps
- Vandelay Design
- My Ink Blog
- Stylized Web
- Codrops
- Daily Now
Help Webnuz
Referal links:
Big Data Processing, EMR with Spark and Hadoop | Python, PySpark
Introduction:
AWS's cool data analysis services can be of significant help when it comes to processing and analyzing large amounts of data.

Use Case:
To demonstrate our data processing job, we will use EMR cluster and S3 (as a storage medium for data) along with Python code and the PySpark library. We will execute python code on a data set of Stack Overflow Annual Developer Survey 2021 and print out some results based on that data. Those results will then be stored in S3.
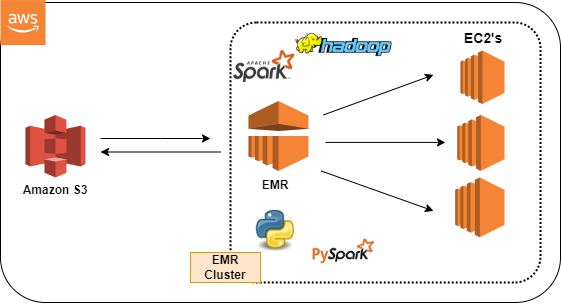
In case you are just starting with Big Data, I would like to introduce you to some terms we are going to work with, You may skip below few lines if you're already familiar.
EMR (Elastic MapReduce):
Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark , on AWS to process and analyze vast amounts of data. Wanna dig more dipper?
Amazon S3:
Amazon S3 is object storage built to store and retrieve any amount of data from anywhere.
S3 is a global service. Simply say it works like Google drive.
Wanna dig more dipper?
Apache Spark:
Apache Spark is an open-source, distributed processing system used for big data workloads. Wanna dig more dipper?
Apache Hadoop:
Apache Hadoop is an open source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data.Wanna dig more dipper?
Hadoopis designed to handle batch processing efficiently whereasSparkis designed to handle real-time data efficiently. Hadoop is a high latency computing framework, which does not have an interactive mode whereas Spark is a low latency computing and can process data interactively.
PySpark:
PySpark is the Python API for Apache Spark, an open source, distributed computing framework and set of libraries for real-time, large-scale data processing. Wanna dig more dipper?
Outline
- Downloading a Data Set from Stack Overflow
- Setup an Amazon S3 bucket with different folders
- Setting up an EMR cluster
- Write a python code to perform some analysis on data and print results
- Connecting to Cluster via SSH and using PySpark to load data from Amazon S3
- Viewing analysis results
- Cleanup
- Recap
Guided Procedure
1. Downloading a Data Set from Stack Overflow
Go to Stack Overflow Annual Developer Survey and download the latest data set for 2021
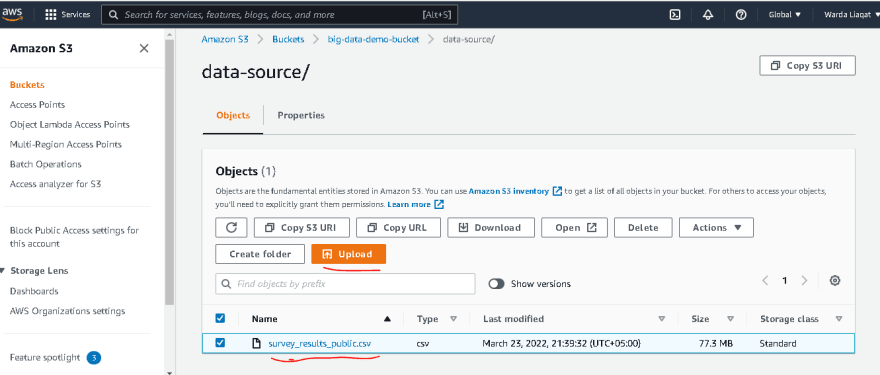
Ultimately, it will download four files, but in this case, we will only be using the "Survey Results Public" file

2. Setup an Amazon S3 bucket with different folders
- Login to AWS Management Console
- Navigate to S3 and buckets
- Create a new bucket named as
big-data-demo-bucketwith Versioning enabled and encryption true - Click on your bucket once you've created it
- Create two folders named as
bigdata-emr-logs (for storing EMR logs)anddata-source (for storing our source data file)with encryption enabled
- Place your source data file in the source data folder
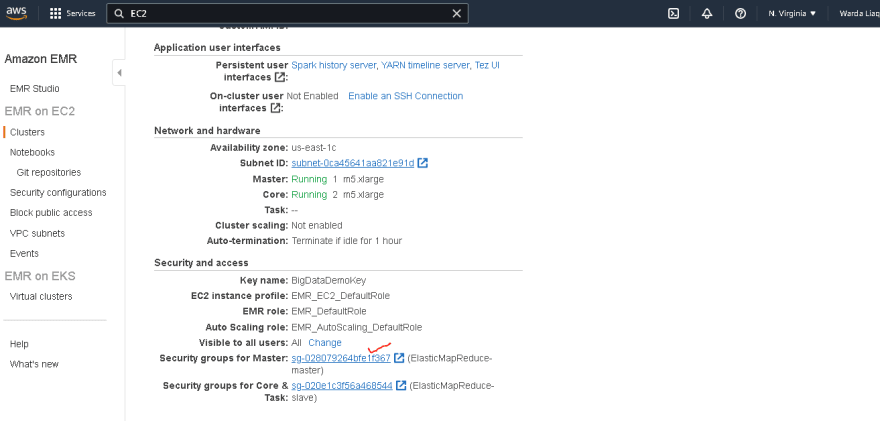
3. Setting up an EMR cluster
- Search for EMR
- Click on create cluster

- An S3 bucket is needed to store EMR logs. When you don't want to do it manually, EMR will automatically create a bucket for you to store logs.
Select a bucket and folder that we created in previous step - Select Spark with Hadoop and Zeppelin in the software configurations
- In terms of hardware configurations, you can choose EC2 type based on your needs
- For testing purposes, 3 instances would be sufficient. You may create as many as you need
- Enable auto-termination, which will terminate your cluster if any error occurs during the creation process
- You can also set the cluster to automatically terminate when it goes into idle state for long
- It is also completely up to you whether or not to scale
- Select a key pair under security and access to SSH after launching the cluster
- If you do not have a keypair, you can create easily from EC2 dashboard

- Once you click on the Create Cluster button, your cluster will be created. It usually takes 10 to 15 minutes for the cluster to become operational

4. Write a python code to perform some analysis on data and print results
Now let's write some code. A spark job will run this code to analyze the data and print out the results.
from pyspark.sql import SparkSessionfrom pyspark.sql.functions import colS3_DATA_SOURCE_PATH = 's3://big-data-demo-bucket/data-source/survey_results_public.csv'S3_DATA_OUTPUT = 's3://big-data-demo-bucket/data-output'def main(): spark = SparkSession.builder.appName('BigDataDemoApp').getOrCreate() all_data = spark.read.csv(S3_DATA_SOURCE_PATH, header=True) print('Total number of records in dataset: %s' % all_data.count()) selected_data = all_data.where((col('Country') == 'United States of America') & (col('Age1stCode') == '11 - 17 years')) print('Total number of engineers who work more than 45 hours in the US is : %s' % selected_data.count()) selected_data.write.mode('overwrite').parquet(S3_DATA_OUTPUT) print('Selected data was successfully saved to: %s' % S3_DATA_OUTPUT)if __name__ == '__main__': main()
What does this code do?
- Setting up a Spark session
- Data reading from S3
- Printing some results based on certain conditions
- A S3 folder is created for storing the results
5. Connecting to Cluster via SSH and using PySpark to load data from Amazon S3
Don't forget to enable SSH connections before trying to SSH into your cluster. The port 22 needs to be added to the cluster's master security group
- Follow the instructions accordingly to connect to your cluster if you are using Windows or Mac

- Im on windows so, I used putty for the connection

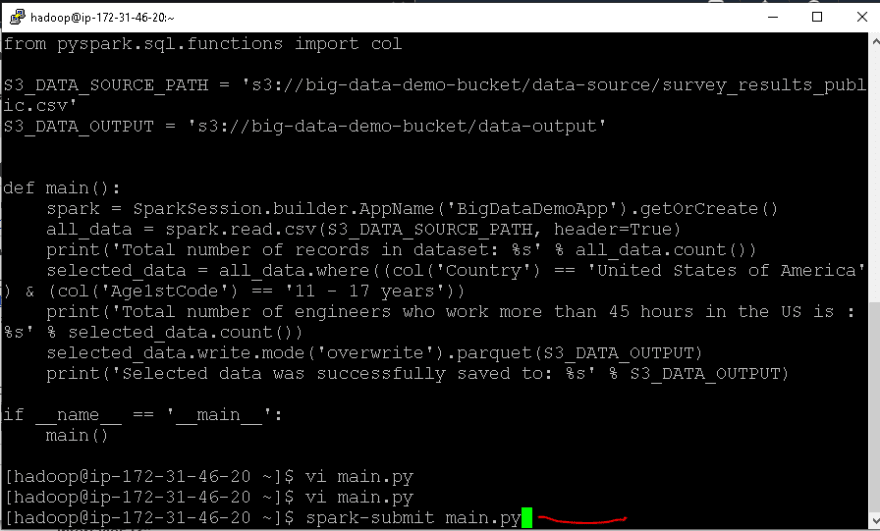
- Use the
vi main.pycommand to create a Python file using the Vim editor - Press
Ion your keyboard and paste your code - Press the
ECS keyto exit the insert mode - Type
:wqto quite the editor with saving your changes - If you type
cat main.py, you can view your code - To submit this spark job use
spark-submit [filename] - Your job will begin executing
6. Viewing analysis results
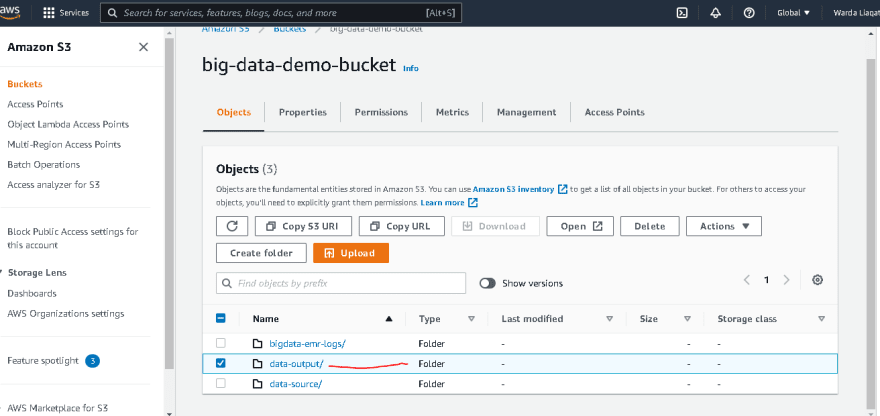
- Your three print results can be viewed in the logs after completion




- You can now see that the latest logs are stored in the logs folder in S3. Additionally, you'll notice a new folder named data-output that contains all output results with success files has been created for you


7. Cleanup
- You can then terminate the cluster to save money

- When you terminate a cluster, all EC2 associated with it will also be terminated

8. Recap
This article showed how you can use EMR and Amazon S3 to process and analyze a vast amount of data collected from Stack Overflow developer survey to extract some useful insights
Welcome to the end of this article,
Happy Clouding!
Let me know what do you think about it??
Original Link: https://dev.to/wardaliaqat01/big-data-processing-emr-with-spark-and-hadoop-python-pyspark-4jo4
Dev To
More About this Source Visit Dev To