
An Interest In:
Web News this Week
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
- March 26, 2024
- March 25, 2024
- March 24, 2024
Some of Our Sources
- Just Creative
- Smashing Magazine
- You The Designer
- Fuel Your Creativity
- Noupe
- My Ink Blog
- Stylized Web
- Android Headlines
- Dev To
- Hashedout
Help Webnuz
Referal links:
MapReduce - when you need more juice to process your data
Most of the websites you can find on the internet today are collecting some kind of data for later processing and information extraction. They usually do this to learn customer behavior, analyze logs, create better ad targeting or simply improve UI/UX wherever possible. But what if the data collected is larger than what a machine can process in a day, year, or even decade? This is where MapReduce comes into play.
What is MapReduce?
MapReduce is a programming paradigm for processing and generating big data sets with a parallel, distributed algorithm on a cluster of machines. Usually, a MapReduce program is composed of a map method which performs filtering and sorting, and a reduce method, which performs a summary operation over the output of the map function (we will discuss both map and reduce more in-depth later in the article). The underlying idea behind MapReduce is very similar to the divide and conquer approach. In fact, the key contributions of this data processing framework are not the map and reduce functions, but the scalability and fault-tolerance achieved for a variety of applications by optimizing the execution engine.
How does it work?
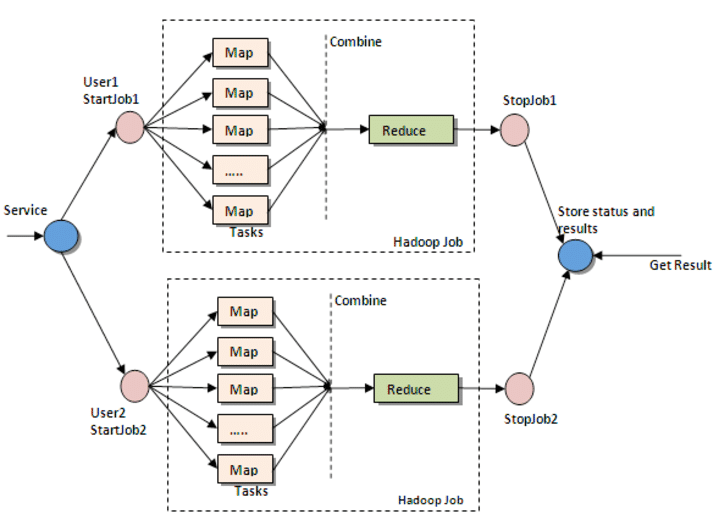
As already highlighted, the bread and butter of MapReduce are the two functions, map and reduce. They are sequenced one after the other.
The Map function takes input from the disk as (key, value) pairs, processes them, and produces another set of intermediate (key, value) pairs as output. The input data is first split into smaller blocks, then each block is then assigned to a mapper for processing. The number of mappers and block sizes is computed by the MapReduce framework depending on the input data and the memory block available on each mapper server.
The Reduce function also takes inputs as (key, value) pairs and produces (key, value) pairs as output. After all the mappers complete processing, the framework shuffles and sorts the results before passing them to the reducers. A reducer cannot start while a mapper is still processing. All the map output values that have the same key are assigned to a single reducer, which ten aggregates the values for that key.
Mappers and Reducers are servers managed by the MapReduce framework and they run the Map and Reduce functions respectively. It doesn't matter if these are the same or different servers.
To summarize how the MapReduce framework works conceptually, the map and reduce functions are supplied by the user and have the following associated types:
map (k1, v1) -> list(k2, v2)reduce (k2, list(v2)) -> list(v2)Other MapReduce processes
Other than Map and Reduce, there are two other intermediate steps, which can be controlled by the user or they can be managed by the MapReduce framework.
Combine is an optional process. The combiner is a reducer that runs individually on each mapper server, it reduces the data on each mapper further to a simplified form before passing it downstream, making shuffling and sorting easier as there is less data to work with. Often the reducer itself can be used as a combiner, but if needed, a standalone combiner can be implemented as well.
Partition is the process that translates the (key, value) pairs resulting from mappers to another set of (key, value) pairs to feed into the reducer. It decides how the data has to be presented and assigned to a particular reducer.
Example
As an example use case of MapReduce, we'll consider the problem of counting the number of occurrences of each word in a large collection of documents. The user pseudo-code for implementing this in MapReduce would be:
map(String key, String value): // key: document name // value: document contents for each word W in value: EmitIntermediate(w, "1");reduce(String key, List values): // key: a word // values: a list of counts int result = 0; for each v in values: result += parseInt(v) EmitIntermediate(toString(result));The map function emits each word plus an associated count of occurrences (in our case, just "1"). The reduce function sums together all the counts emitted for a particular word. Apart from these two function implementations, the user has to specify a config object with the names of the input and output files, and optional tunning parameters and that's it, the MapReduce framework can start processing data.
Other examples
Distributed Grep: The map function emits a line if it matches a supplied pattern. The reduce function is an identity function that just copies the supplied intermediate data to the output.
Count of URL Access Frequency: The map function processes logs of web page requests and outputs (URL, 1). The reducer function adds together all values for each URL and emits (URL, total count) pairs.
This was a brief introduction int how the MapReduce framework works. At aiflow.ltd, we try our best to obtain results as fast and as efficient as possible, to make sure we find you get the most of your data. If youre curious to find out more, subscribe to our newsletter.
References:
Original Link: https://dev.to/aiflowltd/mapreduce-when-you-need-more-juice-to-process-your-data-5b4p
Dev To
More About this Source Visit Dev To