
An Interest In:
Web News this Week
- April 18, 2024
- April 17, 2024
- April 16, 2024
- April 15, 2024
- April 14, 2024
- April 13, 2024
- April 12, 2024
Some of Our Sources
- BoingBoing
- Technology Review
- Team Treehouse
- Pearsonified
- Smashing Magazine
- Six Revisions
- TutsPlus - Design
- Fudge Graphics
- CSS Globe
- Wal You
Help Webnuz
Referal links:
Teaching AI to Generate New Pokemon
Pokemon was first created in 1996. In the twenty years, it has become one of the most recognizable franchises in the world. By March 2020:
- Pokmon video games have sold over 380 million copies worldwide.
- Pokmon Go is the most-downloaded mobile game, with over 1 billion downloads.
- Pokmon Trading Cards have sold over 34.1 billion cards.
- The entire media franchise is the highest-grossing entertainment media franchise of all time, grossing an estimated $90 billion in lifetime revenue
Yet, after all that, there are still only a total of 893 unique Pokemon.
With AI, we can change that.
The fundamental technology we will use in this work is a generative adversarial network. Specifically, the Style GAN variant.
An intuitive understanding of GANs, Progressive GANs and Style GANs
GANs first hit the stage in 2014, and garnered a lot of hype by generating images that looked reasonably realistic, was easy to train and sample from, and was theoretically satisfying. I have a separate post discussing the GAN formulation in more depth.
 From the original generative adversarial network paper
From the original generative adversarial network paperSince then, a series of changes have been made to the basic GAN to generate some amazingly realistic looking images.
 GAN improvements through the ages
GAN improvements through the agesThe initial GAN architecture was designed with a generator and discriminator that would closely resemble a standard convolutional neural network that upscales or downscales images.
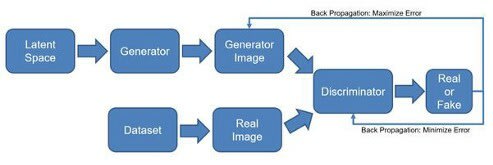 Traditional Generative Adversarial Network Architecture
Traditional Generative Adversarial Network ArchitectureProgressive GAN
Progressive GANs is an attempt to fix a fundamental problem with traditional GANs which is that the generator has a much harder job than the discriminator, especially with high resolution images. (In the same way its easier for you to classify an image as being a cat or dog than it would be to draw an image of a cat or dog.)
Progressive GANs alter the training phase of traditional GANs by first training a single layer GAN against a 4x4 image, then a two layer GAN against an 8x8 image, reusing the already trained 4x4 layer. This makes the problem for the generator easier during the earlier phases of training, and scales up towards generating high resolution images.
 Progressive GANs start by learning how to generate low resolution images and scale up as training progresses.
Progressive GANs start by learning how to generate low resolution images and scale up as training progresses.Style GAN
However, both traditional GANs and Progressive GANs offer little control over the image produced by the generator, for instance, generating a person with dark hair vs light hair. Or female vs male. Style GANs extend the architecture of traditional GANs to allow for more control of the image produced by the generator.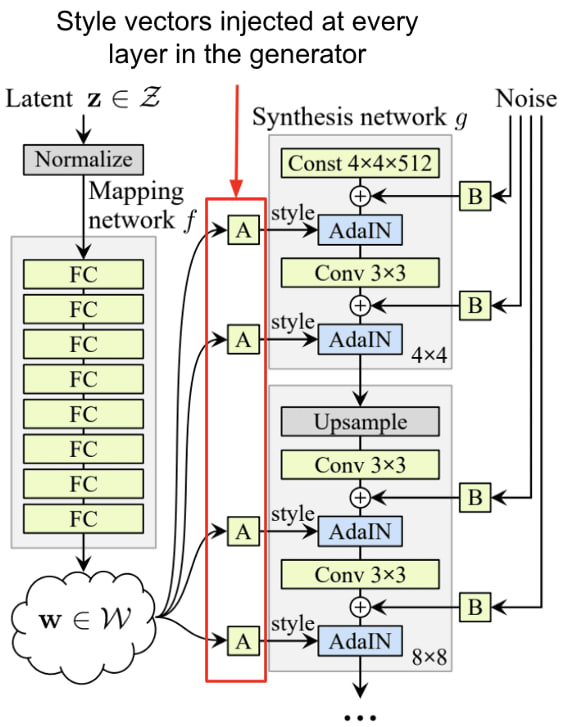
The way it does this is by changing the architecture of the generator by adding style vectors, which is the main source of randomness in the image generator process. The style vector is injected at each layer in the generator network to add style variations at different resolutions.
The style vectors that are used can then be reused from one generated image to the next, by injecting the same style vector, thereby transferring the style (hair color, age, gender, etc) from one image to another.
 Style transfer at different layers in the generator
Style transfer at different layers in the generatorHow do I build one?
Theres a bit too much code to a Style GAN to be able to review all of it, but we can go through each important piece with some code samples.
- Building off Progressive GANs
- Addition of mapping network
- Adaptive instance normalization
- Removal of latent vector input to generator
- Addition of noise to each block
The Style GAN architecture
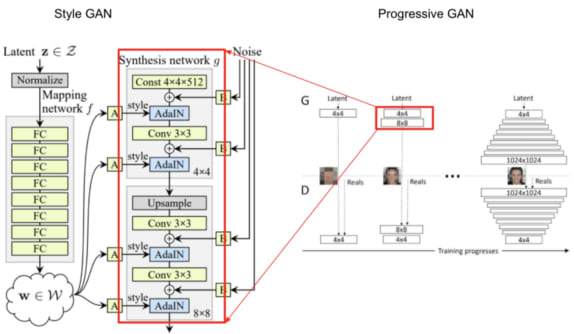 What a Style GAN adds to a Progressive GAN
What a Style GAN adds to a Progressive GANThe Style GAN starts from Progressive GANs and adds a series of improvements.
Mapping Network
Here is the StyleGAN architecture. Notice that the latent variable z is not directly passed into the generator. Rather, its passed through an 8 layer MLP, called the mapping network, to generate a style vector.
This style vector is then injected into every layer of the generator network (which is referred to as the synthesis network in this paper). The style vector is used to produce a scale and bias vector for each channel in the image as part of the adaptive instance normalization.
flatten = lambda t: [item for sublist in t for item in sublist]class MappingNetwork(nn.Module): def __init__(self): super().__init__() blocks = [[nn.Linear(512, 512), nn.LeakyReLU(0.2)] for _ in range(8)] self.net = nn.Sequential(*flatten(blocks)) def forward(self, latent_vector): style_vector = self.net(latent_vector) return style_vectorAdaptive Instance Normalization (AdaIN)
To understand how the adaptive instance normalization works, lets first review how batch normalization works.
The formulation of AdaIN is very similar to the formulation for a batch normalization:
class AdaIN(nn.Module): def __init__(self): super().__init__() def mu(self, x): """ Takes a (n,c,h,w) tensor as input and returns the average across it's spatial dimensions as (h,w) tensor [See eq. 5 of paper]""" n = torch.sum(x,(2,3)) d = x.shape[2]*x.shape[3] return n / d def sigma(self, x): """ Takes a (n,c,h,w) tensor as input and returns the standard deviation across it's spatial dimensions as (h,w) tensor [See eq. 6 of paper] Note the permutations are required for broadcasting""" n = torch.sum((x.permute([2,3,0,1])-self.mu(x)).permute([2,3,0,1])**2,(2,3)) d = x.shape[2]*x.shape[3] return torch.sqrt(n / d) def forward(self, x, y): """ Takes a content embeding x and a style embeding y and changes transforms the mean and standard deviation of the content embedding to that of the style. [See eq. 8 of paper] Note the permutations are required for broadcasting""" return (self.sigma(y)*((x.permute([2,3,0,1])-self.mu(x))/self.sigma(x)) + self.mu(y)).permute([2,3,0,1])Addition of Gaussian Noise
Gaussian noise is added to the activation maps before each AdaIN operation which is used to generate style variation at each level of the generator.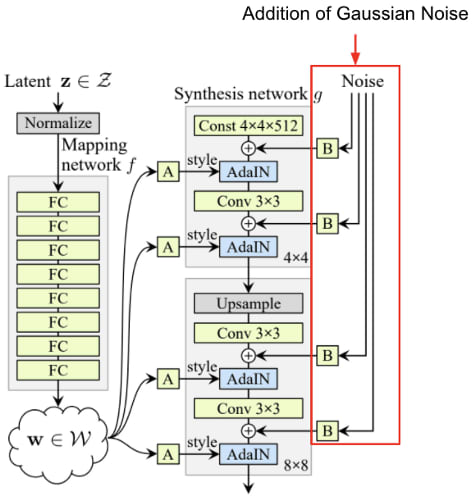
The reason for introducing this noise is to force the model to learn local style level variations.
 The added noise is what allows for a generated image to be identical overall but still output variation at local levels
The added noise is what allows for a generated image to be identical overall but still output variation at local levels (a) Noise is applied to all layers. (b) No noise. Noise in fine layers only (641024 ). (d) Noise in coarse layers only (432 ).
(a) Noise is applied to all layers. (b) No noise. Noise in fine layers only (641024 ). (d) Noise in coarse layers only (432 ).Removal of Latent Vector Input to Generator
Traditional GANs generate a latent vector, which is fed to the generator, to produce samples. Style GANs actually just use a constant 4x4x512 vector that is kept the same during training and inference. This is possible because the variant comes from the style vectors and gaussian noise added at each layer via the AdaIN operation, rather than the initial latent vector.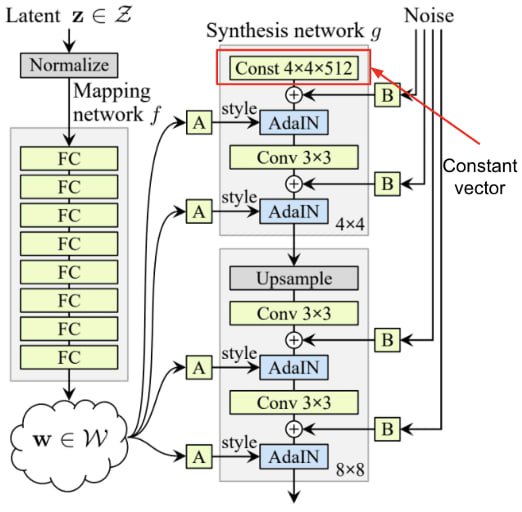
Remember that the whole point of Style GANs was to discover style vectors that could be reapplied from one image to another. This only works if both images start from the same canvas, which is what this 4x4x512 constant acts as. If the canvas changes, then the style vectors learned would not be transferable.
Training on a Pokemon Dataset
Lets see what happens when we throw this model against a dataset of ~35,000 Pokemon images.
It took about a week to train a model to produce results that looked reasonable on an Nvidia GeForce 3070 GPU. Im unsure how much better the images would look after a few more weeks of training, but Ill keep it running for a bit longer.
A Few Suggestions for New Pokemon
 Penguion
Penguion Potatoad
Potatoad Albapod
Albapod Hydraleaf
Hydraleaf Firenite
FireniteOriginal Link: https://dev.to/mage_ai/teaching-ai-to-generate-new-pokemon-3kk1
Dev To
More About this Source Visit Dev To