
An Interest In:
Web News this Week
- April 19, 2024
- April 18, 2024
- April 17, 2024
- April 16, 2024
- April 15, 2024
- April 14, 2024
- April 13, 2024
Some of Our Sources
- Smashing Magazine
- TutsPlus - Design
- Creative Curio
- Inspiredology
- Reencoded
- Stylized Web
- Spyre Studios
- Android Headlines
- Willems Lab
- TechPowerUp
Help Webnuz
Referal links:
Getting started with Redshift
Technology
The Amazon Redshift technology is a column-oriented storage in the cloud. It is best suited for storing OLAP workloads, summing over a long history.
Most relational databases execute multiple queries in parallel if they have access to many cores/servers. However, every query is always executed on a single CPU of a single machine. This is acceptable for OLTP, that mostly updates and few rows retrieval.
Redshift provides MPP - massive parallel processing:
Databases parallelize the execution of one query on multiple CPUs/machines. This is possible because a table is partitioned and those partitions are processed in parallel.

Architecture
Cluster
The total number of nodes in a Redshift cluster is equal to the number of AWS EC2 instances used in the cluster.
Leader Node
- coordinates the compute nodes
- handles external communication
- optimizes query execution
Compute Nodes
- each with own CPU, memory and disk (determined by the node type)
- scale up: get more powerful nodes
- scale out: get more nodes
Node Slices
- each compute node is logically divided into a number of slices
- a cluster with n slices (like CPU's) can process n partitions of tables simultaneously
- each slice in a Redshift cluster is at least 1 CPU with dedicated storage and memory for the slice (n slices = n partitions).

How to use a Redshift Cluster
Make sure you have set up an AWS Billing Alarm first. As it might get expensive when we use Redshift nodes.
Load data
Use SELECT INTO to copy result into another table
or into a different database server, if both servers are running in the same RDBMS.
SELECT factOne, factTwoINTO OtherServer.newFactTableFROM table X, YWHERE X.id = Y.fidGROUP BY Y.dUse an ETL server if we need to transfer data between different DB Servers. In the first step the ETL server runs a SELECT on the source DB server. Then the results are stored as CSV files on the ETL server. Keep in mind that this will need a large storage. Finally the data is transferred via INSERT or COPY to the destination DB server.
In an AWS implementation an EC2 instance would act as a client between RDS and Redshift to copy data and S3 is used as a staging area for the data. When using S3 we will not need to worry about reliability or the amount of storage as it is managed by AWS.

Do enable parallelism
- We want to split up a table into multiple files before ingesting it, so we can use multiply COPY commands simultaneously. To enable parallel work we can either use a common prefix or a manifest file to get explicit files.
// common prefix example// this will output a lot of files with */split/part-*COPY cars FROM 's3://whererver/cars/split/part'CREDENTIALS 'aws_iam_role=arn:aws:iam:0815:role/redshiftRole'qzip DELEIMTER ';' REGION 'eu-central-1';// manifest exampleCOPY tableFROM 's3://yourbucket/cust.manifest'IAM_ROLE 'arn:aws:iam:0815:role/redshiftRole'manifestFurthermore we want to work in the same AWS region and make sure to compress the csv files. If needed, we can specify a delimiter.
Use COPY and Automatic compression optimisation
- To transfer data from an S3 staging area to a Redshift cluster we use the COPY command, because INSERT is very slow.
- the optimal compression strategy for each column type is different.
- Redshift gives the user control over the compression of each column
- The COPY command makes automatic best-effort compression decisions for each column
We can also ingest data directly using ssh form EC2 machines. If not, we need S3 as a staging area. Usually an EC2 ETL worker needs to run the ingestion jobs orchestrated by a dataflow product like Airflow, Luigi, Nifi, StreamSet or AWS Data Pipeline.
Optimization of partitions
Per default a table is partitioned up into many pieces and distributed across slices in different machines blindly. I there is an access pattern of a table, we can use a better strategies: either use a distribution style or sorting key to optimize our table design.
Distribution style EVEN
With this distribution style a table is partitioned on slices such that each slice would have an almost equal number - load balancing - of records for the partitioned table. The round-robin principle is used. Works well if a table is not joined. If we want to join tables this is very slow because records will have to be shuffled for putting together the join result.

Distribution style ALL aka BROADCASTING
Every table is copied to each database/slice. This works well for small tables (most of the dimension tables) to speed up joins as there is no shuffling needed and the joins can be executed in parallel.
Distribution style AUTO
Redshift decides what distribution style to take. If the table is small enough "ALL" is used, otherwise "EVEN" is used.
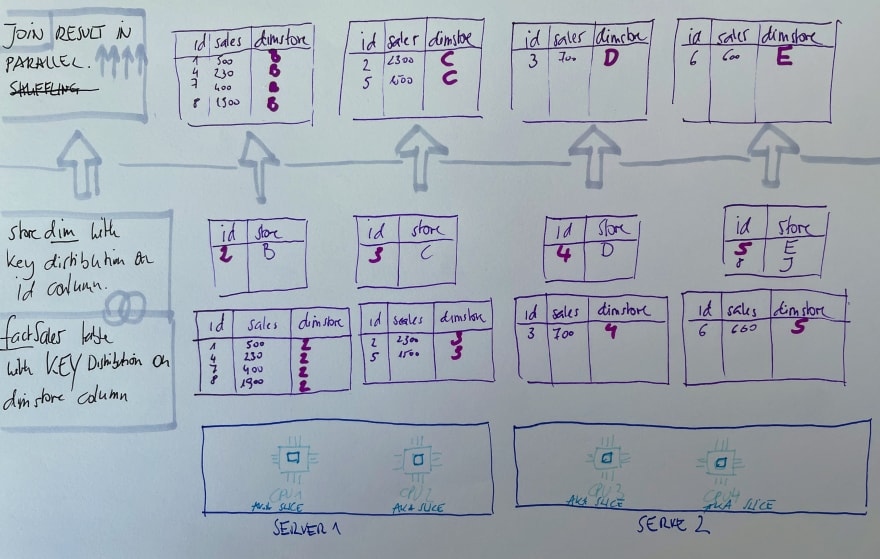
Distribution style KEY
Rows with similar values are placed in the same slice.
This could lead to a skewed distribution if some values of the distribution key are more frequent than others.
It is useful if a dimension table is too big to use distribution style ALL. In that case, we distribute both the fact table and the dimension table using the same distribution key.
If two tables are distributed joining key, Redshift collocates the rows from both tables on the same slices.
SORTING KEY
We can define its columns as sort key to sort rows before distribution to slices upon loading.
This minimizes the query time since each node already has contiguous ranges of rows based on the sorting keys.
Useful for column that are used frequently in sorting like the date dimension and its corresponding foreign key in the fact table. So if we use a lot of ORDER BY in our queries we should use a sort key in the fact tables.
CREATE TABLE order(o_orderkey integer not null,o_custkey integer not null,o_partkey integer not null DISTKEY,o_date integer not null SORTKEY)CREATE TABLE part(p_partkey integer not null SORTKEY DISTKEY,p_name varchar(250) not null,p_color varchar(250) not null)When using a sorting key and the distribution style KEY we could have a performance improvement of 70% compared to distribution style ALL.
Unload data
UNLOAD ('select * from cars limit 100')TO 's3://yourbucket/cars_pipe_'IAM_ROLE 'arn:aws:iam:0815:role/redshiftRole'Original Link: https://dev.to/barbara/redshift-2l6h
Dev To
More About this Source Visit Dev To