
An Interest In:
Web News this Week
- April 20, 2024
- April 19, 2024
- April 18, 2024
- April 17, 2024
- April 16, 2024
- April 15, 2024
- April 14, 2024
Some of Our Sources
- Web Designer Wall
- Pearsonified
- The Logo Smith
- Crazy Leaf Design
- CSS Globe
- Line 25
- Stylized Web
- Specky Boy
- Dev To
- TechPowerUp
Help Webnuz
Referal links:
How to build a search engine with word embeddings
Imagine you have a large set of news articles, and want to provide a way to allow your users to search through them. For example, here are 5 random articles from the Economist:
- An investment bonanza is coming
- Who governs a countrys airspace?
- What is a supermoon, and how noticeable is it to the naked eye?
- What the evidence says about police body-cameras
- Who controls Syria?
Lets think about what kind of queries potential users issue and the articles that we would want to return.
Exact and Substring Matches
- A search for investment should return the 1st article.
- A search for supermoon should return the 3rd article.
- A search for syria should return the 5th article.
This is quite simple to implement with traditional information retrieval techniques, since these queries have keyword matching.
Harder Examples
- A search for banking should probably return the 1st article.
- A search for astrology should return the 3rd article.
- A search for middle east should return the 5th article.
The challenge with these queries is that none of them are actually a keyword match in the original documents. However, there isnt any string matching we can perform between the search query and the document.
What we need is a way to perform searches over text without requiring exact keyword matches between words in the query and words in the documents.
Word Embeddings
One way we can do this is with word embeddings, which capture the semantics of words in vector representation.
If we can find a way to create a vector for the query, and a vector for every document, in the same vector space, then we can just compute the similarity between our query vector, and every document, to retrieve the document that is most semantically similar to our query.
Creating Document Embeddings from Word Embeddings
Assuming we have lookup table of a word to its embedding, how do we actually create an embedding representing a string of words?
We can think of the semantics of a document as just the average of the semantics of individual words, and compute a mean word embedding to represent a document.
Specifically:
def create_mean_embedding(words): return np.mean( [model[word] for word in words if word in model], axis=0)This would capture the average semantic of a document or query.
Another way we can build a document embedding is by by taking the coordinate wise max of all of the individual word embeddings:
def create_max_embedding(words, model): return np.amax( [model[word] for word in words if word in model], axis=0)This would highlight the max of every semantic dimension.
We can also concatenate the two embedding types to get a better representation of the document:
def create_embedding(words): return np.concatenate([ create_max_embedding(words), create_mean_embedding(words) ])Lets try apply this to the simple example documents we highlighted above.
We will be using gensim to load our Google News pre-trained word vectors. Find the code for this here.
Ranking with embeddings
Query: "banking"Rank: 0 | Top Article: An investment bonanza is comingRank: 1 | Top Article: Who governs a country's airspace?Rank: 2 | Top Article: What is a supermoon, and how noticeable is it to the naked eye?Rank: 3 | Top Article: Who controls Syria?Rank: 4 | Top Article: What the evidence says about police body-camerasQuery: "astrology"Rank: 0 | Top Article: What is a supermoon, and how noticeable is it to the naked eye?Rank: 1 | Top Article: Who governs a country's airspace?Rank: 2 | Top Article: Who controls Syria?Rank: 3 | Top Article: What the evidence says about police body-camerasRank: 4 | Top Article: An investment bonanza is comingQuery: "middle east"Rank: 0 | Top Article: Who controls Syria?Rank: 1 | Top Article: Who governs a country's airspace?Rank: 2 | Top Article: An investment bonanza is comingRank: 3 | Top Article: What is a supermoon, and how noticeable is it to the naked eye?Rank: 4 | Top Article: What the evidence says about police body-camerasDual space embedding
So far weve used the standard pre-trained word2vec embeddings to represent both the query and document embeddings. But lets think about how word2vec constructs these vectors to come up with a more clever way to create these embeddings.
The core idea of word2vec is that words that are used in similar contexts, will have similar meanings. Focusing on the skip-gram variant of the model, this idea is formulated as trying to predict the context words from any given word. Check out this post if this is confusing to you.
In a skip-gram model, a one-hot encoded word is mapped to a dense representation, which then is mapped back to the context of that word (context in this case refers to the words that surround the target word). Usually, we keep the first transformation matrix W (in the diagram below), which becomes our word embeddings, and discard the matrix that maps to context words W.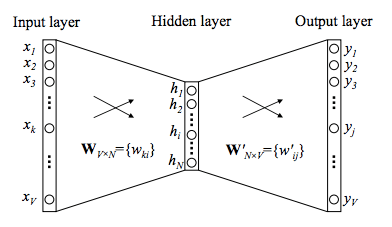
If we think deeply about the behavior of W and W matrix: the W embeddings goal is to map a word to an intermediate representation, and the W matrix maps from the intermediate representation to a context. This naturally results in W capturing the semantics of a word, while W captures the context of a word.
We can frame our search problem in a similar way: The query being the word and the document being the context. In this way, if the query is embedded using W, while the document is embedded using W, comparing the similarity between the two vectors would indicate whether or not the document acts as a good context for the query.
Lets consider two simple documents, that we could potentially return for a query harvard, and decide which one is more relevant:
Document 1:
Harvard alumni receives Document 2:
Yale, NYU and Harvard As a user, youd probably want to see the first document. However, our current embedding model would assign the second document a higher relevance score. Why? Because the terms Pittsburg Steelers, Baltimore Ravens and Cincinnati Bengals are similar to the term New England Patriots, since they are all football teams. (Recall that the word2vec model measures similarity as words that have similar contexts. Football team names would exists in similar context). Therefore, the embedding for the query and document 2 will be more similar than the query and document 1.
However, using W to create the document embedding, and W to create the query embedding, will allow a similarity measure of how well does this document represent the context of this query.
Indeed, these are the results published in A Dual Embedding Space Model for Document Ranking.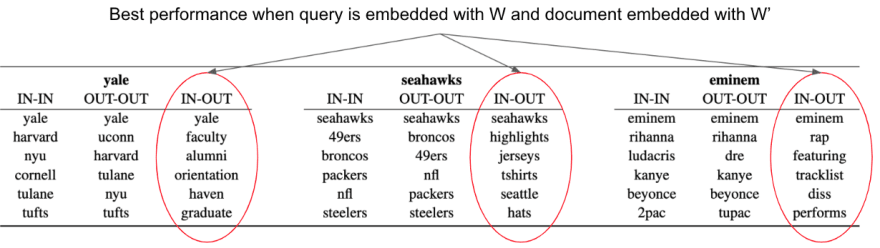
This table above shows the closest word embeddings to the words yale with three different embedding comparisons.
- IN-IN: The bolded word is embedded with W and the words below are the closest word embeddings in W.
- OUT-OUT: The bolded word is embedded with W and the words below are the closest word embeddings in W.
- IN-OUT: The bolded word is embedded with W and the words below are the closest word embeddings in W.
Observe that while Yale is more semantically similar to Harvard, if a document about Harvard came up when searching Yale, that wouldnt make a lot of sense.
With that in mind, it seems the IN-OUT embedding scheme provides the most relevant words for a search system. If someone searched for the word Yale, I would expect documents with the terms faculty, alumni, and orientation rather than harvard and nyu.
How do we deploy this?
Too many ML articles stop here, but deployment is typically half the challenge.
Typically, these models are deployed as a ranker after a retrieval model. The pipeline is typically structured like this:
The purpose of the retrieval model is to find the ~100 most similar documents based on keywords among millions of other documents, while the purpose of the ranking model is to find the most semantically relevant document in the set of 100.
BM25 is a common document retrieval method which is implemented in most search systems.
First, lets implement a retrieval model that leverages the rank-bm25 package. In a production setting, we would probably use something like Elasticsearch for this part.
from rank_bm25 import BM25Okapi as BM25class Retriever(object): def __init__(self, documents): self.corpus = documents self.bm25 = BM25(self.corpus) def query(self, tokenized_query, n=100): scores = self.bm25.get_scores(tokenized_query) best_docs = sorted(range(len(scores)), key=lambda i: -scores[i])[:n] return best_docs, [scores[i] for i in best_docs]Next, lets build the ranking model, which takes a list of documents and re-ranks them according to the similarity between the query embedding and the document embedding.
And now, lets stitch the code together.
Lets take a look at a real example output of this for the query harvard hockey against the Microsoft News Dataset. However, there are no documents in the corpus containing both the terms harvard and hockey, making this a tricky problem.
Here are the top 20 results for the query harvard hockey from the BM25 model.
The documents with the highest score from the BM25 retrieval model is Admissions scandals unfolding at Harvard university and How a Harvard class project changed barbecue
I suspect many people do not think this is a very relevant article to harvard hockey
But if we re-rank the top 100 results from the BM25 model with the embedding based model, here is what we get:
Now the results are much more semantically relevant to college hockey results.
Summary
A dual space embedding approach to creating query and document embeddings for embedding based ranking can offer more contextually relevant results than the traditional word embedding approach.
References
Original Link: https://dev.to/mage_ai/how-to-build-a-search-engine-with-word-embeddings-56jd
Dev To
More About this Source Visit Dev To