
An Interest In:
Web News this Week
- April 16, 2024
- April 15, 2024
- April 14, 2024
- April 13, 2024
- April 12, 2024
- April 11, 2024
- April 10, 2024
Some of Our Sources
- Technology Review
- Web Designer Wall
- The Logo Smith
- Smashing Apps
- Six Revisions
- CSS Globe
- 24 Ways
- Freelance Switch
- Design Modo
- Android Dissected
Help Webnuz
Referal links:
Amazon Textract with expense analyzing
Amazon Textract now supports receipts and invoices processing which makes expense management systems analyze better with only receipt's or invoice's image or document.
Read more about the announcement.
Key takeaways from the blog
What is Textract?
Amazon Textract is a fully-managed Machine Learning service which extract textual information from documents and images. The Textract DetectDocumentText API is capable of detecting and extracting textual data which are handwritten or typed present either as texts, forms or tables in the document or image.
Common use-cases of Textract are -
- Data capture from forms.
- Automating certain processes similar to KYC process.

 Jeff Barr (@ )@jeffbarr
Jeff Barr (@ )@jeffbarr Cool demo video @mikegchambers - Amazon Textract Handwriting Recognition (New) - youtube.com/watch?v=Efbgai . Be sure to fill in those TPS Reports...14:55 PM - 16 Nov 2020
Cool demo video @mikegchambers - Amazon Textract Handwriting Recognition (New) - youtube.com/watch?v=Efbgai . Be sure to fill in those TPS Reports...14:55 PM - 16 Nov 2020


And more use-cases available on Amazon Textract documentation. Improve newspaper digitalization efficacy with a generic document segmentation tool using Amazon Textract buff.ly/3xFEKnp #AWS #MachineLearning19:27 PM - 25 Jun 2021
Improve newspaper digitalization efficacy with a generic document segmentation tool using Amazon Textract buff.ly/3xFEKnp #AWS #MachineLearning19:27 PM - 25 Jun 2021

Textract exposes the following SDK APIs for developers to integrate -
AnalyzeDocument(documentation)AnalyzeExpense(documentation)DetectDocumentText(documentation)GetDocumentAnalysis(documentation)GetDocumentTextDetection(documentation)StartDocumentAnalysis(documentation)StartDocumentTextDetection(documentation)
With Textract, the processing of images or documents can be handled synchronously or asynchronous.StartDocumentAnalysis / GetDocumentAnalysis and StartDocumentTextDetection / GetDocumentTextDetection are the asynchronous implementation of Amazon Textract and whenever the action start (StartDocumentAnalysis and StartDocumentTextDetection) is executed, it returns a JobID which is referred to when getting the data.
Textract APIs are flexible to take either document/image buffer data or the object stored on S3 to process and extract textual information.
Python samples are available in - GitHub/awsdocs
 aws-samples / amazon-textract-code-samples
aws-samples / amazon-textract-code-samples
Amazon Textract Code Samples
Amazon Textract Code Samples
This repository contains example code snippets showing how Amazon Textract and other AWS services can be used to get insights from documents.
Usage
python3 01-detect-text-local.py
For examples that use S3 bucket, upload sample images to an S3 bucket and update variable "s3BucketName" in the example before running it.
Python Samples
| Argument | Description |
|---|---|
| 01-detect-text-local.py | Example showing processing a document on local machine. |
| 02-detect-text-s3.py | Example showing processing a document in Amazon S3 bucket. |
| 03-reading-order.py | Example showing printing document in reading order. |
| 04-nlp-comprehend.py | Example showing detecting entities and sentiment. |
| 05-nlp-medical.py | Example showing detecting medical entities. |
| 06-translate.py | Example showing translation of documents. |
| 07-search.py | Example showing document indexing in Elasticsearch. |
| 08-forms.py | Example showing form (key/value) processing. |
| 09-forms-redaction.py | Example showing redacting information in document. |
| 10-tables.py | Example showing table processing. |
| 11-tables-expense.py | Example showing validation of table data. |
| 12-pdf-text.py | Example showing PDF document processing. |
.NET Usage
Usage: dotnet run [--switch]To run this consoleNodeJS samples are in an open pull request -
Added NodeJS samples #18

Issue #, if available:
Description of changes:Added NodeJS text detect samples.
By submitting this pull request, I confirm that you can use, modify, copy, and redistribute this contribution, under the terms of your choice.
How Textract processes receipts and invoices
Textract AnalyzeExpense API processes the data and extracts the key information from the document such as Vendor names, Receipt number or Invoice number. AnalyzeExpense API is available only in the latest version of SDK, as this is one of the new functions available now. So ensure, you have updated your SDK.
Starting today, Amazon Textract adds the following capabilities for receipts and invoices: 1) Identifies Vendor Name - Amazon Textract can find the vendor name on a receipt even if it's only indicated within a logo on the page without an explicit label called vendor. It can also find and extract item, quantity, and prices that are not labeled with column headers for line items, 2) Enables consolidation of output from many documents - Textract normalizes keynames and column headers when extracting data from invoices and receipts, into a standard taxonomy. For example, it detects that invoice no. invoice number and receipt # are identical and outputs INVOICE_RECEIPT_ID, so that downstream applications can easily compare output from many documents, and 3) Extracts line item details, even when the column headers are missing - Textract extracts line items including items, quantities, and prices of individual goods purchased from an invoice or a receipt. If the table of line items does not include column headers, Textract now infers what the column headers are meant to be based on the table content.
As described in the announcement.
This makes it easier for systems which are integrating Textract to manage expense analysis with the consolidated information.
Implementing Textract with NodeJS SDK
In this walkthrough, we will be using the AnalyzeExpense and AnalyzeDocument API from Textract.
To get started, you can navigate to Amazon Textract AWS Console from where you will be able to run Textract on sample documents and view the response pretty-formatted on the console.
Image used for the demo - 
When using AnalyzeDocument from the console/ SDK API, you would have to use what type of feature you want to extract. From SDK API you would have to pass the input for FeatureTypes as TABLES or FORMS, if you are trying this from the console, you can additionally extract all the text as RAW TEXT also.
Raw text - 
Forms - 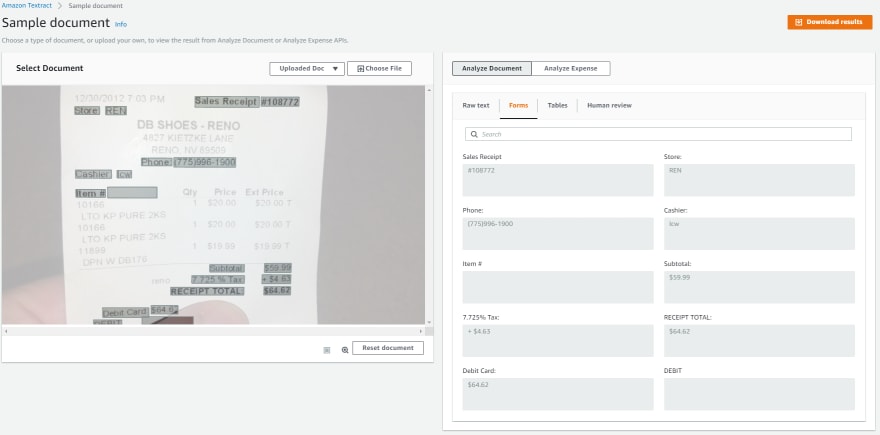
Tables - 
var params = { Document: { S3Object: { Bucket: 'xxxxxx', Name: 'download.jfif', } }, FeatureTypes: ["TABLES", "FORMS"] }; let response = await textract.analyzeDocument(params).promise() return responseResponse available on GitHub Gist
For AnalyzeExpense API, from the console and SDK API, you will get the response with both SummaryFields and LineItemFields.
Summary fields - 
Line item fields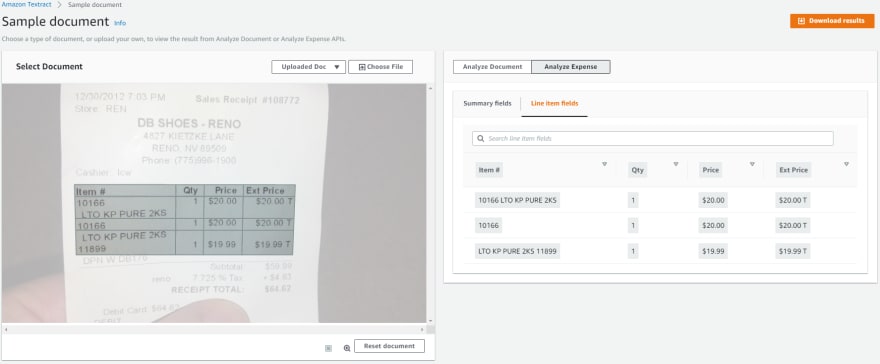
var params = { Document: { S3Object: { Bucket: 'xxxxxx', Name: 'download.jfif', } }, }; let response = await textract.analyzeExpense(params).promise() return responseResponse available on GitHub Gist
Pricing
Amazon Textract's pricing varies upon the API that is executed as internally it uses OCR technology to process and extract textual information. Also based on the feature type, it focuses to extract either FORM or TABLE data.
Detailed information on pricing is available on Textract pricing page.
Conclusion
Amazon Textract enables applications to integrate with SDK APIs so that the documents or images with textual data from various representations of text in form of raw text, forms, tables are easily extratable. Now with the expense analysis support, Textract goes a level ahead to consolidate the items and also extract key information from the invoice or receipts. Textract also provides the confidence level / percentage of the extracted text making it a choice for the integrating applications to either consider it or neglect it.
Original Link: https://dev.to/aws-builders/amazon-textract-with-expense-analyzing-516b
Dev To
More About this Source Visit Dev To