
An Interest In:
Web News this Week
- April 20, 2024
- April 19, 2024
- April 18, 2024
- April 17, 2024
- April 16, 2024
- April 15, 2024
- April 14, 2024
Some of Our Sources
- Simplebits
- Web Designer Wall
- Team Treehouse
- Smashing Magazine
- Naldz Graphics
- Line 25
- CSS Tricks
- Freelance Switch
- Web Resource Source
- Daily Now
Help Webnuz
Referal links:
Devtools for Data Privacy Step 1: Privacy Taxonomy V1.0
NOTE: If youd like to jump straight to the Github repo or documentation you can get these at:
Table of Contents
Introduction
Back in July, I articulated some of Ethycas driving ideas in a Stack Overflow feature: Privacy is an afterthought in the software lifecycle. That needs to change.
To solve the problem I described, I believe the dev community needs to agree upon and build an open source definition language and set of tools for privacy.
The purpose of these tools is simple:
Allow anyone working on systems that process sensitive or risky data to consistently describe the types of data theyre handling and what that data is being used for.
Create CI rules or policies for how data can be used and enforce those in the CI pipeline to prevent code that might create risks or misuse data from ever reaching production.
Provide configurable tools to ensure respecting a users rights can be a feature of any system, such as data access, erasure, portability and retention.
Create runtime rules or policies for fine-grained, semantic enforcement, thereby ensuring that only the necessary data is shared with systems or people to perform a process.
The two key benefits yielded are (1) ensuring that software systems more easily comply with complex data privacy regulations that are already forcing change on the tech community, and (2) ensuring that the products we build more naturally respect the rights of users.
Over the last three years at Ethyca, weve been working hard with technical design partners and engineering teams at some of the worlds biggest tech companies to understand the root cause of privacy challenges and build the tools necessary to solve these from the ground up. Im excited that in the coming months well finally share the culmination of that work with the first public release of our open source privacy tools.
A Proposed Privacy Taxonomy
The foundation of those tools is a consistent understanding of types and uses of data, and so I want to share the first public release of our data taxonomy with you today.
Its purpose is to create an agreed-upon definition of types and categories of personal data. This is a vital first step in any ontological design as, in order for any privacy standard to be interoperable, we must first achieve a shared definition of what types of data there are.
Im eager to share this and excited to get any feedback that might improve this standard for every developer. I believe what follows forms the foundation of any realistic solution to privacy engineering.
The rest of this post breaks down our current thinking on what will be a freely available and extensible taxonomy: its components, hierarchy and syntax.
Objective of a Privacy Taxonomy
As stated briefly above and in my other posts, if the dev community is going to solve privacy, we need to agree on a standard definition language on which to base our understanding of systems, the risk they pose and our ability to codify healthy policies into them ultimately, an ontology for privacy (more on that in a future post).
The starting point for that is a definition of entities in a system: a taxonomy, the ability to describe what types of data we are handling and what were using them for. If we can make it easy for any dev to do this as part of their implementation process, we can start to bake privacy naturally into healthy software design and delivery processes.
So a lot rides on getting the dev community to standardize their way of describing privacy data and privacy-related data processes in their systems. The taxonomy that follows is our attempt to publicly start that process, and we want to encourage as many developers as possible to contribute their views so that we can collectively build better technology.
Accessing & Exploring the Taxonomy
This post marks the day were starting to release years of development work at Ethyca, as we had always intended, for the open source community. With that in mind, feel free to grab the taxonomy repo available below or use the codepen to explore the structure visually.
https://github.com/ethyca/privacy-taxonomy
or codepen here:
Privacy Taxonomy Research
Our goal at Ethyca was to conduct the detailed research necessary to provide the dev community with a first draft taxonomy robust enough to capture a comprehensive view of privacy, yet intuitive enough for any engineer to easily apply.
To achieve this, we evaluated existing privacy ontologies and their taxonomies, such as PrOnto and COPri v.2; international standards like ISO 19944; and contrasted with major data privacy regulations like the GDPR (the ICOs website is a helpful read for those curious), CCPA, LGPD and drafts of the Indian PDPB.
Early Decisions
Armed with this analysis and feedback from our technical design partners, weve been refining this taxonomy for over a year. We feel that its an early but confident first step in capturing everything you will need to describe the privacy behaviors and data types of your tech stack.
To achieve this, we made some early, opinionated and intentional decisions that Id love feedback on. So the taxonomy repo youll see here:
Supports all of the data types and concepts necessary to describe a system for the GDPR, CCPA and LGPD.
Supports the standards of ISO 19944;
Is extensible, so you can add categories of data or data processing definitions to suit your business;
Is intended to be semantic and allow a natural understanding of any label for any user.
Concepts & Conventions of the Taxonomy
Conceptually, the taxonomy is segmented in four groupings as follows:
1. Data Categories
Data Categories are a comprehensive hierarchy of labels to represent types of data in your systems. They can be coarse definitions such as User Provided Data or fine grained ones, such as User Provided Email Address. Well dig into this in a bit more detail shortly.
2. Data Uses
Data Uses are labels that describe how, or for what purposes, you are using the data. This branch of the taxonomy creates a structure for the most common uses of data in software applications. An example might be the use of data for payment processing or first party personalized advertising. These would both be data uses, ways in which your system uses data.
3. Data Subject Categories
Subjects is a slightly esoteric term, common in the privacy industry to represent the user type that is to say, the label applied to describe the provider or owner of the data. E.g., if you have an email address in your system, it might belong to an employee of the company, or to a customer. In this case, employees and customers are both subjects of the system. Under various privacy regulations, they are afforded rights over managing how their data is used and that may vary by the subject type, so the distinction between a patient in a medical records system and a customer in an e-commerce system is important.
4. Data Qualifiers
Data Qualifiers provide added context as to the degree of identification and therefore, potential risk using the data might pose relative to identifying an individual. A simple way to think about this is a spectrum: on one end is completely anonymous data, i.e. it is impossible to identify an individual from it, and on the other end is data that specifically identifies an individual. Along this spectrum are various labels that denote the degree of identification that a given data might provide.
Writing Conventions
We worked through various potential syntaxes to ensure its as easy as possible to read and write in plain English. Ultimately, dot notation lends itself most appropriately to writing statements that are concise and easy to understand. So the branch structure is dot notation and youll see some of the end nodes are complex terms that use snake case for clarity.
As such, if you were attempting to use the taxonomy of data categories to label, for example, an email address, the resulting hierarchical notation would look like:
user.provided.identifiable.contact.email
As you can see, its pretty easy to deduce from this that its user-provided data, it identifies them and it is considered contact information more specifically, an email address.

The design of these hierarchical structures is intended to allow any dev implementing this to type out the classification to a level of specificity that suits their needs. If I take the above example, my team and I might decide that were satisfied if we know its identifiable data about a user, which would look like:
user.provided.identifiable
Or labeling it with slightly more specificity as contact data:
user.provided.identifiable.contact
Taxonomy Structure
As stated, the objective with releasing the taxonomy now is to discuss, debate and over time, iteratively improve the taxonomy so that it can cater to most common scenarios for devs and data teams in describing systems. Here well delve into the current structure and our rationale for their present state.
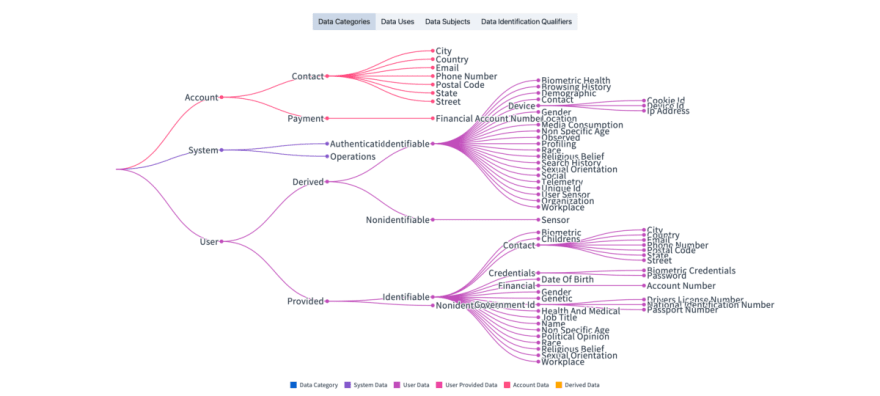
Data Categories
As you can see from the dot notation example above and the taxonomy visualizer tool in the header, Data Categories are classified into primitive categories with a hierarchy of branches and nodes that allow for degrees of precision when classifying data.
Heres a breakdown of that structure:
Data Categories Top Level
There are three top-level categories:
account: Data related to a system account.
system: Data unique to, and under control of the system.
user: Data related to the user of the system, either provided directly or derived based on their usage.
In defining these, we looked at the cross-labeling implications of data types such as an email address, which may be both account data and user data. This is a logical multi-label assignment so that you can manage this data for both purposes, or perhaps create exclusionary rules related to its use.
TLDR: When considering and testing labeling extensively, we found that with three clear primitives you could elegantly construct a series of labels that covered the broadest possible data types while limiting the number of terms needed to do so.
Data Categories Second Level
For each top-level node, there are multiple branches that provide richer context. You will see for the first two, account and system, these are limited, where the user node provides subclasses suitable to assist in detailed personal data management.
account.contact: Contact data related to a system account.
account.payment: Payment data related to a system account.
system.authentication: Data used to manage access to the system.
system.operations: Data used for system operations.
user.derived: Data derived from user provided data or as a result of user actions in the system.
user.provided: Data provided or created directly by a user of the system.
Most of these are likely self-evident. Of note here are the derived and provided labels, as these respectively describe where data was derived by the system through observation or inference, versus explicitly provided by a user.
Data Categories Third Level
As you can see, the hierarchy supports simple labels or, where necessary, very precise and fine-grained annotations. Its easiest from here for you to dive in and play with the classifications yourself. However, well quickly look at level three of the user branch specifically, where you have branches from derived and provided:
You can see this is split into identifiable and non-identifiable data:
user.derived.identifiable: Derived data that is linked to, or identifies a user.
user.derived.nonidentifiable: Non-user identifiable data derived related to a user as a result of user actions in the system.
And a similar split applies to provided, as shown below.
user.provided.identifiable: Data provided or created directly by a user that is linked to or identifies a user.
user.provided.nonidentifiable: Data provided or created directly by a user that is not identifiable.
Data Uses
Similar to Data Categories, for Data Use, weve attempted to capture the widest variety of data use cases with the briefest hierarchy we can. In addition to this, weve captured all of the use cases described by ISO 19944 and GDPR to ensure that a single taxonomy can describe data uses across data privacy frameworks.
Youll see if you use the taxonomy explorer in the header that this currently breaks down as follows:
Data Uses Top Level
At present there are seven top-level nodes to the use categories taxonomy branch. We think this still needs work and are continuing to optimize. However, today they are:
provide: Provide, in the context of providing a product or service.
improve: Improve, similarly relating to the product or service.
personalize: Personalization of the product or service.
advertising: Marketing, Advertising or Promotion.
third_party_sharing: Sharing data with a third party vendor or processor.
collect: Collect data with no currently specified use (you shouldnt do this but it seems necessary to encompass some poor, non-privacy appropriate, legacy processes).
train_ai_system: Train an AI System.
Data Uses Second Level
From here, its likely quicker to explore the second level data use categories yourself. However, its worth noting that weve attempted to capture the most common constructs that create privacy risks. For example:
advertising.third_party.personalized: Specifies data received from a third party for the purpose of personalization of advertising to a user or group of users.
third_party_sharing.personalized_advertising: Sharing of data collected by the system with a third party for their use in personalized advertising.
These two examples show really important distinctions of use. The first is where your product is performing personalized marketing/advertising by receiving and processing data from a third party. Whereas the second example declares that your system is sharing data with a third party for their use in advertising very different uses and privacy implications!
Data Uses Final Word
As a final word on data use categories, I stated at the top of this post that weve designed this with extensibility in mind, and data uses are a really effective example of this. Every business or software system is different and as such, youre likely to have different or industry specific uses for your system.
The objective therefore with data uses is to create a simple framework to generate a clear hierarchy of classifications, so that you can quickly extend this for your use, whether its medical data use or some other sensitive process.
Finally, if you look at the repository history, youll see weve been iterating on structure from snake_case to dot notation and also hierarchy of terms. Im hopeful that well continue to do this constantly with feedback from devs implementing this to ensure it satisfies real-world use cases.
Data Subjects
This is likely the easiest group of the taxonomy to understand. At present its a flat structure with no hierarchy and represents the various types of users (aka subjects) that may be participants in your system. These could be users, customers, employees, patients, voters, etc.
You might ask why weve done this. The benefit of this specificity is future-proofing. As privacy regulations evolve we expect that certain groups of users data will be managed differently. The ability to assign one or multiple user types to your data assures that in future you can build policies and enforcements around data for any business or legal requirement. So you might decide that today you treat employee and customer data the same way, but you will have the flexibility to change retention policies on employee data in the future. As with everything in the taxonomy, you can extend this to support specific business cases. This flexibility means that a thoughtful system need not be fragile, rendered unworkable as soon as compliance requirements evolve. To the contrary: the ontology enables the system to be nimble, a vital quality in a landscape as dynamic as modern data and privacy compliance needs.
Subject categories are explicit in their meaning today, so:
anonymous_user: An individual who is truly unknown/anonymous to the system.
citizen_voter: An individual who is a citizen of a nation or state and may be a voter in a state sponsored voting system.
commuter: An individual in transit on any means of transportation where their location may be monitored.
consultant: An individual external service provider to the organization..
customer: An individual who has purchased products or services from the organization.
employee: An individual who is an employee of the organization.
job_applicant: An individual who is in the job application process of an organization, past or present.
next_of_kin: An individual identified as a legal point of contact for another category of individual in the system.
passenger: An individual traveling on transportation provided by the organization.
patient: An individual identified for the purpose of medical or health procedures.
prospect: An individual identified for the purpose of sales and marketing.
shareholder: An individual identified as an owner or shareholder of an organization.
supplier_vendor: An individual or organization providing goods or services to the organization.
trainee: An individual receiving training or tutoring.
visitor: An individual visiting a location of an organization.
Data Qualifiers
Data Qualifiers describe the degree of identification of the given data. Think of this as a spectrum: on one end is completely anonymous data, i.e. it is impossible to identify an individual from it, and on the other end is data that specifically identifies an individual.
Along this spectrum are labels that describe the degree of identification that a given data might provide, such as:
identified: Data that directly identifies an individual.
pseudonymized: Data which has been de-identified (by removing/replacing all identifiers) but used with other data may re-identify an individual.
unlinked_pseudonymized: Data which has been de-identified (by removing/replacing all identifiers) where linkages have also been replaced/broken such that the individual cannot be re-identified.
anonymized: Data which has been unlinked and for which attributes have been modified to assure confidence that the person cannot be re-identified with this data or in combination with other data.
aggregated: Statistical data that does not contain individual data and/or has been combined with sufficient data from multiple persons that no individual is identifiable.
Conclusion
In this post Ive proposed a first draft of a privacy taxonomy, one that underpins much of the thinking we do at Ethyca. What were releasing today is just an up-down taxonomy. However, this precedes an entire ontology that provides a simple grammar to describe complex data flows and privacy-related behaviors in a software system. This has been at the heart of our work for nearly three years now.
Im excited to finally start sharing that work publicly with the community, and I encourage feedback, debate and changes. By having these conversations, we can build a better standard and the tools necessary to make this easy for every dev to implement.
Over the coming weeks well be releasing more details of our work in this space and the benefits created by these tools. We welcome your feedback, participation and contribution.
If youd like to chat about anything here you can get me on Twitter, @cillian, or feel free to comment here.
Original Link: https://dev.to/cillian/devtools-for-data-privacy-step-1-privacy-taxonomy-v10-2fpp
Dev To
More About this Source Visit Dev To