
An Interest In:
Web News this Week
- April 24, 2024
- April 23, 2024
- April 22, 2024
- April 21, 2024
- April 20, 2024
- April 19, 2024
- April 18, 2024
Some of Our Sources
- Slashdot
- Techcrunch
- Simplebits
- TutsPlus - Code
- Web Designer Wall
- Six Revisions
- FanExtra - PSD
- Fudge Graphics
- Reencoded
- Web Resource Source
Help Webnuz
Referal links:
Product Developers guide to customizing data for AI Part 1: Combine dataframes
TLDR
When working with AI, its common to have too much data; especially when training models. In this guide, well cover how to look at relationships made when combining dataframes using concat.
Outline
- Introduction
- Before we begin
- Relationships
- Fold
- Concat
- Clean up
- Conclusion
Introduction
Welcome to the 1st part of the Product developers guide to customizing data in AI. In this series, well go over intermediate concepts and run through examples using Pandas. Well start by looking at a common dataset about email information and progressively tailor information. By the end of the series, youll be ready to tackle designing machine learning datasets for training machine learning models.
Before we begin
In this guide, well be using the email content dataset along with Google Collab. Well import the dataset, and chop it down. If you need a refresher on anything mentioned above, please refer back to part 1 of the beginners guide.
 email_content dataframe
email_content dataframeRelationships
To understand how to customize data in AI, we need to dive deeper into relations within set theory. To start off, well look at the 2 most basic relationships, unions and intersections. Think of multiple datasets, and within each, there may or may not be duplicate values that are mutual to another dataframe.
Union
Unions are useful for a general outlook of all the values removing duplicates.
For a union, this is a combination of all the values, and returns all values with the mutual values listed exactly once.
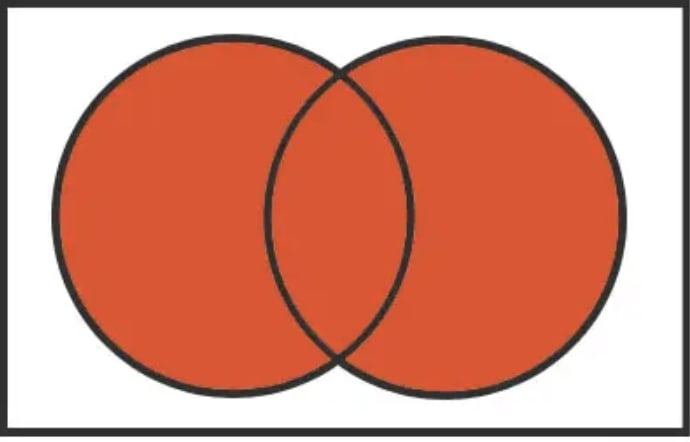 The area of all the sets (Source: mychartguide)
The area of all the sets (Source: mychartguide)Intersection
Intersections are useful for finding values that are found in all the dataset
But for an intersection, it takes the combination of all the values, and only returns the mutual values.
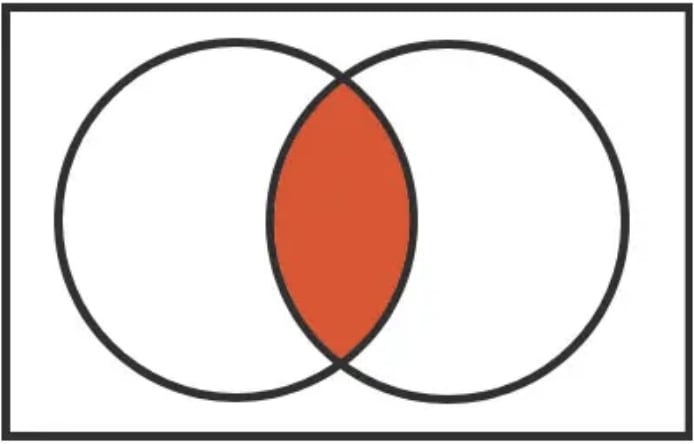 The overlapping area of two sets (Source: mychartguide)
The overlapping area of two sets (Source: mychartguide)Fold
To start off lets follow a common practice among data scientists to fold the data. This is especially useful for training machine learning models as it breaks down the data for training, testing, and validation sets. Lets start with a fold of 2 parts, or a half on our email_content dataset. Imagine the dataset as a piece of paper. After folding the piece of paper in half, it breaks it down into exactly 2 pieces.
 Two ways to fold: Hotdog or Hamburger (Source: Elasticity)
Two ways to fold: Hotdog or Hamburger (Source: Elasticity)Hotdog Style
One way to fold paper is hotdog style, by folding horizontally through the center. In Pandas, this is accomplished by taking the maximum length of the rows and dividing it into segments. For our dataset, lets take an arbitrary number to section it by. There are other alternatives, but iloc and loc are the simplest and covered in the beginners guide.
 Fold it using into rows 0 to 60 and rows 50 to 100
Fold it using into rows 0 to 60 and rows 50 to 100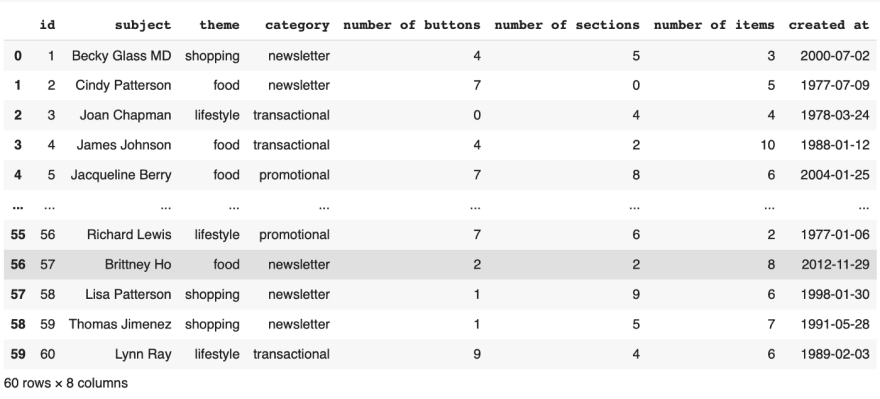 1st dataframe is from row 1 to 60
1st dataframe is from row 1 to 60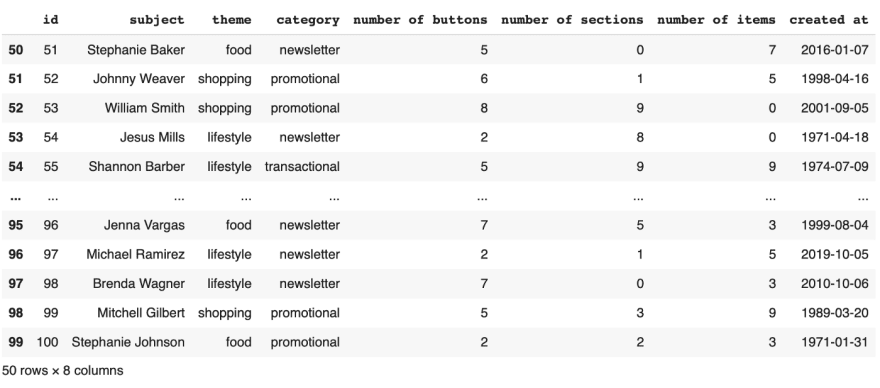 2nd dataframe is from row 51 to 100
2nd dataframe is from row 51 to 100Hamburger Style
Alternatively, we can fold it hamburger style, by folding vertically through the center. In Pandas, this is done by splitting the columns into multiple parts using loc to select specific columns. Here we have chosen to split the email columns based on its relevance into 2 parts. Email content is broken down into email information readable for humans, and email information readable by a machine.
 Include all the rows, but only specific columns in each
Include all the rows, but only specific columns in each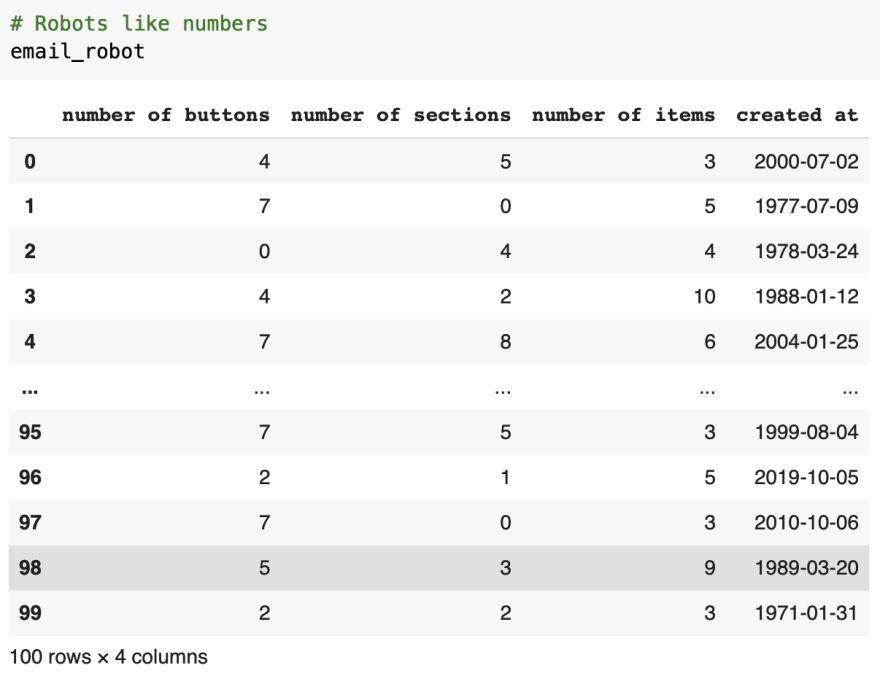 1st dataframe contains data useful for a machine
1st dataframe contains data useful for a machine 2nd dataframe contents are easily understandable by a human
2nd dataframe contents are easily understandable by a humanConcat
Using the folded data, lets put them together using concat. Concat is very versatile and has multiple functionality when performing a union or intersection operation on multiple datasets.
Hotdog
Lets start by applying concat on the folded hotdog style datasets. Using concat, we union the datasets and get back the original. By default, concat is a union operation.
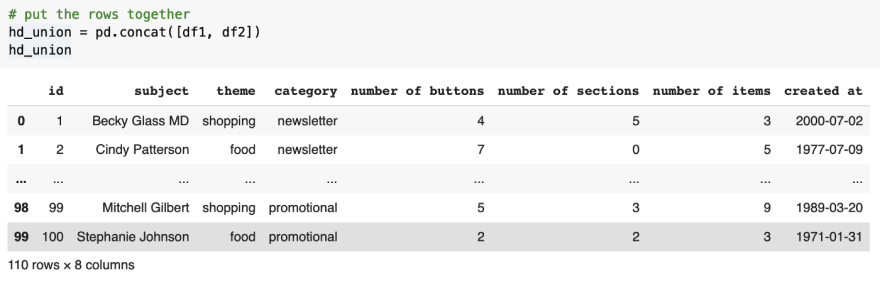 Use concat to get the union of two datasets resulting in 50 + 60 (110) rows
Use concat to get the union of two datasets resulting in 50 + 60 (110) rowsThen we apply concat using the intersection, we get the overlapping indexes. To get the best result, we use axis=1 along the columns.

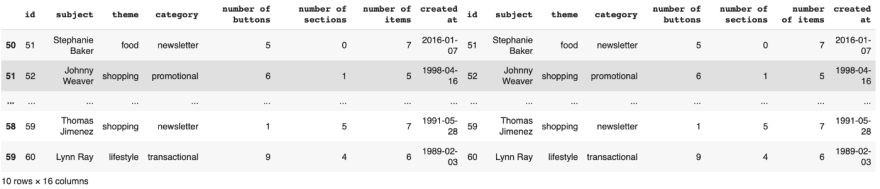 Use concat to get the intersection of two datasets, rows 5160
Use concat to get the intersection of two datasets, rows 5160Hamburger
For hamburger style, the columns dont match and performing a union gives a less desirable result filled with null values. We also use axis=1 again since we want to see the columns.
 Combine all the values in both columns
Combine all the values in both columnsThen for an intersection, we want to look at the intersection to grab the overlapping rows.

 The created at column is shared between both dataframes
The created at column is shared between both dataframesClean Up
A lot of the data is duplicated, such as column names or row entries. This is because unlike sets, which cannot contain duplicates, a dataframe is allowed to have as many duplicate values. Luckily, Pandas has the drop_duplicates function to convert our results into its set theory result, while remaining as a dataframe.
Applying drop_duplicates to the union, returns all values exactly once. Thus, returning the original email_content dataframe or set union.
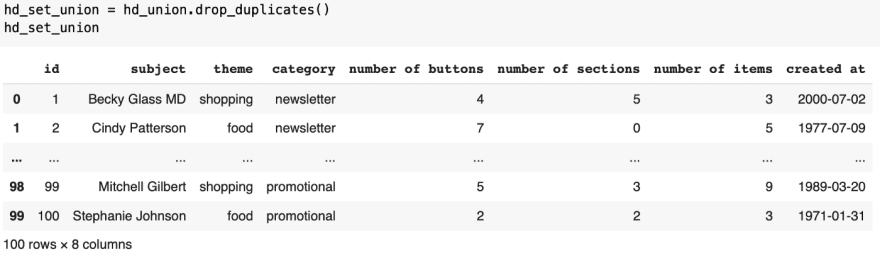 Set union, results in the original dataset
Set union, results in the original datasetApplying drop_duplicates to the intersection, returns the overlapping values exactly once. Thus, the result is the set intersection
 Set intersection, results in the created_at column
Set intersection, results in the created_at columnConclusion
Weve established a point to begin diving into relationships between datasets, a crucial component for customizing data in machine learning. We covered folding, a technique used immensely in data science to split data, and concat, to combine data by finding matching values to create unions and intersections. In the rest of this series, well be looking at how we can remove extras by using join and merge instead of drop_duplicates and establish relationships based on exclusion rather than inclusion.
Original Link: https://dev.to/mage_ai/product-developers-guide-to-customizing-data-for-ai-part-1-combine-dataframes-59j6
Dev To
More About this Source Visit Dev To