
An Interest In:
Web News this Week
- April 23, 2024
- April 22, 2024
- April 21, 2024
- April 20, 2024
- April 19, 2024
- April 18, 2024
- April 17, 2024
Some of Our Sources
- Pearsonified
- Six Revisions
- Creative Curio
- Naldz Graphics
- My Ink Blog
- CSS Globe
- Web Resource Source
- Codrops
- Dev To
- Hashedout
Help Webnuz
Referal links:
Why should we learn and use FP?
Photo by Xavi Cabrera on Unsplash.
Before trying and adopting a new paradigm, it is only legitimate to ask ourselves this question: why should we spend some of our precious time learning this thing?
Allow me to present my list of pros and cons of doing FP when writing software.
Table of contents
- Composition over inheritance
- Extensibility
- Testability
- Type-based reasoning
- Concurrency and parallelism
- Debugging
- Adoption rising among libraries and frameworks
- Something new to learn
- It's hard to get on board
- Some languages are more adapted than others
Composition over inheritance
One of the problems with inheritance is that it leads to less and less code reusability and flexibility. To quote Joe Armstrong, author of the Coders at Work book:
I think the lack of reusability comes in object-oriented languages, not functional languages. Because the problem with object-oriented languages is theyve got all this implicit environment that they carry around with them. You wanted a banana but what you got was a gorilla holding the banana and the entire jungle.
(emphasis added)
Let's take a case study involving animals.
Inheritance approach
abstract class Animal { constructor(private readonly name: string) {} eat() {}}abstract class WalkingAnimal extends Animal { walk() {}}abstract class SwimmingAnimal extends Animal { swim() {}}class Dog extends WalkingAnimal { constructor() { super('dog') } bark() {}}class Dolphin extends SwimmingAnimal { constructor() { super('dolphin') } playWithPufferFish() {}}Composition approach
const withName = (name: string) => ({ name })const canEat = { eat: () => {} }const canWalk = { walk: () => {} }const canSwim = { swim: () => {} }const canBark = { bark: () => {} }const canPlayWithPufferFish = { playWithPufferFish: () => {} }const createDog = () => ({ ...withName('dog'), ...canEat, ...canWalk, ...canBark})const createDolphin = () => ({ ...withName('dolphin'), ...canEat, ...canSwim, ...canPlayWithPufferFish})What if we want to have an animal that can bark and swim?
We can't use the inheritance approach without duplicating some code. However, with the composition approach, such animal becomes trivial to implement: the existing code can be reused without any duplication. Furthermore, having granular behaviors allows for more flexibility when composing these behaviors together, and creating new types of animals.
const createSeaGoodBoy = () => ({ ...withName('good boy of the seven seas'), ...canEat, ...canBark, ...canSwim})Functional Programming favors composition over inheritance. I am not saying we can't do composition with OOP (in fact we can use interfaces and delegation for that), but it is more tempting to use inheritance, which leads to the problems we just talked about.
Extensibility
What if you want to add more functionality to an existing type? For instance in JavaScript, adding new behaviors to the Array or String data types.
Well, you could do this:
Array.prototype.getEvenNumbers = function getEvenNumbers() { return this.filter(_ => _ % 2 === 0)}String.prototype.containsFoo = function containsFoo() { return /foo/i.test(this)}const res0 = [1, 2, 3, 4, 5].getEvenNumbers() // [2, 4]const res1 = 'Hello, World!'.containsFoo() // falseBut I wouldn't recommend it, as it could alter the behavior of other scripts using the same scope. Plus, in the majority of languages, it is impossible to modify existing classes anyway, whether they are coming from the standard library or third-party libraries.
In FP, the data and the functions are 2 distinct entities. In fact, functions take data (and additional arguments if needed) as input, then return data as output.
This is in contrast to OOP where data (properties) are put together with functions (methods) under the same entity (object).
Separating data and functions allows us to add new functionalities quite easily: we simply have to add a function that takes the data as one of its arguments.
const getEvenNumbers = (ns: number[]): number[] => ns.filter(_ => _ % 2 === 0)const containsFoo = (s: string): boolean => /foo/i.test(s)const res0 = getEvenNumbers([1, 2, 3, 4, 5]) // [2, 4]const res1 = containsFoo('Hello, World!') // falseconst res2 = getEvenNumbers(['foo', 'bar', 'baz']) // compiler errorThis pattern may be known as the visitor pattern to some OOP developers.
In some languages such as Scala, there are techniques used to keep a fluent API*, despite separating the data from the functions.
In F# for example, this would be the pipeline operator. In fact, as this approach is becoming more and more popular, there is a pipeline operator proposal for JavaScript in active development (it actually reached stage 2 quite recently, which means it's serious business).
* A fluent API is a way to chain function calls on some data, e.g. myData.f().g().h() or myData |> f |> g |> h, instead of h(g(f(myData))).
Testability
One of the key concepts of FP is isolating side-effects and composing pure functions. We'll see what these concepts are in the next articles of this series, but essentially, this allows us to easily write unit tests to cover all the possible cases of our functions.
Let's take a simple example: we have a module that, given some threshold, allows to log a message or not (i.e. logs are sampled).
An initial implementation could look like this:
const logThreshold = 0.05 // 5% samplingexport function canLog(): boolean { return Math.random() <= logThreshold}And this is how we could write unit tests:
describe('canLog', () => { const originalMathRandom = Math.random afterEach(() => Math.random = originalMathRandom) it('should allow logging', () => { Math.random = () => 0.01 expect(canLog()).toBe(true) }) it('should not allow logging', () => { Math.random = () => 0.5 expect(canLog()).toBe(false) })})It works, but we had to perform extra steps to make sure to:
- Mock the
Math.randomfunction, so it always returns the values we want in order to test the behavior of the module in a consistent way, - and restore the original value of
Math.random, to avoid breaking other unit tests based on this global function.
Here, the canLog function is impure as it's performing a side-effect: calling the global Math.random function that returns a random number. In order to prevent this, we can do the following:
export function canLog(rng: () => number): boolean { return rng() <= logThreshold}Now writing unit tests is actually easier and straightforward:
describe('canLog', () => { it('should allow logging', () => { expect(canLog(() => 0.01)).toBe(true) }) it('should not allow logging', () => { expect(canLog(() => 0.5)).toBe(false) })})Type-based reasoning
This applies only to programming languages that provide a static type system, which is often the case for languages that have a compiler, in my experience.
Type-based reasoning is the ability to understand what the program does only by reading the types and function signatures. One does not have to read and understand the actual implementation in order to understand what the program does.
This is quite a powerful feature, and I would say it's mandatory for doing Domain-Driven Design, since domain-specific rules can be encoded at the type level of a program. I actually wrote a series about Domain-Driven Design in TypeScript, feel free to have a look.
Let's take an example.
declare function isNumber(n: unknown): n is numberdeclare function isInteger(n: number): n is Integerdeclare function isStrictlyPositiveInteger( n: Integer): n is StrictlyPositiveIntegerdeclare function isOddInteger( n: StrictlyPositiveInteger): n is OddIntegerdeclare function oddIntegersSum(ns: OddInteger[]): OddIntegerdeclare function program( values: unknown[]): OddInteger | undefinedHere, I'm only defining the function signatures. There is no actual runtime code written anywhere and yet, we can understand what is going on, or at least have a good idea of what the program does.
It looks like the program takes a list of unknown values, and it returns either a single OddInteger, or undefined (probably if there's no odd integer in the list of random values provided). We can see among the function signatures above that this program should filter only the odd integers from the list, then sum them to return a single OddInteger, if odd integers are available.
The actual implementation of program could be different, for example it could simply return the first OddInteger of the list, instead of their sum. But at least we have some degree of understanding about this program, only by reading the types. Of course, having a meaningful name such as getOddIntegersSum or getFirstOddInteger instead of program would also help a lot.
And since these functions are pure, we won't be surprised by a "HTTP" call or some database operation in the middle of the implementation. If such an event should happen, then it must be "documented" in the types used in the function signature. We'll certainly talk about this in more details in the article about side-effects.
Concurrency and parallelism
Since data is immutable in a program written in FP, the entire class of problems related to race conditions (from the imperative world) don't apply. This leaves the developers with fewer error cases to check if the program doesn't work as expected.
Adapting a single-threaded program into a multi-threaded one should be way easier to do with FP than with any form of imperative programming.
Debugging
Debugging code becomes easier. Finding a bug is much more direct as you can clearly define the inputs and check the outputs of the functions that compose the program.
There is no shared state, no global / external variables used in the functions. If a piece of the software doesn't behave as expected, then we can isolate it and test it with different inputs, until eventually finding the unexpected behavior / output.
Adoption rising among libraries and frameworks
This is a trend I've mostly noticed in the web frontend world. But I think it's also spreading in the mobile and backend world, with languages (or language's features) such as Kotlin, Swift, and Rust lately.
React added hooks a few years ago, which allow building complex apps relying only on functional components.
The pipeline operator proposal has recently reached the stage 2, and there are more undergoing FP-related proposals, such as:
- Immutable records and tuples (stage 2)
- Pattern matching (stage 1)
- Do expressions (stage 1)
- Partial application (stage 1)
- First-class protocols (stage 1)
In the State of JavaScript 2020, to the question "What do you feel is currently missing from JavaScript?", we can see some FP-related answers at the top:
- Pattern Matching
- Pipe Operator
- functions (not sure what that means?)
- Immutable Data Structure
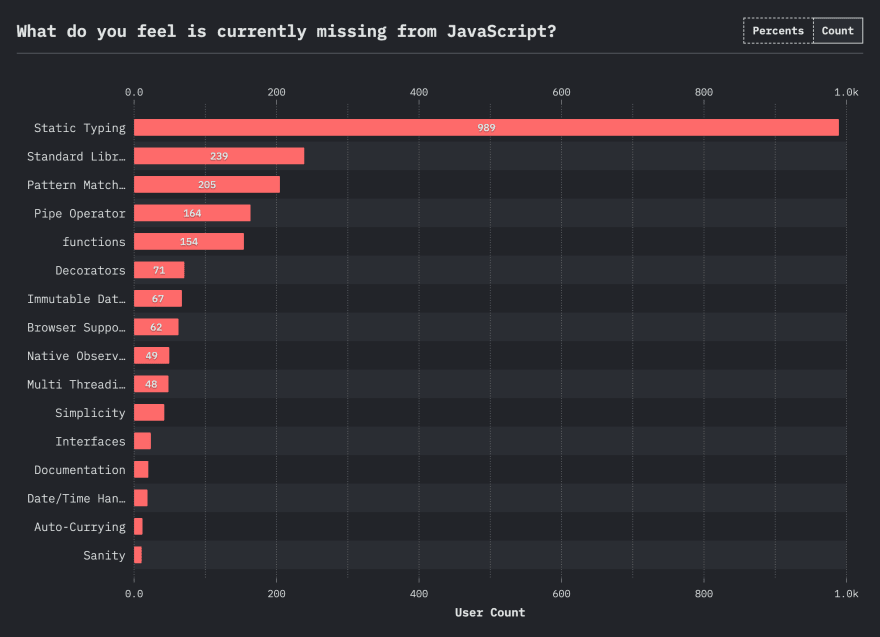
All this tends to show that FP is becoming more and more ubiquitous in our lives, so we might as well learn it to understand the libraries, frameworks and language features that are already there, or coming in the near future.
Something new to learn
I don't know about you, but one of the most exciting things in being a developer is that there's always something new to learn.
I love learning, and if what I'm learning is interesting and can make me a better developer, then sign me in!
I think it's valuable to learn this paradigm, even if you don't intend to use it. It should make you more critical about your own code, and hopefully improve it to make it more readable, testable, extendable.
One does not have to embrace this paradigm at 100%, but there are some very powerful concepts and tools that are worth the time spent learning them.
It's hard to get on board
As I mentioned in the introduction, there's a big entry barrier when trying to learn Functional Programming. The vocabulary/jargon can be scary at first.
I'm writing this series to make it easier for people to discover this world.
Some languages are more adapted than others
I've had the opportunity to write FP code in TypeScript, Elm, and Scala for the past years. I've also read blog posts and articles that shared examples in F#, PureScript, and Haskell.
I must say that writing FP code feels more natural with languages that have some degree of built-in support for FP.
It is still possible to write FP code in languages that don't offer all these built-in concepts and tools, but it requires the developers to use some boilerplate to mimic the same tools. I'll give you 2 examples in TypeScript.
The first one is about algebraic data types (ADTs). We'll cover this topic in more details later in this series, but basically here's how we can define a sum type in TypeScript and in Haskell:
// data typetype Option<A> = | { readonly type: 'None' } | { readonly type: 'Some', readonly value: A }// constructorsconst none: Option<never> = { type: 'None' }function some<A>(value: A): Option<A> { return { type: 'Some', value }}// matcher / foldexport function fold<A, R>( onNone: () => R, onSome: (value: A) => R, fa: Option<A>): R => { switch (fa.type) { case 'None': return onNone() case 'Some': return onSome(fa.value) } }}data Option a = None | Some aAs you can see, there's much more boilerplate in the TypeScript version, since ADTs are not built-into the language, so we have to define the constructors and matcher functions.
Another example is the ability to implement data structures. Again, we'll see what these structures are much later in this series. TypeScript doesn't support higher-kinded types (HKTs), but some people have tried emulating HKTs with the current type-level features of the language.
Here's how we can implement the Functor data structure using fp-ts, one of the most popular TypeScript libraries to write FP code:
import { HKT, Kind, URIS } from 'fp-ts/lib/HKT'export interface Functor<F> { readonly URI: F readonly map: <A, B>(f: (a: A) => B, fa: HKT<F, A>) => HKT<F, B>}export interface Functor1<F extends URIS> { readonly URI: F readonly map: <A, B>(f: (a: A) => B, fa: Kind<F, A>) => Kind<F, B>}And here's how we can do the same in Haskell, where data structures are built-into the language using type classes:
class Functor f where fmap :: (a -> b) -> f a -> f b (Actually we don't have to define Functor as it's already available in Haskell)
And finally, here's how we can create an instance of these data structures, for the type Option<A> we defined earlier:
const URI = 'Option'type URI = typeof URIconst map = <A, B>(f: (a: A) => B, fa: Option<A>): Option<B> => isNone(fa) ? none : some(f(fa.value))const OptionFunctor: Functor1<URI> = { URI, map }instance Functor Option where fmap _ None = None fmap f (Some a) = Some (f a)You don't have to understand everything in these examples, as I'll explain these concepts later in the series. The point is that there is way less code with Haskell than with TypeScript.
Nonetheless, it's still possible to write FP code in both, it just feels more "natural" with Haskell because the language has better "native" support, it doesn't require any library or emulation to achieve the same results.
So, here we are! Thank you for reading this far. Hopefully the pros outperform the cons to you, and you are willing to give FP a try. As of the next articles, we'll dive into the FP concepts and tools I've been mentioning since the introduction.
Feel free to share your pros and cons in the comments!
Original Link: https://dev.to/ruizb/why-should-we-learn-and-use-fp-5ce5
Dev To
More About this Source Visit Dev To