
An Interest In:
Web News this Week
- April 24, 2024
- April 23, 2024
- April 22, 2024
- April 21, 2024
- April 20, 2024
- April 19, 2024
- April 18, 2024
Some of Our Sources
- Engadget
- Mashable
- Techcrunch
- Technology Review
- Joshua Blankenship
- Spoon Graphics
- Spyre Studios
- Android Headlines
- Dev To
- Hashedout
Help Webnuz
Referal links:
Create An IMDB Web Scraper Using JS
Web scrapping is the process of using bot to get data from a specific website, unlike screen scraping, which only copies pixels of screen, the web scraping extracts the underlying HTML data of a link of a website, including the data from the database that the link provides.So, is this technology using legal? The short answer is yes.
This thing may be a challenging task if you try to scrap data from a dynamic webpage. But as a beginner, we will try a static page for scraping.
Difference Between A Scraper and A Crawler:

A crawler simply goes every link and page of the website rather than a subset of the page. On the other hand, web scraper focuses on a specific set of data of a website. So in short, Web scraping has a much more focused approach and purpose while Web crawler will scan and extract all data of a website
What Will We Extract ?
so, our victim page is IMDB.com. Now you are thinking, isn't IMDB a dynamic webpage? yes it is, but we are not scraping the whole website, we are just extract a specific product link's data. Like this link IMDB.com/top-movies
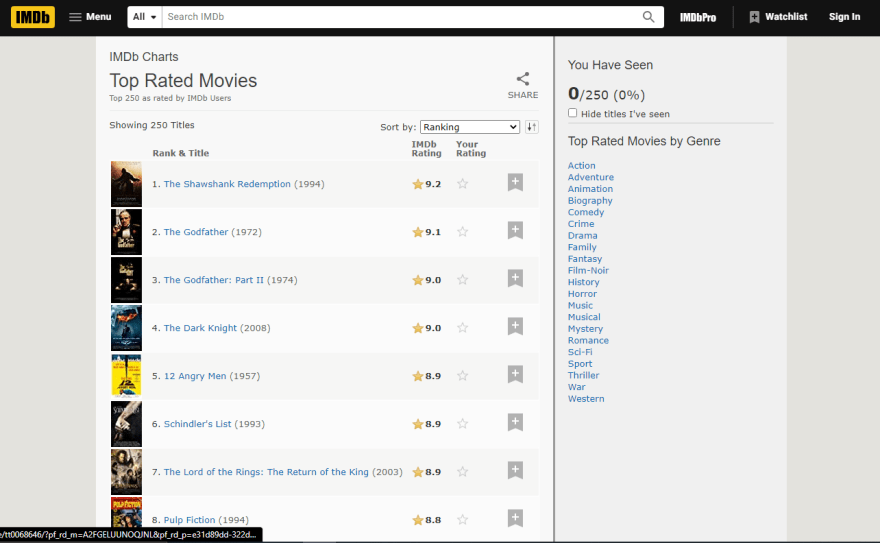
IMDB top movies page which shows the top 250 rated movies
So, our goal is to extract the movie names and the ratings and save this to a TXT or CSV file.
Step 1. The setup :
So, for scraping, we need three packages to start the project. Just paste the code below and install the packages into your node_modules directory.
npm i cheerio fs requestcheerio helps us to parse HTML in nodeJS. It's an affective and powerful technology used in webscraping in sever side implementation.
The FS module should be pre-installed in the node_modules if
you previously used npm init command.
Step 2. Requesting To The WEB :
We will use the request package to send and receive requests to a website.First of all, we will import all the three previously install packages using the require("packagename") syntax.
const request = require("request");const cheerio = require('cheerio');const fs = require("fs");And then, we will define a new constant URL to store our website link.
Now we will create a request function. A request function which assigns 2 parameters. One is the URL you want to send request, the other is like a callback function with three parameters : error , response and body.
const url = "https://www.imdb.com/chart/top/?ref_=nv_mv_250";// website URL for sending requestrequest(url , (err , res , body) => { if (err) console.log(err) // if something gets wrong else { console.log("request sent successfully ! ") }}) So, if the URL is broken / invalid or the website server gave a "404 error" we should return err using the conditional handling method. And if you see the message in the line, that means that your request is successful .
Now we have to use the body to extract the data. so We create another function named as parseBody with a single parameter for parsing the body.
Here's the request code :
const url = "https://www.imdb.com/chart/top/?ref_=nv_mv_250";// website URL for sending requestrequest(url , (err , res , body) => { if (err) console.log(err) // if something gets wrong else { parseBody(body); }}) 3. Parsing the Body :
Now, the fun part begins. The parsing or extracting the inner data from the HTML code we got from the request. We will be using cheerio to parse the HTML.
In this Blog, we will use only the basics of the cheerio package. If you want to know in depth. visit cheerio.org.
Lets create the parseBody function to play with the html body.
function parseBody(body) { const $ = cheerio.load(body) return $.html() // return the whole html body of the page}Here in parseBody, we load the request body to the cheerio module using the .load function.
4. Inspecting The Element You Want To Extract :
Go to IMDB and open the inspect tab. now navigate the HTML element you want to extract. Here, we are going to get the movie name including the ratings.
We will select the item of the class attributes.
so, back to the code :
function parseBody(body , callback) { const $ = cheerio.load(body) const movieName = $("tbody.lister-list").find("td.titleColumn > a").text()return movieName}cheerio's selector is something similiar to jquery. You can put the class name, ID , and also other attributes.
This will return all the text elements where their className included titleColumn. We did it like a charm, but the names are returned all-together. Like this : 
But we don't want this, we want it to create multiple objects that contain the value of the titleName and put it in an array.
To do this, we have to use the .each method of the cheerio package. It simply do a loop with the same name of the elements,
Here the syntax:
$("element").each(function(index) {$("child element")});so , lets put the each method to our code:
function parseBody(body, callback) { const $ = cheerio.load(body); const movieName = $("tbody.lister-list > tr").each(function(index) { const movie = { name : $(this).find("td.titleColumn > a").text() } console.log(movie) })}Now, it will do a loop and return all the td element and put this on an object that will return later.
The result is : 
Now, lets put the rating with and push the objects to a specific variable.
The final code would be :
const request = require("request");const cheerio = require("cheerio");const fs = require("fs");// importing the modulesconst url = "https://www.imdb.com/chart/top/?ref_=nv_mv_250";// the url we want to scraprequest(url, (err, res, body) => { if (err) console.log(err); else { parseBody(body); // calls the function with body }}); // sending request to the url or the webpagefunction parseBody(body) { const $ = cheerio.load(body); // cheerio loads the HTML body let array = []; $("tbody.lister-list > tr").each(function (index) { const movie = { name: $(this).find("td.titleColumn > a").text(), // the name of the movie rating: $(this).find("td.ratingColumn > strong").text(), // the rating of the movie }; array.push(movie); }); console.log(array);} result would be : 
To remove the 150 more items... (that will show at the end), just simply replace the console.log(array) to :
console.dir(array , {maxArrayLength : null})Thank you :) :)
Original Link: https://dev.to/labib/create-an-imdb-web-scraper-using-js-3k0f
Dev To
More About this Source Visit Dev To