
An Interest In:
Web News this Week
- April 20, 2024
- April 19, 2024
- April 18, 2024
- April 17, 2024
- April 16, 2024
- April 15, 2024
- April 14, 2024
Some of Our Sources
- Slashdot
- Simplebits
- TutsPlus - Code
- Pearsonified
- TutsPlus - Design
- Noupe
- Wal You
- Design Modo
- Android Headlines
- Hashedout
Help Webnuz
Referal links:
The Ultimate Guide to Web Scraping with Node.js
What is web scraping?
It involves automating the task of collecting information from websites.
There are a lot of use cases for web scraping you might want to collect prices from various e-commerce sites for a price comparison site. Or perhaps you need flight times and hotel listings for a travel site. Maybe you want to collect emails from various directories for sales leads, Or you could even be wanting to build a search engine like Google!
Getting started with web scraping is easy, and the process can be broken down into two main parts:
- acquiring the data using an HTML request library or a headless browser(maybe we will check this out in another post),
- and parsing the data to get the exact information you want.
This guide will walk you through the process with the popular Node.js request-promise module, CheerioJS, and Puppeteer. Working through the examples in this post, we will learn all the tips and tricks you need to become a pro at gathering any data you need with Node.js!
We will be gathering a list of all the names and birthdays of Indian presidents from Wikipedia.
Let's do it step by step
Step 1: Check if you have installed node and npm in your system.
Run these commands in terminal/Command line
node -vand
npm -vif you get the version as the output of the command you have already installed node and npm,if you receive any error please try installing them. Output might look like
v14.16.1Step 2: Set up new npm Package
Run command
npm init -yThis command will do a alot of hardwork at the back and create a package.json file which will keep a track of all the dependencies and DevDependencies we will install throughout our program.
Step 3: Making your first request
npm i -D request request-promise cheerio puppeteeror
npm install --save request request-promise cheerio puppeteer
-D and --save tags are used to install npm module as DevDependencies.
Puppeteer will take a while to install as it needs to download Chromium as well or you can skip this because we are not using puppeteer in our program yet.
Step 3: Go to your favorite Code Editor/IDE
Let's make a file named scraper.js, and write a quick function to get the HTML of the Wikipedia List of Presidents page.
const rp = require('request-promise');const url = 'https://en.wikipedia.org/wiki/List_of_presidents_of_India';rp(url) .then((html)=>{ console.log(html); }) .catch((err)=>{ console.log(err); });Output:
<!DOCTYPE html><html class="client-nojs" lang="en" dir="ltr"><head><meta charset="UTF-8"/><title>List of Presidents of the India - Wikipedia</title>...Using Chrome DevTools
Cool, we got the raw HTML from the web page! But now we need to make sense of this giant blob of text. To do that, well need to use Chrome DevTools to allow us to easily search through the HTML of a web page.
Using Chrome DevTools is easy: simply open Google Chrome, and right click on the element you would like to scrape

Now, simply click inspect, and Chrome will bring up its DevTools pane, allowing you to easily inspect the pages source HTML.
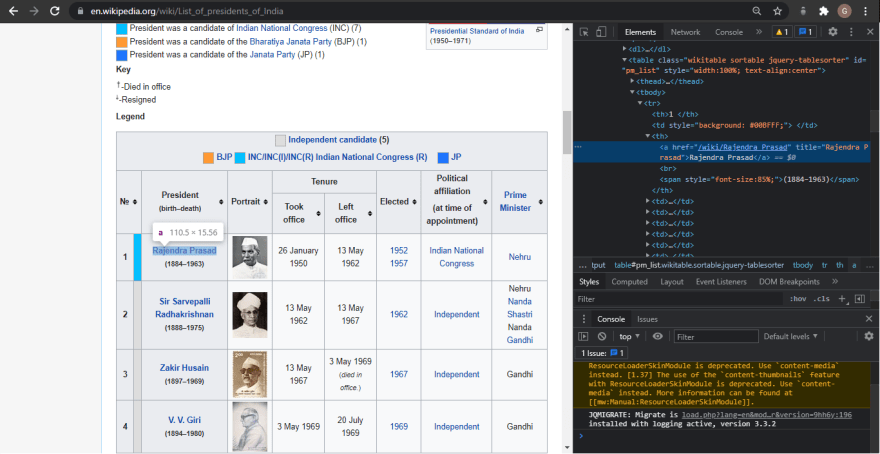
After inspecting the name of the President of India, we came to know that the names are stored inside the th tag wrapped in an anchor tag. So let's use it then !
Step 4: Parsing HTML with CheerioJS
const rp = require('request-promise');const $ = require('cheerio');const url = 'https://en.wikipedia.org/wiki/List_of_presidents_of_India';rp(url) .then((html)=>{ console.log($('th > a', html).length); console.log($('th > a', html)); }) .catch((err)=>{ console.log(err); });Output:
18{ '0': { type: 'tag', name: 'a', attribs: { href: '/wiki/Rajendra_Prasad', title: 'Rajendra Prasad' }, children: [ [Object] ], next: null, prev: null, parent: { type: 'tag', name: 'big', attribs: {}, children: [Array], next: null, prev: null, parent: [Object] } }, '1': { type: 'tag'...Note:
I was facing some problem using cheerio and found out that sometimes require('packageName').default needs to be exported. So if you get an error about cherrio is not function or $ is not a function. Try using this:
var $ = require('cheerio');if (typeof $ != "function") $ = require("cheerio").default;It worked for me!
Step 5: Getting the names of all the Presidents.
We check to make sure there are exactly 18 elements returned (the number of Indian presidents), meaning there arent any extra hidden th tags elsewhere on the page. Now, we can go through and grab a list of links to all 18 presidential Wikipedia pages by getting them from the attribs section of each element.
const rp = require('request-promise');const $ = require('cheerio');const url = 'https://en.wikipedia.org/wiki/List_of_presidents_of_India';if (typeof $ != "function") $ = require("cheerio").default;rp(url) .then((html)=>{ const presidentUrls = []; const length = $("th > a", html).length; for (let i = 0; i < length ; i++) { presidentUrls .push($('big > a', html)[i].attribs.href); } console.log(presidentUrls ); }) .catch((err)=>{ console.log(err); });Output
[ '/wiki/Rajendra_Prasad', '/wiki/Sir Sarvepalli_Radhakrishnan', '/wiki/Zakir_Husain', '/wiki/V._V._Giri', '/wiki/Mohammad_Hidayatullah', '/wiki/V._V._Giri', '/wiki/Fakhruddin_Ali_Ahmed', ...]Step 6: Let's grab their birthdays from the html page.
Now we have a list of all 18 presidential Wikipedia pages. Lets create a new file (named scrapParse.js), which will contain a function to take a presidential Wikipedia page and return the presidents name and birthday. First things first, lets get the raw HTML from Rajendra Prasads Wikipedia page.
const rp = require('request-promise');const url = 'https://en.wikipedia.org/wiki/Rajendra_Prasad';rp(url) .then((html)=> { console.log(html); }) .catch((err)=> { //handle error });Output:
<html class="client-nojs" lang="en" dir="ltr"><head><meta charset="UTF-8"/><title>Rajendra Prasad - Wikipedia</title>...Lets once again use Chrome DevTools to find the syntax of the code we want to parse, so that we can extract the name and birthday with Cheerio.js.
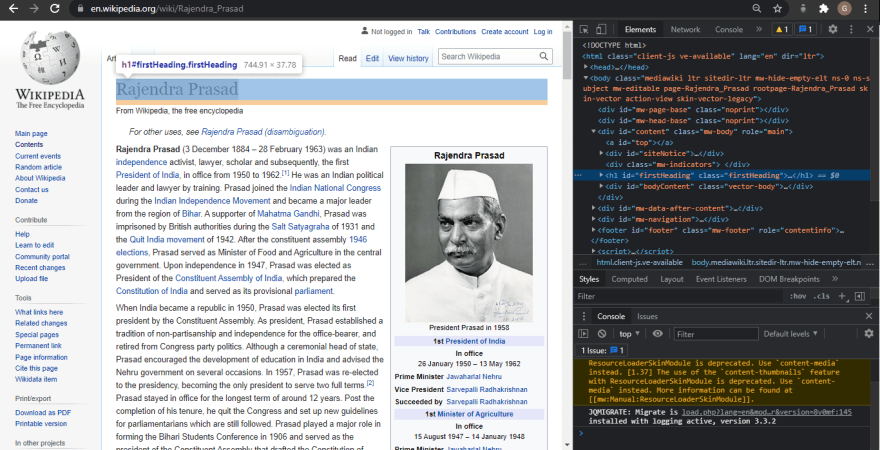
So we see that the name is in a class called firstHeading and the birthday is in a class called bday. Lets modify our code to use Cheerio.js to extract these two classes.
const rp = require('request-promise');const $ = require('cheerio');const url = 'https://en.wikipedia.org/wiki/Rajendra_Prasad';if (typeof $ != "function") $ = require("cheerio").default;rp(url) .then((html)=> { console.log($('.firstHeading', html).text()); console.log($('.bday', html).text()); }) .catch((err)=> { console.log(err); });Output:
Rajendra Prasad1884-12-03Step 4: Putting it all together
Now lets wrap this up into a function and export it from this module.
const rp = require('request-promise');var $ = require('cheerio');if( typeof $ != 'function' ) $ = require('cheerio').default;const scrapParse = (url) => { return rp(url) .then((html)=>{ return { name: $('.firstHeading', html).text(), birthday: $('.bday', html).text(), }; }).catch((err)=>{ console.log(err); });}module.exports = scrapParse;Now lets return to our original file Scraper.js and require the scrapParse.js module. Well then apply it to the list of presidentUrls we gathered earlier.
const rp = require("request-promise");var $ = require("cheerio");const scrapParse = require("./src/scrapParse");if (typeof $ != "function") $ = require("cheerio").default;const url = "https://en.wikipedia.org/wiki/List_of_presidents_of_India";if (typeof $ != "function") $ = require("cheerio").default;rp(url) .then((html) => { const presidentUrl = []; const length = $("th > a", html).length; for (let i = 0; i < length; i++) { presidentUrl.push($("th > a", html)[i].attribs.href); } return Promise.all( presidentUrl.map((name) => { return scrapParse(`https://en.wikipedia.org${name}`); }) ); }) .then((presidents) => { console.log(presidents); }) .catch((err) => { console.log(err); });Output:
[ { name: 'Rajendra Prasad', birthday: '1884-12-03' }, { name: 'Sarvepalli Radhakrishnan', birthday: '1888-09-05' }, { name: 'Zakir Husain (politician)', birthday: '1897-02-08' }, { name: 'V. V. Giri', birthday: '1894-08-10' }, { name: 'V. V. Giri', birthday: '1894-08-10' }, { name: 'Fakhruddin Ali Ahmed', birthday: '1905-05-13' }, { name: 'B. D. Jatti', birthday: '1912-09-10' }, { name: 'Neelam Sanjiva Reddy', birthday: '1913-05-19' }, { name: 'Zail Singh', birthday: '1916-05-05' }, { name: 'Zail Singh', birthday: '1916-05-05' }, { name: 'Zail Singh', birthday: '1916-05-05' }, { name: 'Ramaswamy Venkataraman', birthday: '1910-12-04' }, { name: 'Shankar Dayal Sharma', birthday: '1918-08-19' }, { name: 'K. R. Narayanan', birthday: '1997-07-25' }, { name: 'A. P. J. Abdul Kalam', birthday: '1931-10-15' }, { name: 'Pratibha Patil', birthday: '1934-12-19' }, { name: 'Pranab Mukherjee', birthday: '1935-12-11' }, { name: 'Ram Nath Kovind', birthday: '1945-10-01' }]Additional Resources
And theres the list! At this point you should feel comfortable writing your first web scraper to gather data from any website. Here are a few additional resources that you may find helpful during your web scraping journey:
- List of web scraping proxy services
- List of handy web scraping tools
- List of web scraping tips
- Comparison of web scraping proxies
- Cheerio Documentation
- Puppeteer Documentation
- Guide to web Scrapping
Suggestions and corrections are most welcome.
Get the Code:
 Garima-sharma814 / Web-Scraper
Garima-sharma814 / Web-Scraper
Simple Web scraping app to scrap all the posts by subreddit on the topic of web development.
Web-Scraper
Simple Web scraping app to scrap all the posts by subreddit on the topic of web development.
Written and edited by me
Original Link: https://dev.to/garimasharma/the-ultimate-guide-to-web-scraping-with-node-js-bn3
Dev To
More About this Source Visit Dev To