
An Interest In:
Web News this Week
- April 19, 2024
- April 18, 2024
- April 17, 2024
- April 16, 2024
- April 15, 2024
- April 14, 2024
- April 13, 2024
Some of Our Sources
- Just Creative
- The Logo Smith
- Spoon Graphics
- Smashing Apps
- Inspiredology
- Web Designer Depot
- Reencoded
- Freelance Switch
- Dev To
- Hashedout
Help Webnuz
Referal links:
How Search Engines Work: Finding a Needle in a Haystack
Every time I go to bed I consider myself lucky to have been born at a time like this. In one-tenth of a second I can find out information about anything. It's incredible!.
As of June 18, 2021, there are currently over 1.86 billion websites online. A report by sitefy estimates 547,200 new websites are created every day. It's estimated that Google processes approximately 63,000 search queries every second, translating to 5.6 billion searches per day and approximately 2 trillion global searches per year. These are outrageous numbers by any standard, Yet to the end-user, it's as easy as a click of a button - The true beauty of distributed systems.
If you have ever wondered how search results get delivered to you in a split second, then this article is for you. I will be explaining how search engines work and the different components that work together to deliver results to you - FAST.
How do search engines work?
On a basic level, search engines do three main things:
- Organize the entire web on their database
- Instantly match your search
- Present the results in the way you want them.
1. Organize the web on their database
Contrary to what you might first think. Search Engines do not actually search the internet when you type in a query. That will take yearsss. A lot of things go on behind the scenes to make sense of the internet before you type in your search. So when you hit that little microsope. It only searches its own organized version of the internet which is a lot faster.
Search Engines organize the web through three fundamental actions: crawling, indexing, and ranking.

- CRAWLINGA search engine navigates the web by downloading web pages and following anchor links on these pages to discover new pages that have been made available.
These search engine bots popularly called(Spiders)start from a seed or a list of known URLs, and crawl the web pages at these URLs first. As they crawl those web pages, they find hyperlinks to other pages, and add those to the list of pages to crawl next. They keep going until they have finally crawled the entire web.

Interestingly enough only about 70% of the internet has been crawled. This is because there isn't a central registry of all web pages, so Google must constantly search for new pages and add them to its list of known pages. Other pages are discovered when a website owner submits a list of pages (a sitemap) for Google to crawl.
How does the web crawler know what to crawl?
A web crawler will follow certain policies that make it more selective about which pages to crawl, in what order to crawl them, and how often they should crawl them again to check for content updates. Some of these policies are :
Web page importance - The crawlers use the number of active visitors to that site and the number of other pages that link to that page. If people are visiting the site and referencing its content then it must provide reliable information.
By using the Robots.txt file- A robots.txt file is a set of instructions for bots. This file is included in the source files of most websites. It guides the web bots on what to crawl.
Example:
Check out this site robots.txt for Netflix's own Robot.txt file.
Some examples of popular bots are:
- Google: Googlebot (actually two crawlers, Googlebot Desktop and Googlebot Mobile, for desktop and mobile searches)
- Bing: Bingbot
- Yandex (Russian search engine): Yandex Bot
- Baidu (Chinese search engine): Baidu Spider.
- INDEXING
Imagine having to look for a word in a dictionary that is not arranged or a dictionary that does not have a name tag on each alphabet. Now compare it to a dictionary that has all these. Searching for a word in dictionary 2 will be considerably faster than dictionary 1.

Indexing is done to arrange web pages in a way that information can be easily retrieved from it.
After the pages have been crawled the page URL, along with the full Html document of the page are sent to the store server to compress and store in the database. Every web page has an associated ID number called a docID which is assigned whenever a new URL is parsed out of a web page.
An indexer function reads the pages from the database, uncompresses the documents, and parses them to form an inverted index.
An inverted index is a database index which stores a mapping from content, such as words or numbers, to its locations in a table, or in a document or a set of documents.
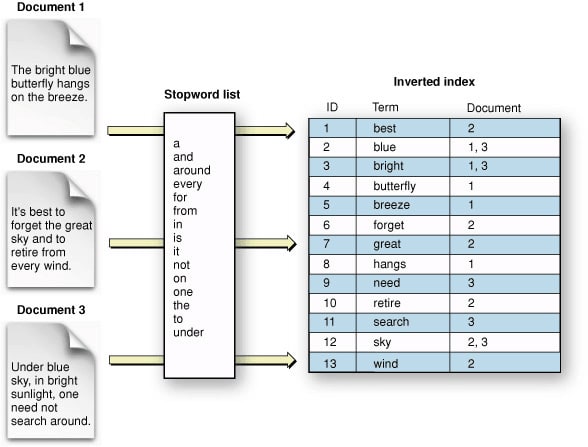
A sentence is broken into words stripped of the stopped words and stored in a row alongside the frequency of occurrence of the word and its position in the HTML document.(stopped words are words that will occur regularly in any sentence such as "the", "is", "at", "which").
If you have a query for example:How long does it take to travel to mars, multiple query words like ("travel" and "mars") are searched independently in the Inverted Index. If travel occurs in documents (2,4,6,8) and mars occurs in documents (3,7,8,11,19). You can take the intersection of both lists where the words occur frequently,(8) in this case, which is the document in which both query words occur.
Storing the documents this way makes search considerably faster. Once a search query comes in. The search engine just needs to get the most frequently occurring words, intersects them and parse them through its own custom search ranking algorithm to deliver the results.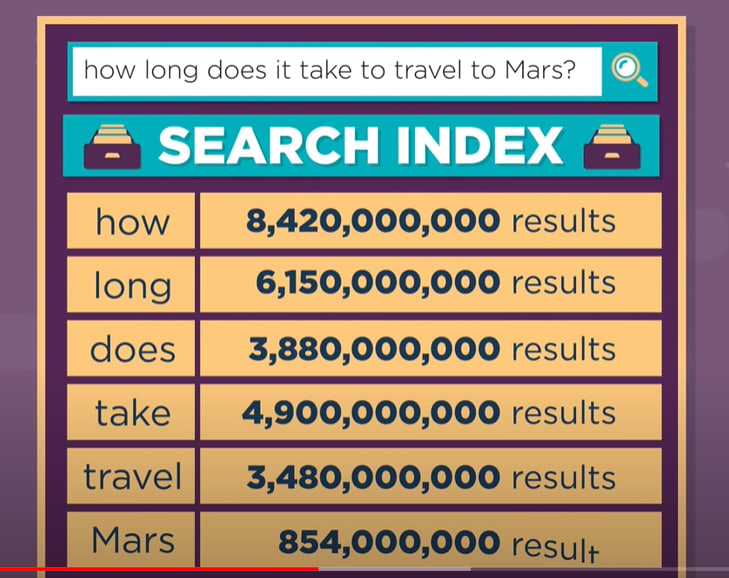
- RANKINGThe algorithms used to rank the most relevant results differ for each search engine. For example, a page that ranks highly for a search query in Google may not rank highly for the same query in Bing. The ranking is accomplished by assessing a number of different factors based on an end users query for quality and relevancy.
The exact algorithms of these search engines have been kept a secret by these companies but a guess can be made based on certain factors.
In addition to the search query, search engines use other relevant data to return results, including:
- Page Quality- Several factors contribute to the page quality such as: how many links references that page, how many page visits the site receives and how long users spend on the page. All these factors determine if the page is quality and if search engines should rank it highly.
- Location Some search queries are location-dependent e.g. restaurants near me or movie times.
- Language detected Search engines will return results in the language of the user if they can be detected.
- Previous search history Search engines will return different results for a query dependent on what the user has previously searched for.
- Device A different set of results may be returned based on the device from which the query was made.
- The freshness of data- How relevant is the data the user needs.
What database do search engines use to store data?
Google uses Bigtable which is a distributed storage system for managing structured data that is designed to scale to a very large size: petabytes of data across thousands of commodity servers.BigTable
Bigtable is not a relational database. Tables consist of rows and columns, and each cell has a timestamp. There can be multiple versions of a cell with different time stamps. The timestamp allows for operations such as "select 'n' versions of this Web page" or "delete cells that are older than a specific date/time."What Database does Google Use?.
Here is a statement from Google's Big table research paper.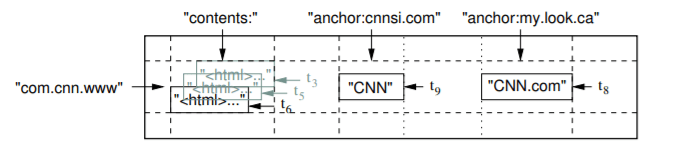
A slice of an example table that stores Web pages. The row name is a reversed URL. The contents column family contains the page contents, and the anchor column family contains the text of any anchors that reference the page. CNN's home page is referenced by both the Sports Illustrated and the MY-look home pages, so the row contains columns named anchor:cnnsi.com and anchor:my.look.ca. Each anchor cell has one version; the contents column has three versions, at timestamps t3, t5, and t6.
To manage the huge tables, Bigtable splits tables at row boundaries and saves them as tablets. A tablet is around 200 MB, and each machine saves about 100 tablets. This setup allows tablets from a single table to be spread among many servers. It also allows for fine-grained load balancing. If one table is receiving many queries, it can shed other tablets or move the busy table to another machine that is not so busy. Also, if a machine goes down, a tablet may be spread across many other servers so that the performance impact on any given machine is minimal.
2. How are search engines so fast? (Instantly matching your search)
If you have N computers and want to search a large document, you can split the document into N ranges and let each computer search that range. So, with string parallelization, you can speed up search queries faster. Your query is split into individual words and sent to a bunch of computers to handle different parts of the query, If you throw in an already inverted indexed database like the one we discussed earlier then the speed could go up faster. If we now store this indexed information on the RAM of these database servers we can take speed to another level. (Information in the RAM is 30 times faster than the real-world performance of an SSD)
Another interesting thing is that search engines do not have to provide you the most absolute correct information all the time. They can cache results and just show the ones that are already high in their ranking for similar queries or show cached information that they have shown you before.
Search Engines also predict words for you. This is done to speed up the search process and reduce the load on the server by preparing already made search results for you so you get things faster. Immediately you start typing Google has already started to look for the first N results so that once you hit enter, the result is already there.
In summary, Search engines return relevant results in response to user queries quickly by using their index and taking advantage of parallelism to break up the large search problem into many small pieces that are solved in parallel.
3. Presenting the results in the way you would want them.
Now let us walk through the process from end to end. When I type into my search bar.

My browser first completes a DNS lookup mapping www.google.com to a specific IP address. At this stage, Googles DNS load balancer determines which cluster of computers at which of Googles data centers will process the query. Once a data center has been determined, the query is transmitted via HTTP to a specific data center and individual clusters of servers.
Upon arrival at the data center cluster, each query is greeted by Googles second load balancer. The Google hardware load balancer consists of 10 to 15 machines and determines which machines are available to process the query.
The query is then split into words and executed, simultaneously hitting 300 to 400 back-end machines representing Googles verticals, advertising, and spell check among others. At this point, the best results are gathered and the query data returns to the Google Mixer.
The mixer takes this data, blends Universal elements with ads while pasting results in order, based on relevancy criteria set by Google's Ranking Algorithm. The ordered results then go back to the Google web server for HTML coding. Once the HTML is completed and pages are formatted, the search engine results are marked done by the load balancer and returned to the user as search engine results pages (SERPs). The entire process taking, about 3 centiseconds".

SUMMARY
Search engines have changed how we access information and understanding their anatomy helps us to truly appreciate the beauty behind the madness.
REFERENCES
7.Behind the scenes of a Google Query
8.Stack Overflow- How does google perform search very fast?
9.How Google searches one document among Billions of documents quickly?
11.The Anatomy of a Large-Scale Hypertextual
Web Search Engine
12.Bigtable: A Distributed Storage System for Structured Data
Original Link: https://dev.to/gbengelebs/how-search-engines-work-finding-a-needle-in-a-haystack-4lnp
Dev To
More About this Source Visit Dev To