
An Interest In:
Web News this Week
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
- March 26, 2024
Some of Our Sources
- Slashdot
- TutsPlus - Code
- Joshua Blankenship
- The Logo Smith
- Naldz Graphics
- Freelance Switch
- Design Modo
- Codrops
- Dev To
- Hashedout
Help Webnuz
Referal links:
AWS Appflow as a Salesforce Migration Method with CDC
My Background: I am Cloud Engineer | Project Manager | Solution Architect in APN Advanced Consulting Partner | MLOps Engineer | 4x AWS | CSFPC | AWS Community Builder | Poke Master |Life apprentice :D
For a long time, a business model known as SaaS has been expanding, which allows software to be distributed over the Internet. This model is an approach that came to replace or complement the traditional business model, changing a focus on the product with a focus on the service.
To get into the context of this post first, we must know Salesforce, which is a service under the SaaS model born a few years ago and it will be the service that we will discuss in this post.

Salesforce is a famous CRM in the market, which provides 360 management capabilities of sales, marketing, customer service and all points of contact, in one place. Many clients have used or have migrated their business processes to this service that allows to keep all the flow of commercial or valuable information for the company centralized.
Along with the growth of the cloud computing concept, these solutions under the SaaS model began to have the need to migrate from their on-premise servers to the cloud. For this reason, the different providers have brought out different services over the years that can help carry out this migration. Among these is Amazon Appflow.
Amazon Appflow is a fully managed no-code integration service enabling seamless and secure data flow between Amazon Web Services (AWS) and software-as-a-service (SaaS) applications. It allows you to source data from AWS services and SaaS applications such as Salesforce, and aggregate them in AWS data lakes and data warehouses to draw unique data-driven insights.
This service presents as its main characteristic the possibility of connecting to various data sources that work under the SaaS model.

New data sources will most likely be added to Appflow support.
However, the important thing about this post is to tell you how this service works to work with CDC (Change Data Capture), and how it has been my experience being one of the many pioneers who developed real solutions within weeks of the product being released.
My Experience with the Release of AWS Appflow
First of all, to protect the integrity of my client who used this service, I am going to mention the client in a generic way so as not to breach any NDA.
The requested use case was to migrate Salesforce objects to a Data Warehouse, with the goal of reducing storage costs in the CRM. At the beginning of my project, the architecture that we had proposed together with AWS was something like the following diagram:
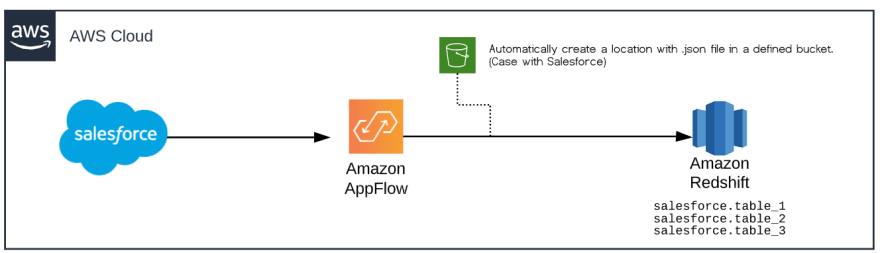
You may wonder why we migrated directly to the Redshift destination and not to AWS S3 to use Redshift Spectrum. The reason for this is simply because when we started the project, AWS Appflow did not yet have all the functionality to go to AWS S3 with upsert option, which meant that we would have to add some additional processing steps that would generate more work time.
The Problem
Thinking innocently, we thought together with the AWS architects, that the service could work according to the customer's expectations. However, the CDC feature was the biggest problem during the project.
The problem was that when a record was updated, the record was duplicated at the destination (Amazon Redshift) generating duplication when making reports with a tool. Although the timestamp is a field that changes, the records that should be unique, such as the Id field, were duplicated.
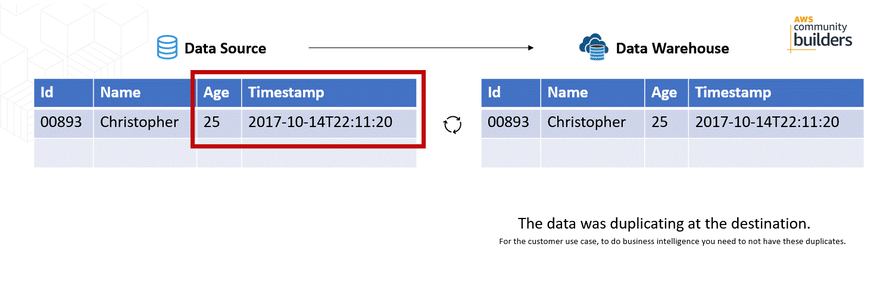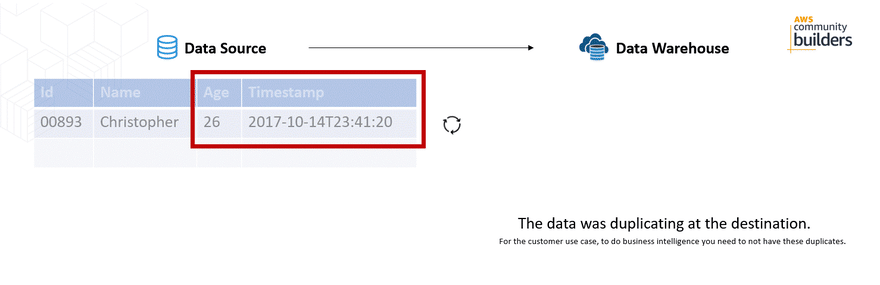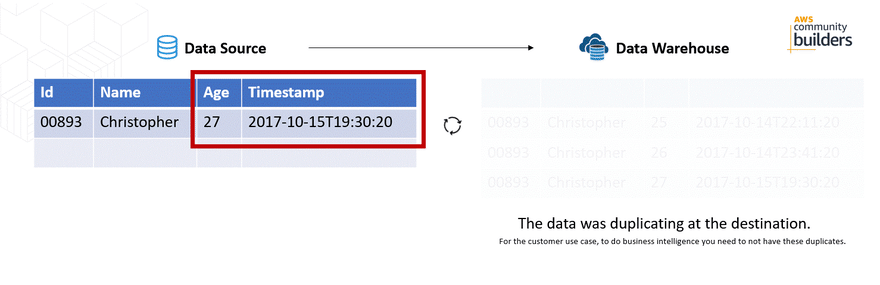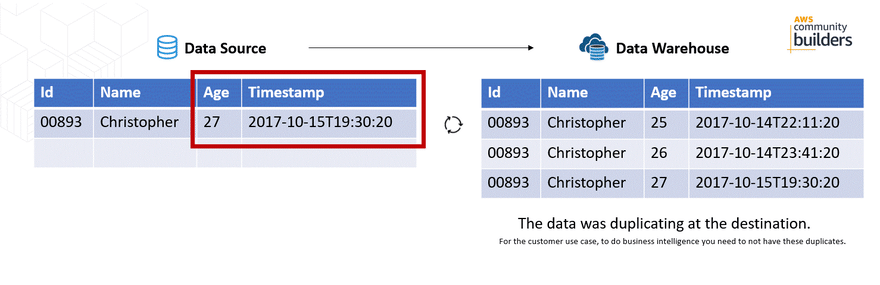
Important: This implementation was during the update of the AWS Appflow, where in October, 2020 an Upsert option was included to data sources such as Salesforce. Document history for user guide AWS Appflow
The Solution
The solution to this problem was to work with a Change data capture process generated in a stored procedure in Redshift. However, it could also have been:
- Do UPSERT processing with a Glue Job
- Send the data instead of the data warehouse to AWS S3 and perform UPSERT processing work with services such as Amazon EMR, managing the Data Lake layers (raw, stage, analytics).
Our decision to use a stored procedure was because the nature of the project was to migrate to a Data Warehouse and not go through a Data Lake, since the client did not require this structure yet. In addition, the processing power of our Redshift according to the analyzed metrics, if it allowed to generate this stored procedure with a trigger that was executed with intervals of minutes.
We also had to change the automatic architecture, where instead of the Appflow jobs being automatically executed by the incremental load of the service. Now the architecture was as follows:

Steps in architecture
1.- The first thing was to find a way to automate the execution of flows with full load, simulating being a daily load. AWS team we proposed to work with an example of CloudFormation of AppFlow with time-automation. The project is Amazon AppFlow Relative Time Frame Automation Example
2.- The second step is to start a lambda that will search an AWS DynamoDB control table for all the templates in S3 and configuration of the objects, with the aim of creating the jobs in AWS Appflow. All this flow will be managed under an AWS Step Function, having greater control in case of failures.
The Step Function has the following design:

3.- The lambda_trigger_appflow is responsible for executing a CloudFormation stack which creates an AWS Appflow Job. This lambda also modifies the DynamoDB control table, to be queried by another Lambda called Status_Job. The aim of this Lambda is validate that jobs are created thanks alstack CloudFormation.
4.- The stack creates an AWS Appflow job.
5.- The Appflow Job is created with a Ready to run status.
6.- The lambda start_job_appflow is in charge of starting all the jobs configured for this execution, also validating that they are all created correctly.
7.- After the AWS Appflow jobs have finished, an AWS Glue Job is executed that through boto3 will look for the Redshift credentials to Secret Manager, and this executes through Python code a procedure located in Redshift called consolidated_of_tables. The sentence executed would be the following: CALL consolidated_of_tables (). No parameters are sent to this procedure.
8.- In the execution of this procedure, what it does is consolidate what is found in a temporary schema, called salesforce_incremental, where thanks to functions such as GROUP BY, ROW_NUMBER can be compared with the target tables that would be in the final schema called salesforce. What the procedure does is simply compare the incremental table with the source table, and it anticipates the duplication of records with unique values.
9.- As a final step, after having the data already consolidated in a final schema, a lambda called delete_elements_flows_snapshots is executed as the last step, which what it does is delete the CloudFormation stacks and the Appflow Jobs already created, with the purpose not to overcome the services quota.
Conclusion
This solution, although it could have some defects related to the current capabilities of AWS Appflow, it is a simple architecture to implement and that can be executed in any proof of concept of clients that want to take their Salesforce objects to a DWH such as AWS Redshift.
Original Link: https://dev.to/aws-builders/aws-appflow-as-a-salesforce-migration-method-with-cdc-part-1-4742
Dev To
More About this Source Visit Dev To