
An Interest In:
Web News this Week
- April 18, 2024
- April 17, 2024
- April 16, 2024
- April 15, 2024
- April 14, 2024
- April 13, 2024
- April 12, 2024
Some of Our Sources
- Slashdot
- BoingBoing
- Mashable
- Smashing Magazine
- Six Revisions
- Abduzeedo
- Creative Curio
- 24 Ways
- Spyre Studios
- Web Resource Source
Help Webnuz
Referal links:
May 25, 2021 08:44 pm GMT
Heading
Original Link: https://dev.to/knassar702/make-your-own-markdown-converter-with-new-features-part-1-1p95
Make your own Markdown Converter (with new Features) - Part 1
Hello ;D
this a simple post about how to make your own Markdown parser, in part 2 we will make a awesome markdown Parser/Features
how Markdown Conveter Works
we well know simple things in this part of our post (Just the basics, preparation for the second part)
1- Heading
2- Include images
3- Links
Heading #
you can add Heading with Big font by one # after repeated, the line will be smaller by a count of #
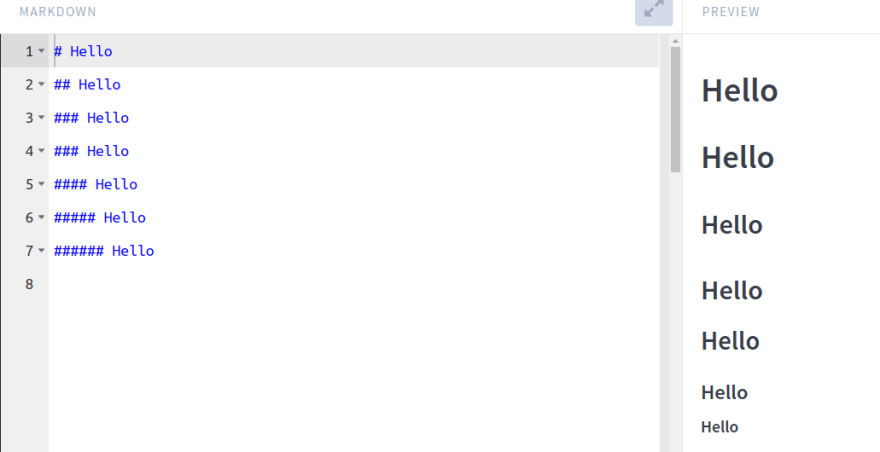
- Convert to HTML
First: get the first word in the line (by space) and count the # and add the count of # in <h> tag , for example### Hello it's will converted to <h3>Hello</h3>

- Code
data = '### Hello'def geth(txt): c = txt.split(' ')[0].count('#') if c == 0 or c > 6: return txt else: v = f'<h{c}>{"".join(txt.split(" ")[1:])}</h{c}>' return vresults = geth(data)print(results)Include Images/Links
you can add images by 
- Convert to HTMLGet The Content of
[]and add it toaltvariable in<img>tag , same thing with()but add it insrcvariable, same thins with links but you need to remove!before[]
<a href=LINK>NAME</a>
sadly, to parse this we need Regex :)

Regex it's scary thing for many programmers (like me) because we are too lazy to learn it (or we learn it when stuck with it in our code)

here the regex we will use !\[[^\]]*\](.*?)\s*("(?:.*[^"])")?\s*\)

- Code
import redef getlnk(txt): sub = '' r = re.search(r'\[[^\]]*\](.*?)\s*("(?:.*[^"])")?\s*\)',txt) if r: c = r.group() # get the content of [] name = re.findall(r'!\[(.*?)\](|. .)[(].*[)]',c) # get the content of () link = re.findall(r'[(].*[)]',c)[0] link = link.replace(link[0],'').replace(link[-1],'') # add the link and name sub += f'<a href="{link}">{name}</a>' return sub# like getlnk function but with ! and <img> Tagdef getimg(txt): sub = '' r = re.search(r'!\[[^\]]*\](.*?)\s*("(?:.*[^"])")?\s*\)',txt) if r: c = r.group() alt = re.findall(r'!\[(.*?)\](|. .)[(].*[)]',c) link = re.findall(r'[(].*[)]',c)[0] link = link.replace(link[0],'').replace(link[-1],'') sub += f"<img src='{link}' alt='{alt[0][0]}' />" return subprint(getlnk('[Google](http://google.com)'))print(getimg(''))# Results# <a href="http://google.com">Google</a># <img src="https%3A//upload.wikimedia.org/wikipedia/commons/thumb/2/2f/Google_2015_logo.svg/1280px-Google_2015_logo.svg.png" alt="Google Logo" />See you in part 2
Bye :D
Original Link: https://dev.to/knassar702/make-your-own-markdown-converter-with-new-features-part-1-1p95
Share this article:
Tweet

View Full Article
Dev To
More About this Source Visit Dev To