
An Interest In:
Web News this Week
- March 21, 2024
- March 20, 2024
- March 19, 2024
- March 18, 2024
- March 17, 2024
- March 16, 2024
- March 15, 2024
Some of Our Sources
- Slashdot
- Techcrunch
- Smashing Magazine
- Inspiredology
- FanExtra - PSD
- Noupe
- Stylized Web
- Wal You
- Android Dissected
- Daily Now
Help Webnuz
Referal links:
Developing an api architecture
Introduction
I love a bit of architecture. How you structure your application is so important and if you get it wrong you'll really pay for it down the line. The problem is you often don't know you've got it wrong until it's too late. I've made this mistake so many times and iterated on solutions so much that now when I start a project I know exactly how I want it to be structured. I've developed what I consider to be a pretty robust pattern for application development.
Essentially I follow a loose Hexagonal Architecture pattern. I won't go into too much detail on what hexagonal architecture is as there are tonnes of articles on the concepts and ideas already. What I will do is show how I interpret it into my own applications. Although there are lots of articles about this pattern, they are very rarely discussed in terms of a node or front end application (usually they are Java-based).
For this article I'll focus on my node app. I'll cover the front end separately as although it's similar at the core, there are some necessary differences.
This is roughly how my codebase is structured:
srcapi| route| | get.ts| | post.ts| | delete.ts|application| feature| | usecase.ts|core| | feature.ts|infrastructure| feature| | method.ts|domain| | feature.ts|bootstrap | setup.tsThis is also termed Ports and Adapters:
- application = usecases
- core = ports
- infrastructure = adapters
So what do all of these layers mean?
I've drawn a diagram of how this application fits into hexagonal architecture. Unfortunately diagram creating is not my strong point so I apologise in advance:
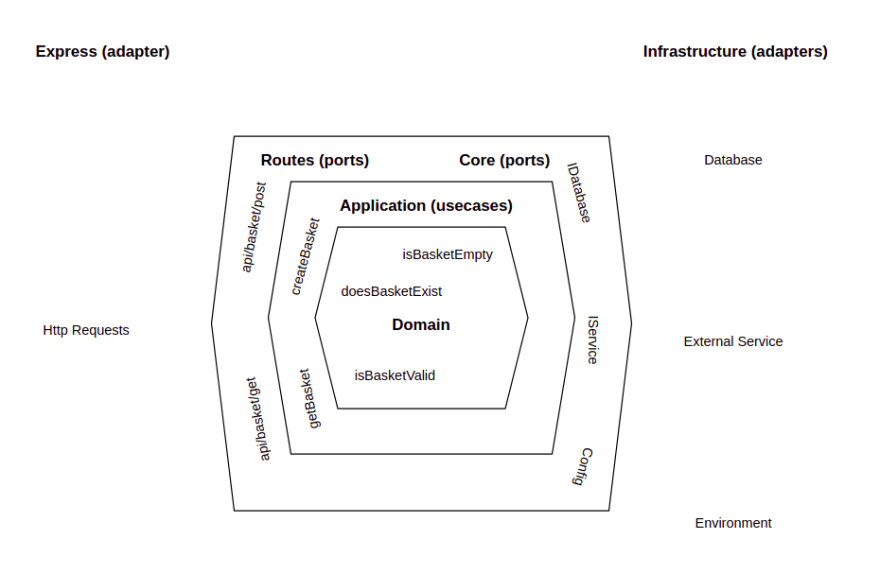
This looks like every other HA diagram I've ever seen and until you "get it" I don't think it really helps that much. I often find it easier to convey the flow of data like this:

At this point you might be thinking: "why are there so many steps for this one request?" and you're right. In a "basic" express app your flow would probably look more like this:

But the problem with this is you're tightly coupling your application in every sense. You make it hard to test the individual parts, you tie your application logic into your server, you tie your database into your application logic, which in turn ties your database into your server. One of the fundamental principles of good software design is to separate your concerns.
So yes this is more files and more layers of abstraction, but that's a good thing I promise!
Let's dive a little deeper into each of these folders:
api
My api layer contains my express routes and nothing else. You can think of this layer as being controllers in an MVC framework. The routes don't contain any logic, they purely pass the request data on to the application layer and then respond with the result. Not only does this keep the routes lean, it keeps all of my application logic agnostic of the delivery method.
async function(req: Request, res: Response) { const basket = await getBasketUsecase(req.userId); res.status(200).send(basket);}The structure of this folder mirrors the express paths, for example: /src/api/basket/get.ts equates to a GET request to /api/basket. When setting up the application, I automatically find all of the files in this folder and calculate the express routes dynamically. This means I never have to manually write app.get('/api/basket') as it's just inferred. This kind of auto-routing is quite common with big frameworks and things like next.js. Personally I like it and it feels like "magic" without being too "behind the scenes".
application
These are my use cases. What I mean by this is that each method is an end-to-end feature. For example "get the basket", "add something to the basket", "remove something from the basket". Each use case will handle things like validating inputs, calling the necessary methods to carry out the action, validating the response, transforming data into the output type, and so on. Essentially this is the "orchestration" layer of the application.
async function usecase(args) { await validateArgs(args); const data = await fetchData(args); const output = normalizeData(data); await validateOutput(output); return output;}There is almost always a 1:1 relationship between the api layer and the application layer. An api endpoint will only call one usecase, and a usecase will most likely only be used by one api endpoint. Why not just combine them into a single function? Loose coupling.
For example, although I am using express for my server, I may want certain use cases to be accessed via a CLI instead/as well. The application layer does not care if a request comes via the web api, or the cli, or some other method. It just cares about the arguments it receives.
The application, core, and infrastructure layers are hard to talk about in isolation (which is ironic) so the next few sections will be a bit intertwined...
core
How does the application layer actually "do stuff" though? If we want to get the basket, for example, how does it do this? We wouldn't want the application layer to import the database and query it directly, this would couple our low level implementation too tightly to the high level use case.
The core layer holds interfaces for all of the things the application can do. When I say interfaces, I mean typescript interfaces, there is no actual javascript here, purely types and interfaces.
So for example, if we want to get the basket, there will be a FetchBasket type that might look something like this:
export type FetchBasket = (userId: string) => Promise<IBasket>;Our application layer operates purely on these interfaces, at no point do we import a fetchBasket function. Instead, we import the interface from the core layer and use dependency injection to say "please fetch the implementation of this type". Dependency injection is really the glue that connects these layers together.
For example, our get basket use case might look something like this:
async function getBasketUsecase({ userId }) { const fetchBasket = jpex.resolve<FetchBasket>(); const basket = await fetchBasket(userId); return basket;}This means there is a "bridge" between the application layer and the underlying implementation detail, which is really important. The above function is really easy to test because the fetchBasket implementation does not exist, you can provide any implementation you want. It also means that your usecases are really clean, because all of the leg work is abstracted away and all you have to do is say "I'd like the implementation of this type please" and off you go.
One awesome benefit of this is that you can write your core layer, then your usecase layer, and not even bother with the infrastructure layer until later. This is fantastic for working on new features where you know what the use case is ("the user wants to see their basket"), and you know roughly what the interface will look like ("pass the user id to the database, get the basket back"), but you're not quite sure on the implementation detail yet.
infrastructure
Now that we have our core interfaces, the infrastructure layer contains all of the implementations for them. Essentially anything that causes a side effect, or reaches outside of your code (like accessing the database) is infrastructure.
Interestingly, infrastructure methods can rely on other core interfaces which means you can have several levels of abstraction. For example, the fetchBasket implementation will probably depend on an IDatabase interface, which in turn would be a wrapper around your actual database.
As mentioned earlier, I use dependency injection (specifically the service locator pattern) to register these infrastructure methods:
jpex.factory<FetchBasket>((db: IDatabase) => (userId: string) => { return db.collection("basket").find({ userId });});bootstrap
The bootstrap folder isn't even a layer, and it does what you think it does. We call a setup function at app start. This creates the express server, finds and registers all of our api routes, finds and registers all of our infrastructure methods, connects the database, and so on.
Misc
There are a couple of notes I wanted to add/clarify as well:
I should mention that I follow a loose function programming paradigm. You won't see any service/repository classes or anything like that. Everything is a function that depends on other functions. I've found that repository classes often become unwieldy, hard to maintain, cluttered with dependencies, and difficult to mock. (Plus all data is treated as immutable, but that affects the frontend much more than the backend)
I should also point out that although the top level folders aren't "domains", this is still domain driven design. We've just grouped the high level concerns of our domains first. You could flip this over and have
domain/infrastructure/method.ts, and I have tried it this way around, but you will almost definitely hit cross-domain issues that don't exist in this format.
Conclusion
So that is an extremely long (but honestly brief) tour of my backend architecture. It's quite a lot to wrap your head around but I have confidence (and experience) that it is an extremely clean, testable, scalable application structure.
Original Link: https://dev.to/jackmellis/developing-an-api-architecture-4g2j
Dev To
More About this Source Visit Dev To