
An Interest In:
Web News this Week
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
- March 26, 2024
Some of Our Sources
- Techcrunch
- Team Treehouse
- Pearsonified
- The Logo Smith
- Vandelay Design
- You The Designer
- FanExtra - PSD
- My Ink Blog
- Fudge Graphics
- Android Headlines
Help Webnuz
Referal links:
Redis: Exploring Redis as Serverless Database to solve idempotence in APIs
Redis means fast. This was the impression I always had. But, at the same time, for me, Redis was just (as if this wasn't enough) a cache store. To my surprise, Redis is much more versatile than this.
This will be the first in a series exploring The State of Serverless Databases in AWS and for it I picked Redis , you know, just to try something other than the usual suspect (DynamoDB) (and to give a third-party offering a try). In the following weeks, my plan is to explore some database offerings used along with serverless at AWS and explore their particular tradeoffs.
Serverless Redis
...an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams.
You can take a look in several in-depth papers describing each data structure in order to make a better informed decision. Since it's open source we could theoretically implement it in a server but it would be a strange, if not wrong turn, in keeping in the Serverless lane. Here enters Uptash, a Serverless database offering for Redis. In Microblogging with Serverless Redis you can take a look how CRUD works and more framework-oriented, you could checkout Lee Robinson has a great video on how to use it with Next.js:
As I promised in the opening article, I want to do in-depth explorations. Not just our run-of-the-mill foo / bar examples (for which the official docs of Upstash is guilty, BTW). For Redis, I almost stuck at the key/value store type, but there are several use cases you can unlock with this solution since it gives you access to a GraphQL API, for which you can have an explorer for you, documented.

Before jumping in: for me, the argument of having a price cap and no surprises in a bill is always a feature, and in this case you don't even need to give your credit card details. I have spoken about this issue in a previous post, Open letter to AWS: Please, give us a price cap, and for me at least, as a developer and living in Brazil, it is an extremely overlooked matter by AWS.
My objective is to try to take use-cases with some value and at the same time explores a deep more about dealing with the data and I want to tackle a very important one, at least, for me: idempotence. So there will be nothing fancy than a key/value store but I think explore an important feature for any production-grade function. Also, please note that while this is a feature in NodeJS, I'm following the steps of the official Python Powertools library. I hope if you are not from the Node ecosystem could get some value as well.
Idempotence: doing by myself
An idempotent operation can repeat an arbitrary number of times, and the result will always be the same. In arithmetic, adding zero to a number is idempotent. Some kinds of requests into AWS lambda should run more than once, generating inconsistency problems when your function isnt idempotent. AWS has a page in how to address this much needed feature. And, yes, it is canon, there is a really important reason to make your API idempotent.
Making an API idempotent is not as trivial as many people think. You could start out by looking at Lambda Powertools for Python from AWS that does a magnificent job of explaining this use case and a concrete way to implement. Theres also this great article from Malcolm Featonby, Making retries safe with idempotent APIs featured in the Amazon Builders Library as Architecture level 300 which falls in the advanced classification.
Lets start with our scope from the Lambda Powertools:
Idempotency key is a hash representation of either the entire event or a specific configured subset of the event, and invocation results are JSON serialized and stored in your persistence storage layer.
First, I create a new database. Im from the famous 5 minutes install from WordPress. Upstash claims a 30-second installation, and they are not joking):
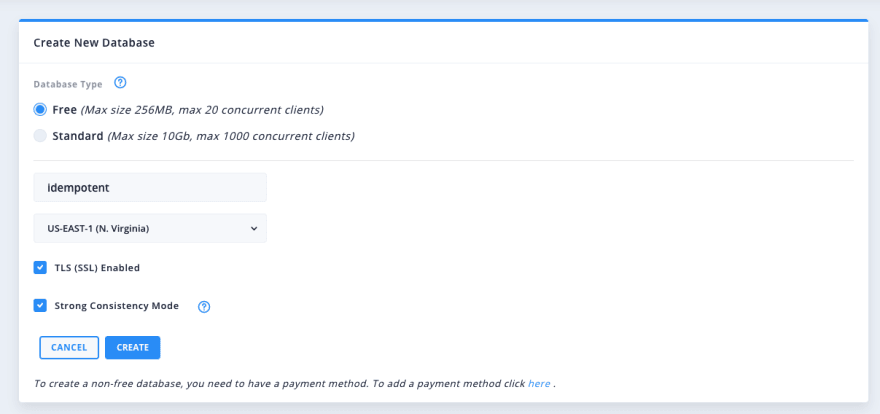
Here you can see I chose to enable the Strong Consistency Mode. strong consistence. Strong Consistency offers up-to-date data but at the cost of high latency. Eventual consistency offers low latency but may reply to read requests with stale data since all nodes of the database may not have the updated data. Since this is a highly complex topic, and this brief explanation only very briefly begins to scratch at its surface, I recommend you read the book Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann. I usually work with eventual consistency most of the time. Im picking strong here because I want to make the best effort to be as idempotent as possible, because otherwise we could get false negatives.
Each Lambda receives an event as part of their request.
So, the first thing we are going to do on our lambda function is to create a hash representation of the whole object event. I'll use the Node native crypto lib.
const hash = crypto .createHash(sha256) .update(event) .digest(base64);This will generate a unique identifier for that given event and this is going to be used as our unique key in the Redis database.
Ill leverage Middy, a lightweight middleware for Lambda in Node, which has a particularly cool feature (and a really helpful one for the task at hand) that is its onion-like middleware pattern implementation and the ability to create a middleware that can read the function after and before the handler, which is essential for idempotent APIs.

In the before we had to turn the event into a hash;
const createHash = (event: any): string => { return crypto .createHash(sha256) .update(JSON.stringify(event)) .digest(base64);};Note that theres an explicit any therethe mythical, non-existent in production any.
Then, check at the Redis database if that hash already exists in the table. Well do this using the lib ioredis. That well pass an option to the middleware we are creating.
//in the handlerimport Redis from ioredis;// handler codehandler.use(jsonBodyParser()).use( idempotent({ client: new Redis(process.env.UPSTASH_REDISS) }));The Redis instance is receiving the rediss:// string with your user and password credentials through the environment. This is not the most secure way to do so, you can store this URL in AWS Systems Manager and then import in a secure way that will even let you rotate the credentials if needed. Im taking this shortcut here for the purpose of this test, but I'm sure you'd never do this in production, right?

Anyway, we then need to parse the result since well save them as string in the next stage of execution.
// in the middlewareconst hash = createHash(request.event);const getByHash = await options.client.get(hash);if (getByHash) { return JSON.parse(getByHash);}In case of a miss, we get a null response, which is great to a really simple check. If we get null, we dont need to do anything, the function will then proceed to other middlewares, the handler and then to the after execution order. If this get is not null, we have to return the response stored by our after function.
{ statusCode: 200, body: {
data: {
message: Hello from the other Side!
}
}}Then well invoke return response in your middleware.This will halt the execution early and it will not pass for any other part of the lambda, so this middleware needs to be one of the first, if not the first to avail.
In the after we had to save the response from that event hash.
const hash = createHash(request.event);const responseStr = JSON.stringify(request.response);await options.client.set(hash, responseStr);And nothing more. Pay attention that this phase and execution happens after the handler send the response through the handler.
And that's that. Pay attention that this phase and execution happens after the handler sends the response through the handler.
And yes, it is fast. Theres a post from Upstashs own blog, Latency Comparison Among Serverless Databases followed by a discussion on Hacker News. I did not make a benchmark or even plan to do so, but as a user, I felt it was as instantaneous as could be. And this is certainly a feature that meets my purposes.
And well folks, thats all.
Just kidding, of course it's not. But it is a start. Since the chance of collision is nearly impossible (i.e., two hash being equal) only exact the same request will get the same response, but if we want to check some keys like a x-idempotence key in the header or even a field in the body of the request, we could target it as well.
If you wanna that a look at this implementation and help, I wrapped this code and made available for your use in NodeJS Lambdas, as a middleware for Middy. The lib accepts options to target headers, keys in the body and path:
 ibrahimcesar / middy-idempotent
ibrahimcesar / middy-idempotent
Idempotence Middy middleware for yours AWS Lambdas
Idempotent Middleware for Middy
An Idempotent Middy middleware for your AWS Lambdas
Developed in Brazil
What is does
Middy is a very simple middleware engine that allows you to simplify your AWS Lambda code when using Node.js. This middleware aims to simplify the implementations of a idempotent API.
Making an API idempotent is not trivial as much people think, and you could take a look at Lambda Powertools for Python from AWS that does a great job to explain this use case and a concrete way to implement. There's also this great article from Malcolm Featonby, Making retries safe with idempotent APIs featured in the Amazon Builder's Library as Architecture level 300 which falls ins the advanced classification.
Install
Use your favorite package manager:
yarn add middy-idempotentnpm install middy-idempotent -SUsage
Besides @middy/core, you must also use @middy/http-json-body-parser since this middleware
As for the lib above, you can implement the SSM so it won't place your secret string in the environment for your infrastructure, but I plan to add another storage provider, DynamoDB at least in the next days.
Following that Ill test another serverless database offering in a not so Hello World example but with practical and more valuable use cases - or at least, this is my hope! And please leave your thoughts, takes and insights in the comments!
Original Link: https://dev.to/aws-builders/redis-exploring-redis-as-serverless-database-to-solve-idempotence-in-apis-2gma
Dev To
More About this Source Visit Dev To