
An Interest In:
Web News this Week
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
- March 26, 2024
Some of Our Sources
- TutsPlus - Code
- Smashing Magazine
- Smashing Apps
- Six Revisions
- Naldz Graphics
- Noupe
- Fudge Graphics
- Web Design Ledger
- Android Headlines
- The Verge
Help Webnuz
Referal links:
Hibernate Naming Strategies: JPA Specification vs Spring Boot Opinionation
Each time we inject a dependency into our project, we sign a contract, which often has lots of hidden things "written in the fine print". In this article, we will take a look at something you could miss when signing a tripartite contract between you, Hibernate and Spring Boot. We will talk about naming strategies.
Defaults in JPA Naming
The ultimate rule about defaults: they must be intuitive. Let's check if this rule applies to a standard Spring Boot application with default configuration using Hibernate as a JPA implementation. Imagine you have an entity PetType. Lets guess what table name in the database it is associated with.
First example:
@Entitypublic class PetType { // fields omitted}To me, the most intuitive table name would be the class name, which is PetType. Running a test against PostgreSQL we find out that the associated table name is actually pet_type.
Lets set the name explicitly using @Table:
@Entity@Table(name = "PetType")public class PetType { // fields omitted}This time we expect to see PetType for sure, but if we run the test pet_type again!
Well, let's wrap the table name in quotes. This should keep not only the defined name but also the case.
@Entity@Table(name = "\"PetType\"")public class PetType { // fields omitted}Again, our expectations were wrong, and we see pet_type, but now in quotes!
Hibernate Naming Strategies
Googling "jpa entity default table name" youll most probably stumble onto the following result:
The JPA default table name is the name of the class (minus the package) with the first letter capitalized. Each attribute of the class will be stored in a column in the table.
It is exactly what we expected to see in the first example, isn't it? Obviously, something breaks the standard.
Let's dive deeper into Hibernate. According to the documentation, there are two interfaces responsible for naming your tables, columns etc. in Hibernate: ImplicitNamingStrategy and PhysicalNamingStrategy.
ImplicitNamingStrategy is in charge of naming all objects that were not explicitly named by a developer: e.g. entity name, table name, column name, index, FK etc. The resulting name is called the logical name, it is used internally by Hibernate to identify an object. It is not the name that gets put into the DB.
PhysicalNamingStrategy provides the actual physical name used in the DB based on the logical JPA object name. Effectively, this means that using Hibernate you cannot specify database object names directly, but only logical ones. To have a better understanding of what's happening under the hood, see the diagram below.
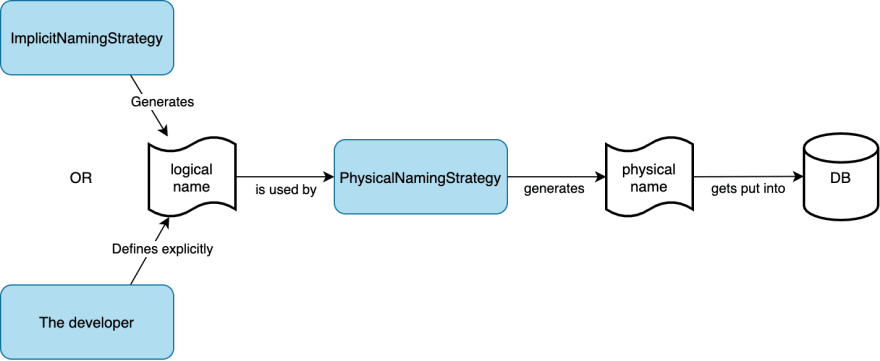
Hibernate default implementations of these interfaces are ImplicitNamingStrategyJpaCompliantImpl and PhysicalNamingStrategyStandardImpl. The former generates logical names in accordance with the JPA specification, and the latter uses them as physical names without any modifications. This is best described in the documentation:
JPA defines inherent rules about implicit logical name determination. If JPA provider portability is a major concern, or if you really just like the JPA-defined implicit naming rules, be sure to stick with
ImplicitNamingStrategyJpaCompliantImpl(the default).
Also, JPA defines no separation between logical and physical name. Following the JPA specification, the logical name is the physical name. If JPA provider portability is important, applications should prefer not to specify aPhysicalNamingStrategy.
However, our application shows different behaviour. And this is why. Spring Boot overrides Hibernate default implementations for both interfaces and uses SpringImplicitNamingStrategy and SpringPhysicalNamingStrategy instead.
Effectively, SpringImplicitNamingStrategy copies the behaviour of ImplicitNamingStrategyJpaCompliantImpl with only a minor difference in join table naming. So, it must be SpringPhysicalNamingStrategy that produces the results weve seen. The documentation states the following:
By default, Spring Boot configures the physical naming strategy with
SpringPhysicalNamingStrategy. This implementation provides the same table structure as Hibernate 4: all dots are replaced by underscores and camel casing is replaced by underscores as well. Additionally, by default, all table names are generated in the lower case. For example, aTelephoneNumberentity is mapped to thetelephone_numbertable.
Basically, it always transforms camelCase and PascalCase to snake_case. In fact, using it isnt possible to work with non_snake_case at all. Personally, I would never use camelCase or PascalCase for naming database objects, but there are DB admins who would. If your Spring Boot application deals with a third-party database where at least one table or column is defined in a pascal or camel case, the default Spring Boot setup will not work for you. So, make sure the used physical naming strategy supports the given database naming convention. Learn how to change the default naming strategy in this article or, if required, learn how to provide your own implementation here.
So, Hibernate complies with the JPA spec and Spring Boot doesnt. This may look like a bug, but Spring Boot claims to be an opinionated framework. In other words, it has the full right to apply its own opinion over all standards and specs of the technology used under the hood. For a developer this means the following:
- Opinionation may override any specification. In other words, specs and standards state how it should be, while the used implementation defines what it actually is.
- If something even works by default, you should always learn what this default is and how exactly it works.
- Defaults may change with library version upgrade, which can lead to unpredictable side effects.
Conclusion
The magic of default configurations may work until you hit some unexpected behaviour. To avoid such risk, you may prefer explicit definition to implicit use of defaults. So, in our case the recommendation would be:
- Always name your JPA objects explicitly, so that no Implicit Naming Strategy affects your code
- Use the snake_case for columns, tables, indexes and other JPA objects names in order to avoid their transformation by any implementation of the Physical Naming Strategy
- In case of snake_case doesn't work for you (e.g. using a legacy database), set Physical Naming Strategy to
PhysicalNamingStrategyStandardImpl
Explicit naming of JPA objects will also prevent database schema from unwanted changes in case of an entity class or a field name refactoring.
You may notice that solving potential problems in runtime we simply transfer responsibilities to developers by introducing naming conventions. Now we need to make sure that all developers follow the same rules. This can be automated by shifting these responsibilities further to development tools.

So, if you use IntelliJ IDEA, you may try JPA Buddy a plugin intended to help developers with JPA, Hibernate, Spring Data JPA, Liquibase and other related technology. JPA Buddy enables a team to set up agreed code conventions and applies them for newly generated JPA entities.
Original Link: https://dev.to/aleksey/hibernate-naming-strategies-jpa-specification-vs-spring-boot-opinionation-m1c
Dev To
More About this Source Visit Dev To