
An Interest In:
Web News this Week
- March 20, 2024
- March 19, 2024
- March 18, 2024
- March 17, 2024
- March 16, 2024
- March 15, 2024
- March 14, 2024
Some of Our Sources
- Mashable
- Simplebits
- Web Designer Wall
- Vandelay Design
- FanExtra - PSD
- Line 25
- Spyre Studios
- Freelance Switch
- Android Dissected
- Willems Lab
Help Webnuz
Referal links:
Properly Understanding the DOM
Intro
If you're a front-end developer, you've probably heard of the DOM, or used some DOM methods in JavaScript. However, you may not know exactly what it is, or how it works.
This article will give you a solid understanding of the DOM and how it fits in with the rendering of webpages on the screen. Along the way, we'll cover some crucial concepts to do with JavaScript objects, the browser and rendering. This will help develop your expertise in web development and make you more productive with the tools that the DOM provides, even if you are using a JavaScript library or framework.
Prerequisites
- Some familiarity with HTML, CSS and JavaScript
The browser
Firstly, we need to understand the web browser on your device a little better. In this article I'll refer to two core components of browsers.
The first is the rendering engine (also called the browser engine), which reads HTML and CSS files and renders (outputs) the content on the screen. It can actually be used outside the browser, for example email clients use a rendering engine to display HTML email. You may have heard of the rendering engines used in popular browsers - Blink (Chromium browsers, i.e. Chrome, recent versions of Microsoft Edge and many more), Gecko (Firefox) and Webkit (Safari).
The second component is the JavaScript engine, which reads and runs any JavaScript files given to it. Again, this is a standalone component that can be run outside the browser. The most popular one is Google's V8, used in Chromium browsers and by NodeJS to run JavaScript on the server. Firefox uses SpiderMonkey and Safari's is called JavaScriptCore.
The rendering engine and JavaScript engine work together inside your browser to produce webpages. They tend to be written mainly in the programming language C++.
The core functionality that browsers provide is based on certain standards, but when referring to the features browsers make available to developers, I'll use the Mozilla Developer Network web docs, because they are a more accessible guide to the tools available to us and how they are implemented in different browsers.
The global object
Another thing it's important to understand properly is objects in JavaScript. In programming, we describe the world with objects - little containers of data that link to other data.
Let's imagine for a moment we wanted to describe the whole world. That object would have a lot of things on it, i.e. properties. Things that exist in nature like trees, human inventions like the mobile phone, and things you can do like 'eat cake'. The last one would be a function in JavaScript, and the property is called a method in that case.
In our example, the world object is the 'place we put all the stuff'. JavaScript also has a place like this, and it's called the global object. Assuming my JavaScript is running in the browser, the global object contains properties and methods related to the browser and the webpage.
It's quite hard to define what the global browser object actually represents. Your webpage runs in a tab, with unique elements and events happening. A page in another tab is separate, running different JavaScript with its own global object. So we might call the global object the 'tab' object. But you also have access to browser properties, like browser history and storage for example. So what should we call it?
Well, the browser provides it in a variable called window. But it doesn't exactly represent a user interface window. It's just a label for the 'place we put all the stuff'. JavaScript makes it easy to access this place - we don't need to say window to access the stuff on it, just saying myVariable is the same as saying window.myVariable (in most cases).
The definition of what is always on the window object has been standardised, using interfaces. This is an object-orientated programming term which refers to the description of an object, rather than the object itself. Though an interface is generally a point of interaction, here it means the description of an object, because that enables the interaction of objects to happen smoothly, since they know what properties and methods another object has.
Here's two things we should know about interfaces:
The interface name is written in PascalCase as a convention.
Interfaces can take properties and methods from other interfaces, by inheriting them from an ancestor interface, or getting them from an unrelated interface called a mixin. We'll see this later.
Web APIs
Here's MDN's documentation on the interface for the window object: Window.
Have a look and you'll see there's quite a lot on there. The functionality the browser gives us to communicate with it is known as Web APIs.
API stands for application programming interface. In other words, someone wrote an application, in this case the browser, and they also wrote a set of features and rules so you could interface (interact) with it using programming.
For example, let's say you use fetch() in your JavaScript code to get a resource from the internet. That's not part of the JavaScript language - you couldn't use it in JavaScript not being run by a browser. But in a browser you can use it, because the browser attached the fetch method to the window object when it created it.
The Web APIs make use of objects with properties and methods, just like the window object. In the fetch API, one of these is the Response object. The API defines exactly what the structure of the object should be.
But we're not going to talk about all the weird and wonderful APIs available to us in the browser: we want to know what the DOM is. There's just one more thing to look at first: a property of the window object called document.
Documents and trees
Just like how the window object is the container for almost all of the 'global' stuff (console, scrollbars, window dimensions etc.) in your browser, the document is a container for the content, i.e. the webpage itself. It represents what you give the browser, not what's already there. This can be an HTML, XML or SVG document, but we're just going to talk about HTML.
You can give your browser a HTML file by asking it to open one stored locally on your device, or you can request to view a website, causing the browser to retrieve the file from that website's server via the internet. The browser's rendering engine (mentioned at the beginning) then does two things: parse the HTML (read the code line by line), then create a tree of elements.
When I say create a tree, I'm not talking about planting. It's one way of storing data with a programming language, by creating objects that have 'family' relationships between them. These 'family' relationships are the same you create in an HTML document.
The relationships are defined by edges (which clearly ought to be called 'branches', but never mind...). The objects at the end of an edge are known as nodes, because this means the place where lines join (it's also the place where a leaf and stem join on a plant, so it's a bit closer to the tree metaphor). But remember, a node is still just a type of object.
The node at the very top of the tree is called the root. Visually, the structure would be sort of like a tree. What the browser creates is known as a document tree: a node tree where the root node is a document. It stores information about the document in that root node, and each HTML element on the page and any text inside them also has its own node.
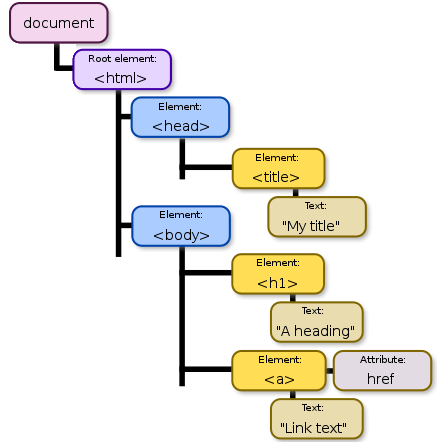
Enter the DOM
Let's finally talk about the DOM.
The DOM, technically, is not the document tree, i.e. the data structure itself. It's the model that describes how the data should be stored and interacted with. However, you will often hear people saying things like 'manipulating the DOM', which is simpler to say than 'manipulating the document tree'. I'll use DOM in this sense too, for convenience.
The technical term for it is an 'object model', which means it defines some objects and how they can be manipulated, but we don't need to worry about that. Just know that's what DOM stands for: Document Object Model.
The key thing is that the DOM is one of the browser's Web APIs. We can get information about (read) DOM nodes and change them (write) using JavaScript. We know how to do this because it's described in the interfaces for the DOM API.
To be clear, the DOM is a generic API for manipulating documents. There is a specific offshoot for HTML called the HTML DOM API (remember that other types of documents can be modelled by the DOM). But this distinction doesn't really affect us practically.
We can see the interfaces we need in MDN's documentation on the DOM and HTML DOM. (The 'official' description is currently WHATWG's DOM Living Standard, and the HTML DOM is defined in WHATWG's HTML Living Standard.)
Using the DOM
Let's use an example to understand interfaces.
In my JavaScript (which the browser's rendering engine discovered in my HTML document via the <script> tag, and the browser's JavaScript engine is running with window as the global object), I have access to the document object, as discussed.
It's described by the Document interface. On the list of methods, you will see Document.querySelector(). This lets me use CSS selector syntax to get an element from the document - in this case, an HTML element, because our document is HTML.
Now say I have an <input> element in my HTML file with an id my-input. I write the following in my JavaScript:
const input = document.querySelector('#my-input');
When the JavaScript engine parses my code, it will need to work out the value of the input variable, so it will run the function, i.e. in C++ it will go search the document tree for the right element (C++ object), find it, convert it to a JavaScript object and give it back to the JavaScript engine. If it doesn't find one, it returns null, a primitive value in JavaScript essentially meaning 'no value'.
In my example, I now have a variable pointing to the element object. Specifically, it's a HTML input element, described by the HTMLInputElement interface (part of the HTML DOM). You can see from the properties listed that I can access the value (the text) in the input and read/write it. Pretty useful.
Now looking at the methods, you'll see things like blur() and focus(). Very useful too. But look at where they come from - they are inherited from HTMLElement. My input is a type of HTMLElement, so it gets properties and methods shared by all HTML elements.
The inheritance doesn't stop there - HTMLElement is a type of Element (now we're back in the generic DOM API). There's some useful stuff there too, like setAttribute(), so I could add, say, a class on my input field in certain circumstances.
Let's keep moving on up. An element is a type of Node. We know what those are. Element isn't the only type of node - Document is also, of course, a type of Node, since it's the root node of the tree. And we mentioned before that the text inside an element gets its own node, Text, which you can read/write from the node with the textContent property.
Note: we may be confused here because there is also an HTMLElement.innerText and an Element.innerHTML method. As MDN explains, these methods have poorer performance and innerHTML can leave you vulnerable to cross-site scripting (e.g. I get the value from my input and set the innerHTML of a div somewhere else to whatever it is - someone could have written a <script> tag with malicious JavaScript code that will be run on my page). So if I just want to add text to an element, textContent is the better property to use.
Now we get to the top of our chain of our inheritance - all of these are a type of EventTarget. And so is Window. This allows me to add or remove event listeners, which allow me to respond to page events (like clicks) with a JavaScript function.
One last thing to discuss here: let's say we used Document.querySelectorAll() to get all inputs of a particular type. Note that it returns a NodeList. That's annoying, why not a JavaScript array? Well, remember that the DOM isn't part of JavaScript - it's language-independent. You could use DOM methods in Python, for example. That means working with DOM objects in JavaScript isn't quite like working with any other kind of object.
The DOM in DevTools
Handily, browsers give us some nice tools that help us view and interact with the DOM.
Here I opened Chrome developer tools on the Google homepage and inspected their festive logo img element:
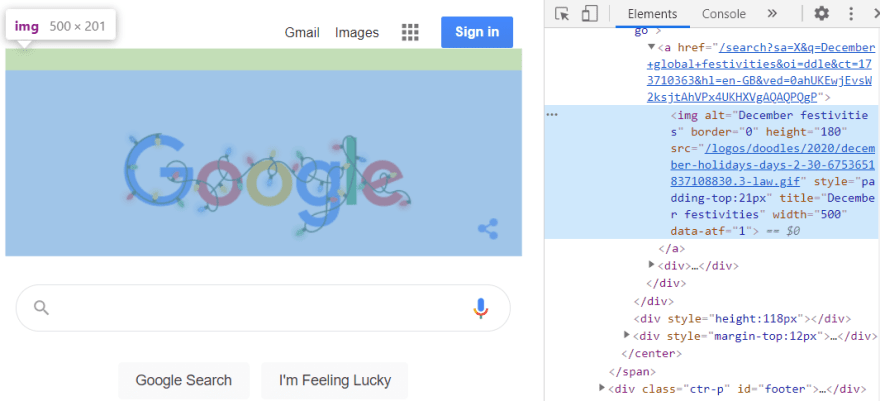
The Elements tab shows us the image tag and its place in the document. It looks like it's just an HTML tag, but it's not. We could see the original HTML by right-clicking the page and selecting 'view page source'.
In fact, the Elements tab is a visual representation of the DOM, and the elements in it are objects.
Let's prove this by going to the Console tab. If we enter $0 (the Console shortcut for logging the element currently selected in the Elements tab) this will just show us the same representation. But if I use console.dir I can see the object:

Here we can see all the object's properties, including those inherited properties.
In JavaScript, the object an object inherits from is called its prototype, i.e. the thing you base something else on. Our image element inherits properties and methods from its prototype, 'HTMLImageElement', which in turn inherits from its prototype, 'HTMLELement', and so on. This is a prototype chain.
We can see the prototype object by expanding the __proto__ property. If we kept following the chain up we'd end up at Object, which is the object that contains the properties and methods all JavaScript objects inherit. This is just for demonstration - you won't need to do this.

All of these objects in the chain, except the actual image element, already existed on the window object of the JavaScript engine. If you did console.log(window) on a blank HTML page you could still find them. When I accessed the logo img element using the DOM and it became a JavaScript object, its prototype chain was set with those objects.
The property values were either provided as attributes in the HTML image tag, set using the DOM API in JavaScript, just known by the browser e.g. properties relating to dimensions, or have remained as default values since the object was created. If you just create a plain image element without any further information, the values are all defaults.
Hopefully you now have a better idea of what DOM objects are and how to inspect them. If you want to learn more about inspecting the DOM with Chrome devtools, Google provides a guide here.
Rendering
Now we understand the DOM and how to use it, lets look more closely at the process of rendering a page, so we can think more carefully about how we use the DOM.
Any site you visit is essentially an HTML file (the 'document'), with references to other files (HTML, CSS or JavaScript) which are all stored on a server and sent to the browser via the internet. The browser parses the HTML and starts constructing the DOM.
However, JavaScript can affect the parsing process. If the browser gets to a <script> tag in the HTML, it will pause DOM construction by default while the JavaScript code in the <script> tag is executed, because the JavaScript might alter the HTML content by using the DOM API.
This is why it's often advised that you put the <script> tag at the bottom of your HTML, so the HTML can be loaded first. Alternatively, you can change the default behaviour by using the defer or async attributes on the script tag.
The browser also creates a CSS Object Model (CSSOM). This is similar to the DOM, but instead of representing your HTML document, it represents your CSS style sheets and their content with interfaces.
Its an API, so you could interact with it to alter your styles, but you are better off defining all the styles you will need in your stylesheet first, then if necessary changing what they apply to using the DOM, by altering the class names on your elements (or using the style attribute on the elements if you prefer).
To get ready for rendering, the DOM and CSSOM are combined to create another tree, the render tree. Anything that wont be displayed on the page, e.g. the <head> element, is excluded. The render tree contains all the information the browser needs to display the webpage.
The browser assembles the layout of elements on the page (like doing a pencil sketch before a painting), then paints the elements to the screen.
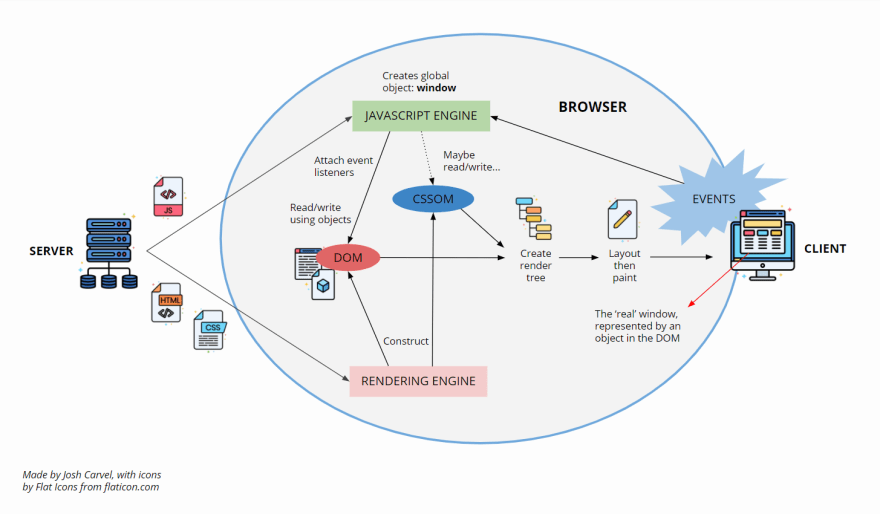
This means that if we respond to user interaction on the page by changing the DOM, the browser will have to do some work to re-layout and repaint items on the page. This has a performance cost, and could be what we would call expensive in performance terms. However, the browser responds to events efficiently as possible, only doing as much re-layout and repainting as necessary. This is explained in Tali Garsiel's research on how browsers work.
Bear that in mind, because there is sometimes a misconception that the reason we have fancy front-end frameworks is that the DOM itself is slow. That wouldn't make sense - frameworks still have to use the DOM, so they couldn't possibly make it faster. Really, it's all down to how you use the DOM.
Let's look briefly at the history and present of DOM manipulation to understand this.
Libraries, frameworks and plain JS
You will often hear about JavaScript libraries and frameworks. A library gives you additional methods written by other developers, and you can call those methods whenever you want. A framework has more control of your application architecture, so it calls the functions in your code when appropriate, not the other way around.
For a long time, jQuery was the standard way to write JavaScript. It's a library that was created in 2006 to make DOM manipulation easier at a time when the DOM API was limited and very inconsistently implemented by browsers. It's still used today and some people like using its concise syntax, but its core functionality can now be achieved in modern browsers using plain JavaScript.
Modern libraries and frameworks don't need to tackle deficiency in the DOM, but they do aim to improve your efficiency and productivity in using it. It's not the sole reason they exist, but it's a big one.
If you are writing a simple website with limited user interaction, you probably won't run into the efficiency problem, provided you're not doing something very silly performance-wise with your DOM manipulation. But simple sites are not all we have on the web today web applications such as Facebook are very common.
These applications contain dynamic, constantly changing content that heavily rely on user input and pulling new data from the server. JavaScript pulls the strings of these changes and is central to the operation of the application. This is a big departure from what the whole infrastructure of serving webpages to the browser was originally designed for. But the problem is not that lots of changes need to be made, it's how to tell the browser exactly which bits need to change, so you're not re-rendering more than necessary, and to do so without causing any bugs.
The core front end libraries and frameworks most used today are React, Angular and Vue.js. These aim to take efficient DOM manipulation off your hands, so there is more emphasis on what you want the page to look like, not how this should be achieved. If you want to make web applications professionally, your best bet is to simply pick one of these frameworks and learn it (you don't have to, but most companies use one of them or one like them).
If you are making simpler websites or are just curious to learn the DOM API, there are lots of guides to plain JavaScript DOM manipulation, like this one by MDN.
Conclusion
Let's recap the key points:
- The DOM is an API provided by browsers. The browser's rendering engine models your HTML document as a document tree and allows you to interact with it.
- The browser window is the global object in the browser's JavaScript engine. This gives you access to the document tree where things on the page are represented as objects, described by interfaces.
- Front end libraries and frameworks can help improve your productivity with the DOM, but you should be aware of why you are using them to ensure you get the best out of them.
Thanks for reading and happy DOM manipulation!
Sources
I cross-reference my sources as much as possible. If you think some information in this article is incorrect, please leave a polite comment or message me with supporting evidence .
* = particularly recommended for further study
- Browser engine - Wikipedia
- JavaScript engine - Wikipedia
- Global object - javascript.info
- Window - MDN
- API - MDN Glossary
- Tree (data structure) - Wikipedia
- What is the Document Object Model? - w3.org
- * Document Object Model (and related pages) - MDN
- * Ryan Seddon: So how does the browser actually render a website | JSConf EU 2015
- How Browsers Work: Behind the scenes of modern web browsers - Tali Garsiel, published at html5rocks.com
Document tree image credit: Birger Eriksson, CC BY-SA 3.0, via Wikimedia Commons (side banner removed)
Original Link: https://dev.to/joshcarvel/properly-understanding-the-dom-2cg0
Dev To
More About this Source Visit Dev To