
An Interest In:
Web News this Week
- April 25, 2024
- April 24, 2024
- April 23, 2024
- April 22, 2024
- April 21, 2024
- April 20, 2024
- April 19, 2024
Some of Our Sources
- Joshua Blankenship
- The Logo Smith
- Six Revisions
- TutsPlus - Design
- Fuel Your Creativity
- Inspiredology
- Web Designer Depot
- My Ink Blog
- Android Headlines
- Dev To
Help Webnuz
Referal links:
A new way of tokenization of Chinese or How to make Chinese full-text search
Today I like to highlight the challenge of search functionality in Chinese. In this article, we will go through the main difficulties of full-text search implementation for CJK languages and how to overcome them with the help of Manticore Search.
Chinese search difficulties
The Chinese language belongs to the so-called CJK language family (Chinese, Japanese, and Korean). They are probably the most complicated languages for full-text search implement as in them word meanings heavily depend on numerous hieroglyphs variations and their sequences and the characters are not split up into words.
Chinese languages specifics:
- Chinese hieroglyphs do not have an upper or lower case. They have only one notion, regardless of the context.
- There is no additional decoration for the letters, as in Arabic, for example.There are no spaces between words in sentences.
So what's the point? To find an exact match in a full-text search, we have to face the challenge of tokenization whose main task is to break down the text into low-level units of values that can be searched by the user.
Tokenization/Segmentation ofChinese
To be more specific, tokenization is the process of turning a meaningful piece of data, a word for example, into a unique identifier called a token that represents a piece of data in the system. In full-text search engines tokens serve as a reference to the original data, but cannot be used to guess those actual values.
In most languages, we use spaces or special characters to divide the text into fragments. However, in Chinese and the other CJK languages, it is not possible due to its morphological properties. However, we still need that to be done. And that process is called segmentation.
In other words for Chinese segmentation is a prerequisite to tokenization.

Here is an example showing the difference between English and Chinese tokenization.
As you see the Chinese sentence is half as short and doesn't have any spaces, commas, and is not even split into words, each word here is represented by a hieroglyphic character or few. Here is a quantitative comparison:
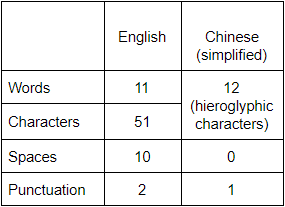
Another challenge is that Chinese hieroglyphs may have different meanings depending on their sequences and combinations. Let's take a look at different meanings of hieroglyphical combinations:

Here we can see the combination of two hieroglyphic characters "" which means "Simplicity", but if we take each of the hieroglyphs separately, they will have different meanings "" (simple) and "" (single).
In some cases, depending on where you put a boundary between the words the meanings may be different. For example:

The problem, as you can see, is that a group of characters can be segmented differently, resulting in different values.
Let's look at possible ways of solving the Chinese tokenization/segmentation problems.
Implementations
There are a few approaches for Chinese texts segmentation, but the main two are:
- N-grams: considers the overlapping groups of "N" neighboring Chinese characters as tokens, where "N" could be 1-Uni; 2-Bi; 3- Tri; and so on "-grams".
- Dictionary-based: performs word segmentation based on a dictionary.
The easiest way of Chinese text segmentation assumes the use of N-grams. The algorithm is straightforward, but it is known to lack in quality and gives considerable overhead that grows with the length of the text being processed because each N-gram is a separate token which makes the tokens dictionary bigger and processing a search query much more complicated. It historically was the common way of CJK texts indexation in Manticore Search.
In Manticore Search version 3.1.0 was introduced a new way of segmentation of Chinese texts based on the ICU text segmentation algorithm which follows the second approach-dictionary-based segmentation.
Benefits of usingICU
ICU is a set of open-source libraries providing Unicode and Globalization support for software applications. Along with many other features, it solves the task of text boundaries' determination. ICU algorithms locate positions of words, sentences, paragraphs within a range of text, or identify locations that would be suitable for line wrapping when displaying the text.
The algorithm of how the ICU segmentation works in Manticore can be briefly described as follows:
- The original text is regarded as an array of symbols.
- Then Manticore goes through the array and if it finds a set of * Chinese symbols it passes that along to the ICU library to process them.
- The segmented parts of the Chinese text replace the original, unsegmented parts.
- Other natural language processing algorithms (charset_table, wordforms, etc.) are applied to the modified text like in a common segmentation workflow.
To enable the ICU-Chinese segmentation, the following index configuration options must be set:
- morphology = icu_chinese
- charset_table = cjk / chinese
An example of configuring ICU-Chinese text tokenization
Index configuration
To set up an index for proper Chinese segmentation there are 2 index settings we need to touch: 'charset_table' and 'morphology'.
For the charset table, there is a built-in alias 'chinese' which contains all Chinese characters.
First, let's connect to Manticore:
mysql -P 9306 -h0 And create our table:
mysql> CREATE TABLE testrt (title TEXT, content TEXT, gid INT) charset_table = 'chinese' morphology = 'icu_ chinese';Basic usage
Let's insert into the index a simple mixed Chinese-English sentence 'Apple' ('I like Apple computers'):
mysql> INSERT INTO testrt (title, content, gid) VALUES ( 'first record', 'Apple', 1 );To check if our Chinese content is tokenized as expected we can run CALL KEYWORDS against our index:
mysql> call keywords('Apple', 'testrt');+------+-----------+------------+| qpos | tokenized | normalized |+------+-----------+------------+| 1 | | || 2 | | || 3 | | |+------+------ ----+------------+We can see that the Chinese text got broken into 4 words, as expected.
And now let's make a search against our content field with a query phrase 'Apple' ('Apple computers'):
mysql> SELECT * FROM testrt WHERE MATCH ('@content Apple');+---------------------+------+--------------+----------------------+| id | gid | title | content |+---------------------+------+--------------+----------------------+| 5477080993472970753 | 1 | first record | Apple |+---------------------+------+--------------+----------------------+As we see, the search has been successfully executed and we got the expected result despite the fact that both the original sentence and the query phrase we used in this example didn't have any separators between the words.
We can use 'SHOW META' command to see extended information about the query and make sure that our sentence was properly segmented into separate words:
mysql> SHOW META;+---------------+--------+| Variable_name | Value |+---------------+--------+| total | 1 || total_found | 1 || time | 0.199 || keyword[0] | || docs[0] | 1 || hits[0] | 1 |+---------------+--------+We see that our search phrase was indeed split up into 'apple' and '' ('computers') just as we supposed it to be done.
Conclusion
Implementing a Chinese full-text search is not an easy task, but Manticore Search copes with it without any troubles out of the box. So if you need a simple and reliable Chinese search for your service or application, you know what to use. You can also find this article in the form of an interactive course here.
Original Link: https://dev.to/gregdevogo/how-to-make-chinese-full-text-search-2ba9
Dev To
More About this Source Visit Dev To