
An Interest In:
Web News this Week
- March 20, 2024
- March 19, 2024
- March 18, 2024
- March 17, 2024
- March 16, 2024
- March 15, 2024
- March 14, 2024
Some of Our Sources
- Engadget
- Mashable
- Web Designer Wall
- Abduzeedo
- Vandelay Design
- My Ink Blog
- 24 Ways
- Stylized Web
- CSS Tricks
- Web Resource Source
Help Webnuz
Referal links:
Building resilient services at Prime Video with chaos engineering
Large-scale distributed software systems are composed of several individual sub-systems-such as CDNs, load balancers, and databases-and their interactions. These interactions sometimes have unpredictable outcomes caused by unforeseen turbulent events (for example, a network failure). These events can lead to system-wide failures.
Chaos engineering is the discipline of experimenting on a distributed system to build confidence in the systems capability to withstand turbulent events. Chaos engineering requires adopting practices to identify interactions in distributed systems and related failures proactively, and also needs implementing and validating countermeasures. The key to chaos engineering is injecting failure in a controlled manner.
In this post, we present a simple approach for fault injection in systems utilizing Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Elastic Container Service (Amazon ECS), and its integration with a load-testing suite to validate the countermeasures put in place to prevent dependency and resource exhaustion failures. A typical chaos experiment could be generating baseline load (traffic) against the system, adding latency to all network calls to the underlying database, and then validating timeouts and retries. We will explain how to inject such failure (addition of latency to database calls), why validating countermeasures (timeouts and retries) under load is essential, and how to execute it in an Amazon EC2-based system.
We will start with a brief introduction to chaos engineering, then dive deep into failure injection using the AWS Systems Manager. We will then present our open source library, AWSSSMChaosRunner. This was inspired by Adrian Hornsbys Injecting Chaos to Amazon EC2 using AWS System Manager blog post.
Finally, we will provide an example of integration and explain how Prime Video used this library to prevent potentially customer-impacting outages.
Chaos engineering introduction
Software testing commonly involves implementing and automating unit tests, integration tests, and end-to-end tests. Although these tests are critical, they do not encompass the broader spectrum of disruptions possible in a distributed system (e.g., Availability Zone outage, dependency failure, network outage, etc.).
Generally, the behavior of software systems to these scenarios remains unknown. For example, what happens if an Amazon EC2 instance in the service fleet sustains high CPU consumption? Such a situation can occur because of an unexpected increase in traffic or an incorrectly implemented loop in the code. Building confidence in software systems is hard without putting them under stress. Questions to consider:
- Have you tested how the system behaves when the underlying instances have a sustained CPU spike?
- Is the system behavior understood under different stress?
- Is there sufficient monitoring?
- Have the alarms been validated?
- Are there any countermeasures implemented? For example, is auto-scaling set up, and does it behave as expected? Are timeouts and retries appropriate?
As mentioned previously, chaos engineering requires adopting practices to identify interactions in distributed systems and related failures proactively, and also needs implementing and validating countermeasures. These can be implemented using chaos engineering experiments.
Typical chaos engineering experiments are:
- Resource exhaustion : For example, exhaustion of CPU, virtual memory, disk space, and so on. These failures occur frequently and are often caused by failed deployments, memory leaks, or unexpected traffic spikes. Chaos experiments that control resource exhaustion verify that there is sufficient monitoring to detect such failures and proper countermeasures (for example, auto-scaling, auto-restart, etc.) for the system to recover automatically.
- Failing or slow network dependency : For example, a database accessed over the network is slow to respond, or its failure rate is high. These failures can happen when the network is experiencing intermittent issues or when dependencies are in a degraded state. Timeouts, retry policies, and circuit breakers are typical countermeasures to these failures; however, they are rarely adequately tested, as unit or integration tests generally cant validate them with high confidence. Chaos experiments that inject latency or faults in the dependency code path are good at proving the countermeasures effectiveness-timeouts, retries, and circuit breakers.
For a more in-depth review of chaos engineering, please see the resources at the end of this article.
AWSSSMChaosRunner: Library for failure injection using AWS Systems Manager
Next, lets review essential AWS Systems Manager concepts: the AWS Systems Manager Agent (SSM Agent), the SendCommand API, and the AWS Systems Manager documents.
AWS Systems Manager
AWS Systems Manager is a service used to view operational data from multiple AWS services and to automate operational tasks across your AWS resources. A full list of Systems Manager capabilities can be found in the user guide.
For Amazon EC2 instances, AWS Systems Manager offers the SSM Agent to perform actions inside instances or servers. This capability is generally used on most Amazon EC2 instances for operating system patching and for managing SSH sessions.
AWS Systems Manager Agent
SSM Agent is open source Amazon software, released under the Apache License 2.0, that can be installed and configured on an Amazon EC2 instance. SSM Agent makes it possible for Systems Manager to update, manage, and configure these resources. SSM Agent is preinstalled by default on instances created from the following Amazon Machine Images (AMIs): Windows Server 20082012 R2 AMIs published in November 2016 or later, Windows Server 2016 and 2019, Amazon Linux, Amazon Linux 2, Ubuntu Server 16.04, Ubuntu Server 18.04, and Amazon ECS-Optimized.
For installation and configuration instructions, refer to the user guide.
SendCommand API
AWS SSM SendCommand API enables running commands programmatically on one or more instances through the SSM Agent.
Example : Hello, World! SendCommand using the AWS CLI
- The specified instance, instanceid=i-1234567890abcdef0, will run "echo Hello, World!" as a shell script. Targets can be used to specify single instances or groups of instances by using instance tags (for example, Auto Scaling group).
- The SendCommand execution will time out in 10 seconds.
- Any logs from the command will be sent to the CloudWatch log group named test.
aws ssm send-command \ --document-name "AWS-RunShellScript" \ --parameters 'commands=["echo Hello, World!"]' \ --targets "Key=instanceids,Values=i-1234567890abcdef0" \ --comment "echo Hello, World!" --timeout-seconds 10 --cloud-watch-output-config "CloudWatchOutputEnabled=true,CloudWatchLogGroupName=test"SSM command documents
AWS Systems Manager document (SSM document) can be used to specify complex commands in the form of shell scripts to be executed on an instance or groups of instances. You can run SSM documents via the AWS Systems Manager console or the SendCommand API.
Example : An SSM document for black hole routing all outgoing traffic on a given UDP or TCP port
- This document is specified in YAML format, but also can be specified with JSON.
- Command parameters are defined separately, as variables.
- action: aws:runShellScript specifies that the steps (mainSteps) are a part of a shell script.
---schemaVersion: '2.2'description: Blackhole a protocol/port on an instanceparameters: prtl: type: String description: Specify the protocol to blackhole. (Required) allowedValues: - tcp - udp port: type: String description: Specify the port to blackhole. (Required) duration: type: String description: The duration - in seconds - of the blackhole. (Required) default: "60"mainSteps:- action: aws:runShellScript name: ChaosBlackholeAttack inputs: runCommand: - iptables -A OUTPUT -p {{ prtl }} --dport {{ port }} -j DROP - sleep {{ duration }} - iptables -D OUTPUT -p {{ prtl }} --dport {{ port }} -j DROPAWSSSMChaosRunner
Assuming that SSM Agent is installed on the Amazon EC2 instances and configured with correct permissions, AWS Systems Manager can be used for failure injection on Amazon EC2 instances in the following way:
- Create the SSM document via the AWS Systems Manager Console or the AWS CLI.
- The shell script included in the SSM document must be executable on the underlying instances.
2. Call the SSM SendCommand API via the AWS Systems Manager Console or the AWS CLI.
- The Amazon EC2 fleet can be defined by using appropriate tags to the target parameter.
- The parameters of the underlying shell script must be specified (duration/port/protocol in the above example).
- The CloudWatch log group must be configured and specified to view logs from the whole Amazon EC2 fleet in a single location.
If the above steps are successful, all specified Amazon EC2 hosts will be injecting failure. For example, EC2 hosts will black-hole outgoing traffic to a given UDP/TCP port. However, no requests may be hitting the service you are injecting failure into; either it is a period of low traffic or a development fleet. In which case, the effect of the failure injection might be minimal, or worse, not perceived at all. Thus, it will be difficult to validate the countermeasures put in place. A third step is needed.
3. Generate traffic to the service using load generators to simulate real-life high traffic on the system.
Running the above steps manually is prone to configuration errors, is risky, and is time consuming. These steps can be automated with the recently released AWSSSMChaosRunner library, as illustrated in the image below.
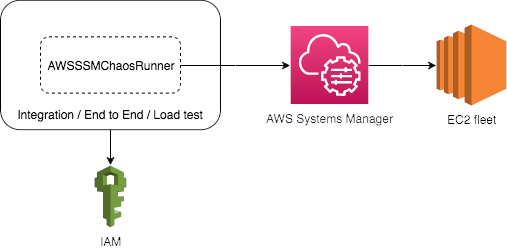
This library abstracts the creation of SSM documents and calling the SSM SendCommand, and provides tried and tested SSM documents for your chaos experiments. This library is open sourced under the Apache-2.0 License and is available on GitHub and Maven Central.
Failure injections
The failure injections currently available in the AWSSSMChaosRunner library are:
- NetworkInterfaceLatency : Adds latency to all inbound/outbound calls to a given network interface.
- DependencyLatency : Adds latency to inbound/outbound calls to a given external dependency.
- DependencyPacketLossAttack: Drops packets on inbound/outbound calls to a given external dependency.
- MemoryHog: Hogs virtual memory on the fleet.
- CPUHog: Hogs CPU on the fleet.
- DiskHog: Hogs disk space on the fleet.
- AWSServiceLatencyAttack: Adds latency to an AWS service using the CIDR ranges returned from ip-ranges.amazonaws.com. This is necessary for services like such as Amazon Simple Storage Service (Amazon S3) or Amazon DynamoDB, where the resolved IP address can change during the chaos experiment.
- AWSServicePacketLossAttack: Drops packets to an AWS service using the CIDR ranges returned from ip-ranges.amazonaws.com. This is necessary for services like Amazon S3 or Amazon DynamoDB, where the resolved IP address can change during the chaos experiment.
- MultiIPAddressLatencyAttack: Adds latencies to all calls to a list of IPAddress. This could be useful for a router host kind of a setup.
- MultiIPAddressPacketLossAttack: Drops packets from all calls to a list of IPAddress. This could be useful for a router host kind of a setup.
Chaos testing an EC2 service
Take, for example, a service running in Amazon EC2. (Commonly recommended components, such as CDNs, load balancers, and VPCs have been omitted for simplification).

This service receives client requests, applies business logic, and accesses a database (or any external dependency). Lets learn how to apply the AWSSSMChaosRunner library to this service.
Prerequisites
- Familiarity with IAM concepts, such as IAM policies, roles, and users.
- Tests for the service are written in Java, Kotlin, or Scala. AWSSSMChaosRunner library is only available for these languages.
- Service health and behavior must be instrumented and monitored with metrics or logs. Without monitoring, the effect of failure injections can not be observed.
- Some baseline traffic (load) is generated to the service from the tests while the chaos experiment is executed. Generating traffic will help validate the experiment hypothesis.
Step 1. Set up permissions for calling AWS Systems Manager from the tests package.
Although implementing this part in different ways is possible, the approach described here generates temporary credentials for AWS Systems Manager on each run of the tests.
First you must create an IAM user and an IAM role it can assume. The following IAM policy must be attached to this role.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "sts:AssumeRole", "ssm:CancelCommand", "ssm:CreateDocument", "ssm:DeleteDocument", "ssm:DescribeDocument", "ssm:DescribeInstanceInformation", "ssm:DescribeDocumentParameters", "ssm:DescribeInstanceProperties", "ssm:GetDocument", "ssm:ListTagsForResource", "ssm:ListDocuments", "ssm:ListDocumentVersions", "ssm:SendCommand" ], "Resource": [ "\*" ], "Effect": "Allow" }, { "Action": [ "ec2:DescribeInstances", "iam:PassRole", "iam:ListRoles" ], "Resource": [ "\*" ], "Effect": "Allow" }, { "Action": [ "ssm:StopAutomationExecution", "ssm:StartAutomationExecution", "ssm:DescribeAutomationExecutions", "ssm:GetAutomationExecution" ], "Resource": [ "\*" ], "Effect": "Allow" } ]}Step 2. Initialize the AWS Systems Manager client.
This code should be invoked during the initialization of the tests (i.e., wherever the singletons are created).
//Kotlin@Beanopen fun awsSecurityTokenService( credentialsProvider: AWSCredentialsProvider, awsRegion: String ): AWSSecurityTokenService { return AWSSecurityTokenServiceClientBuilder.standard() .withCredentials(credentialsProvider) .withRegion(awsRegion) .build()}@Beanopen fun awsSimpleSystemsManagement( securityTokenService: AWSSecurityTokenService, awsAccountId: String, chaosRunnerRoleName: String ): AWSSimpleSystemsManagement { val chaosRunnerRoleArn = "arn:aws:iam::$awsAccountId:role/$chaosRunnerRoleName" val credentialsProvider = STSAssumeRoleSessionCredentialsProvider .Builder(chaosRunnerRoleArn, "ChaosRunnerSession") .withStsClient(securityTokenService).build() return AWSSimpleSystemsManagementClientBuilder.standard() .withCredentials(credentialsProvider) .build()}Step 3. Start the fault injection attack before starting the test, and stop it after the test.
The given test sends traffic to the service.
//Kotlin@Beforeoverride fun initialise(args: Array) { if (shouldExecuteChaosRunner()) { ssm = applicationContext.getBean(AWSSimpleSystemsManagement::class.java) ssmAttack = getAttack(ssm, attackConfiguration) command = ssmAttack.start() }}@Testfun `given failure injection generate calls to the service`(int: duration) { // This test should call an endpoint of the service and keep repeating this for the duration of the test. // Additional logging can be added or service dashboards can be monitored for an overview. val startTime = LocalDateTime.now() while(getElapsedSeconds(startTime) <= duration){ serviceClient.callEndpoint() }}@Afteroverride fun destroy() { ssmAttack.stop(command)}Step 4. Run the test.
Execute the command to run the above test.
Note: AWSSSMChaosRunner can also be used for an EC2+ECS based service with one setup step prior to the above steps. Please see the Github README for more details.
Prime Video uses AWSSSMChaosRunner to prevent a potential outage
In March 2020 Prime Video launched Prime Video profiles which lets Prime Video users access separate recommendations, season progress, and Watchlist, as these are based on individual profile activity. This new customer experience required the design and implementation of new services using Amazon EC2.
 Prime Video Profiles
Prime Video Profiles
These services are part of a distributed system, and they call other internal Amazon services over the network. Testing the timeouts, retries, and circuit-breaker configurations used by this service was considered critical because:
- These code paths are hard to validate through unit, integration, and end-to-end tests.
- Issues in configurations are usually discovered during an outage when these countermeasures-timeouts, retries, and circuit breaker-would be needed.
Prime Video implemented this chaos engineering experiment using the AWSSSMChaosRunners DependencyLatency attack, and by generating load against the service, thus simulating traffic when dependencies exhibit high latency.
The service-to-service call metrics were observed and, as a result, timeouts, retries, and circuit-breaker configuration were validated.
Now lets review the result of one of these chaos experiments and find out how it helped us proactively discover a potentially customer-impacting issue.
Experiment: Validate ElastiCache timeout
The chaos experiment is set up as follows:
- Experiment hypothesis : The timeout for Service ElastiCache call is set as 40 milliseconds. This will be validated by observing the Service ElastiCache latency metric during the experiment.
- Failure injection : Two seconds of latency is added to the Service ElastiCache call using AWSSSMChaosRunner.
- Generate baseline load against the service : 1000 requests per second are generated against the service. As discussed previously, running chaos engineering experiments while loading the system is critical.
Experiment outcome

The above image shows that the Service ElastiCache latency is going beyond the configured 40ms timeout. Thus, the ElastiCache timeout configuration is failing.
Following these results, we fixed a bug in the timeout configuration.
To validate our fix, we subsequently re-run the same experiment.

The illustration shows that the maximum of Service ElastiCache latency is capped at 40 milliseconds, the configured timeout value. This happens despite the extra latency of two seconds injected into this call path by the experiment. This result validates that the service will time out quickly if ElastiCache is slow to respond or if that network path has some issue.
Running this chaos experiment led to the discovery of a bug in the countermeasure for dependency degradation (i.e., ElastiCache timeout). The bug fix prevented a potential customer-impacting failure from happening.
Conclusion
Testing service dependency timeouts, retries, and circuit-breaker configurations is essential. In this post, we presented an open source approach to failure injection on Amazon EC2 using AWS Systems Manager, and we demonstrated how Prime Video combines it with load testing to achieve higher levels of resiliency. This Prime Video case study shows how chaos engineering helps prevent potentially customer-impacting issues that are difficult to pinpoint using traditional testing methods.
Resources
- PrinciplesOfChaos.org
- Chaos Engineering: The art of breaking things purposefully blog collection on Medium
- Awesome chaos engineering collection of reading resources on GitHub
Originally published at https://aws.amazon.com on August 18, 2020.
Original Link: https://dev.to/aws/building-resilient-services-at-prime-video-with-chaos-engineering-2hka
Dev To
More About this Source Visit Dev To