
An Interest In:
Web News this Week
- April 1, 2024
- March 31, 2024
- March 30, 2024
- March 29, 2024
- March 28, 2024
- March 27, 2024
- March 26, 2024
Some of Our Sources
- Slashdot
- Mashable
- Team Treehouse
- Spoon Graphics
- Creative Curio
- Naldz Graphics
- My Ink Blog
- 24 Ways
- Design Modo
- Daily Now
Help Webnuz
Referal links:
Scrape sever-side rendered HTML content with JavaScript
Scraping can be used to collect and analyse data from sources that dont have APIs.
In this tutorial well scrape content using JavaScript from a website thats rendered server-side.
Youll need to have Node.js and npm installed if you havent already.
Lets start by creating a project folder and initialising it with a package.json file:
mkdir scrapernpm init -yWell be using two packages to build our scraper script.
- axios Promise based HTTP client for the browser and node.js.
- cheerio Implementation of jQuery designed for the server (makes it easy to work with the DOM).
Install the packages by running the following command:
npm install axios cheerio --saveNext create a file called scrape.js and include the packages we just installed:
const axios = require("axios");const cheerio = require("cheerio");In this example ill be using https://lobste.rs/ as the data source to be scraped.
Inspecting the code the site name in the header has a cur_url class so lets see if we can scrape its text:
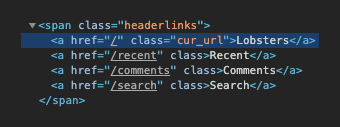
Add the following to scrape.js to fetch the HTML and log the title text if successful:
axios('https://lobste.rs/') .then((response) => { const html = response.data; const $ = cheerio.load(html); const title = $(".cur_url").text(); console.log(title); }) .catch(console.error);Run the script with the following command and you should see Lobsters logged in the terminal:
node scrape.jsIf everythings working we can proceed to scrape some actual content from the website.
Lets get the titles, domains and points for each of the stories on the homepage by updating scrape.js:
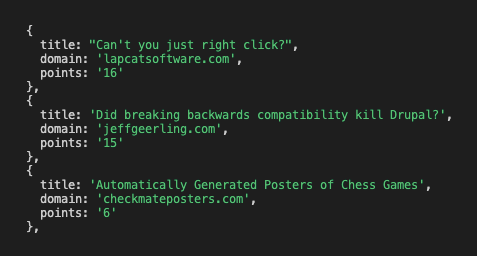
axios("https://lobste.rs/") .then((response) => { const html = response.data; const $ = cheerio.load(html); const storyItem = $(".story"); const stories = []; storyItem.each(function () { const title = $(this).find(".u-url").text(); const domain = $(this).find(".domain").text(); const points = $(this).find(".score").text(); stories.push({ title, domain, points, }); }); console.log(stories); }) .catch(console.error);This code loops through each of the stories, grabs the data, and then stores it in an array called stories.
If youve worked with jQuery then the selectors will be familiar, if not you can learn about them here.
Now re-run node scrape.js and you should see the data for each of the stories:
Original Link: https://dev.to/michaelburrows/scrape-sever-side-rendered-html-content-with-javascript-24bi
Dev To
More About this Source Visit Dev To