
An Interest In:
Web News this Week
- April 18, 2024
- April 17, 2024
- April 16, 2024
- April 15, 2024
- April 14, 2024
- April 13, 2024
- April 12, 2024
Some of Our Sources
- Slashdot
- Simplebits
- Joshua Blankenship
- Smashing Magazine
- Naldz Graphics
- Crazy Leaf Design
- Line 25
- Stylized Web
- Web Resource Source
- Codrops
Help Webnuz
Referal links:
WebScraping [Part-1]
 aletisunil / Scraping_IMDB
aletisunil / Scraping_IMDB
Scrapes the movie title, year, ratings, genre, votes
Hey everyone,
You doesn't need to be a guru in python, just a basics of HTML and python is sufficient for this web scraping tutorial.
Let's dive in..
The tools we're going to use are:
- Request will allow us to send HTTP requests to get HTML files
- BeautifulSoup will help us parse the HTML files
- Pandas will help us assemble the data into a DataFrame to clean and analyze it
- csv(optional)- If you want to share data in csv file format
Let's Begin..
In this tutorial, we're going to scrape IMDB website, which we can get title, year, ratings, genre etc..
First, we'll import the tools to build our scraper
import requestsfrom bs4 import BeautifulSoupimport pandas as pdimport csvGetting the contents of webpage into results variable
url = "https://www.imdb.com/search/title/?groups=top_1000"results = requests.get(url)In order to make content easy to understand, we are using BeautifulSoup and the content is stored in soup variable
soup = BeautifulSoup(results.text, "html.parser")And now initializing the lists to store data
titles = [] #Stores the title of movieyears = [] #Stores the launch year of the movietime = [] #Stores movie durationimdb_ratings = [] #Stores the rating of the moviegenre = [] #Stores details regarding genre of the movievotes = [] #Store the no.of votes for the movieNow find the right movie container by inspecting it, and hover over the movie div, which looks like below image

And we can see 50 div with class names:lister-item mode-advanced
So, find all div's with that classname by
movie_div = soup.find_all("div", class_="lister-item mode-advanced")find_all attribute extracts all the div's which has class
name:"lister-item mode-advanced"
Now get into each lister-item mode-advanced div and get the title, year, ratings, genre, movie duration
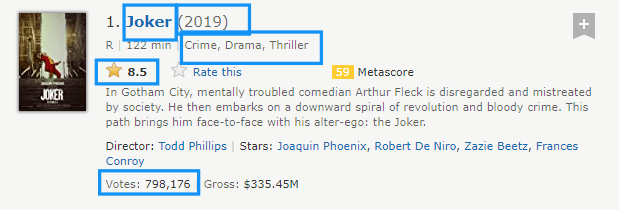
So we iterate every div to get title, year, ratings etc..
for movieSection in movie_div:Extracting the title

From image, we can see that the movie name is placed under div>h3>a
name = movieSection.h3.a.text #we're iterating those divs using <b>movieSection<b> variabletitles.append(name) #appending the movie names into <b>titles</b> list Extracting Year
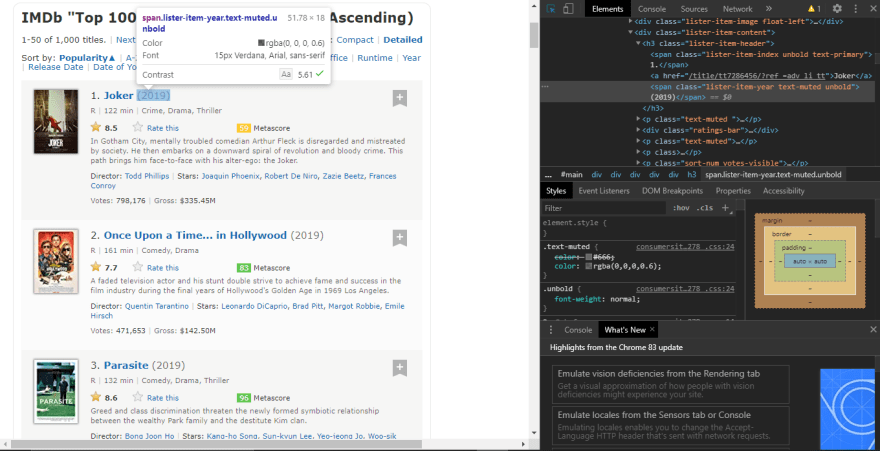
From image, we can see that the movie launch year is placed under div>h3>span(class name="lister-item-year") and we extract it using text keyword
year = movieSection.h3.find("span", class_="lister-item-year").textyears.append(year) #appending into years listSimilarly, we can get ratings, genre, movieDuration w.r.t classname
ratings = movieSection.strong.textimdb_ratings.append(ratings) #appending ratings into listcategory = movieSection.find("span", class_="genre").text.strip()genre.append(category) #appending category into Genre listrunTime = movieSection.find("span", class_="runtime").texttime.append(runTime) #appending runTime into time listExtracting votes

As from the image, we can see that we have two span tags with classname="nv". So, for votings we need to consider nv[0] and for gross collections nv[1]
nv = movieSection.find_all("span", attrs={"name": "nv"})vote = nv[0].textvotes.append(vote)Now we will build a DataFrame with pandas
To store the data we have to create nicely into a table, so that we can really understand
And we can do it..
movies = pd.DataFrame( { "Movie": titles, "Year": years, "RunTime": time, "imdb": imdb_ratings, "Genre": genre, "votes": votes, })And now let's print the dataframe

As we can see on row 16 and 25, there is some inconsistent of data. So we need to clean
movies["Year"] = movies["Year"].str.extract("(\\d+)").astype(int) #Extracting only numerical values. so we can commit "I" movies["RunTime"] = movies["RunTime"].str.replace("min", "minutes") #replacing <b>min</b> with <b>minutes</b> movies["votes"] = movies["votes"].str.replace(",", "").astype(int) #removing "," to make it more clearAnd now after cleaning we will see, how it looks
print(movies)
You can also export the data in .csv file format.
In order to export,
Create a file with .csv file extension
movies.to_csv(r"C:\Users\Aleti Sunil\Downloads\movies.csv", index=False, header=True)
You can get Final code from my Github repo
In my next part, Ill explain how to loop through all of the pages of this IMDb list to grab all of the 1,000 movies, which will involve a few alterations to the final code we have here
Hope it's useful
A would be Awesome
HappyCoding
Original Link: https://dev.to/aletisunil/demystify-the-webscraping-part-1-3d5c
Dev To
More About this Source Visit Dev To